

AI is increasingly becoming part of everyday life across various domains. For the uninitiated, AI which stands for Artificial Intelligence, is a branch of computer science that explores the process of building intelligent machines that can perform cognitive tasks such as thinking, perceiving, learning, problem-solving, and decision-making. Machine Learning (ML) is a subset of AI. It makes use of algorithms and data to develop models that can make decisions and predictions and perform tasks without explicit instructions.
SQL Server supports Machine Learning through a feature called Machine Learning Services. Through this feature, developers can execute machine learning logic written in Python and R programming languages on data present in SQL Server databases. Machine Learning Services also enable you to work with Azure Data Studio notebooks to develop and execute Python and R scripts.
Although both these languages are supported, for this article, we shall consider only Python. It is open-source with a relatively easy learning curve. Python also provides several libraries and packages supporting ML tasks, such as scikit-learn, TensorFlow, and PyTorch. Through this article, you will explore how to create and run Python scripts to perform machine learning tasks in an SQL Server environment.
Getting Started
Here is an overview of steps to get started with the Machine Learning Services:
- Ensure you have SQL Server 2022 Machine Learning Services installed.
- Install Python.
- Install additional Python packages and libraries necessary for machine learning.
- Configure Python runtime with SQL Server 2022.
- Configure Azure Data Studio.
- Prepare and run your scripts.
SQL Server 2022 Machine Learning Services
Machine Learning features will not be available with an Express edition so your SQL Server edition can be any edition except Express. If you do not have SQL Server 2022 Machine Learning (ML) Services, run setup.exe of SQL Server 2022 to install it. Select Add features to an existing instance of SQL Server 2022 and on the Feature Selection page, under Database Engine Services, click the Machine Learning Services and Language check box.
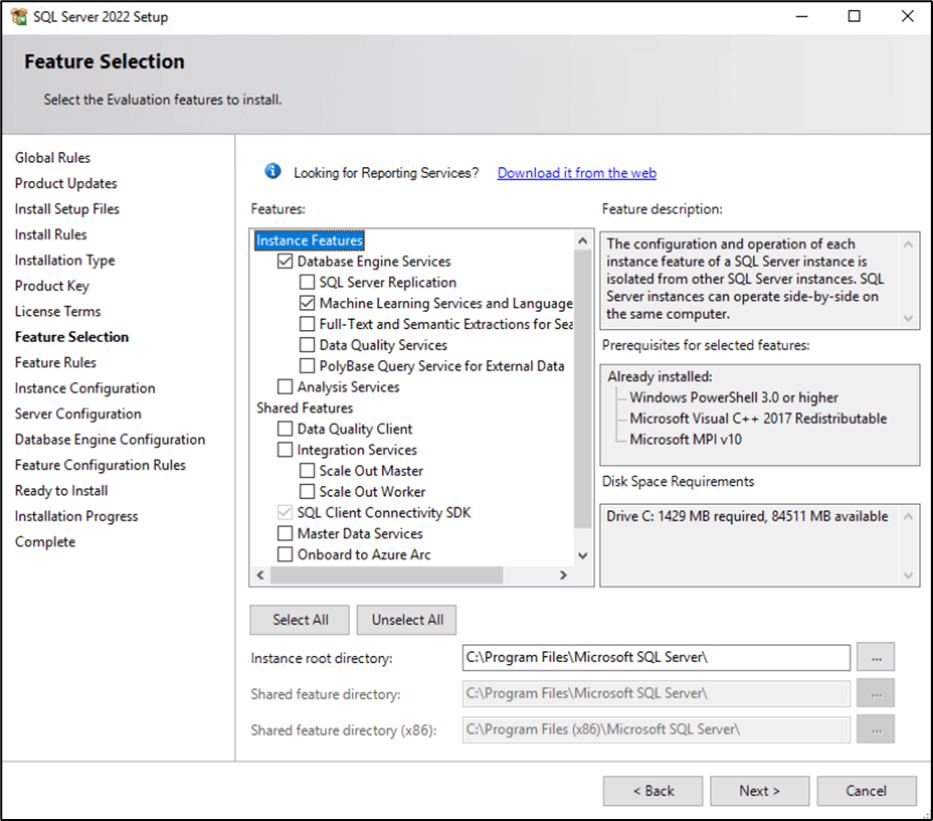
Figure 1: Feature Selection Page
SQL Server 2022 ML Services comes with an Extensibility Framework that facilitates SQL Server to execute external scripts including Python code. It also contains required libraries for integrating with open-source packages such as PyTorch, TensorFlow, and scikit-learn.
Install Python and Additional Python Packages
Beginning with SQL Server 2022 (16.x), runtimes for Python is no longer installed with SQL Setup. So, you must now install Python runtime and then, configure that Python runtime with SQL Server. Although 3.12 is the latest stable version of Python, be sure to install only 3.10 because some of the Machine Learning support is restricted to work only with this version only as of now.
Download Python 3.10 for Windows from the archives at the URL: https://www.python.org/downloads/windows/
Download the executable file for Python 3.10.0.
To start the setup process, run the downloaded executable file. You may customize the installation as per your requirements. You will now have to install separately additional packages and runtimes essential for machine learning with Python. These include:
- pandas: Essential for data manipulation and analysis. It provides data structures such as DataFrames, Series, and Index objects for handling data.
- patsy: Used for specifying design matrices for statistical models.
- dill: Required for efficient serialization of Python objects such as functions, classes, and models.
- numpy: Used for fast numerical operations and array manipulations in Python.
- revoscalepy: Is a Python library that provides distributed computing capabilities for data analysis and ML tasks. It offers functions that help to import, transform, and manipulate data.
Open the Command Prompt and navigate to the installation folder. Download and install dill, numpy, pandas, patsy, and python-dateutil. For this article, I have used dill 0.3.7, numpy 1.26.2, pandas 2.2.0, patsy 0.5.6, and pyodbc 5.0.1. You may choose to perform the installation using pip or conda.
Also, download and install the revoscalepy package and its dependencies, by typing below commands at the command prompt.
Cd C:\Python310\Lib\site-packages C:\Python310\python.exe –m pip install https://aka.ms/sqlml/python3.10/windows/revoscalepy-10.0.1-py3-none-any.whl
To grant the READ and EXECUTE access for the installed libraries to SQL Server Launchpad Service and all the application site packages, at the command prompt, type the following icacls commands: (ensure that you replace the bolded section with your own SQL Server instance name)
icacls "C:\Python310\Lib\site-packages" /grant "NT Service\MSSQLLaunchpad$SQLDEVL":(OI)(CI)RX /T icacls "C:\Python310\Lib\site-packages" /grant *S-1-15-2-1:(OI)(CI)RX /T icacls . /grant *S-1-15-2-1:(OI)(CI)RX /T icacls . /grant "NT Service\MSSQLLaunchpad$SQLDEVL":(OI)(CI)RX /T
Configure Python Runtime with SQL Server 2022
It's not just enough to install SQL Server 2022 Machine Learning Services and Python but crucial to have them work together. For the ML services to recognize the installed Python runtime, we must now use a command RegisterRext.
Open a Command Prompt and navigate to the RxLibs folder using the command similar to this one: C:\Python310\Lib\site-packages\revoscalepy\rxLibs
RegisterRext.exe command-line utility under this path is used to change the default version of the installed runtime. Execute the RegisterRext command, assuming the instance name is SQLDEVL:
.\RegisterRext.exe /configure /pythonhome:"C:\Python310" /instance:"SQLDEVL"
This informs your SQL Server instance to use the installed Python runtime instead of the default runtime.
Configure Azure Data Studio
You can use SQL Server Management Studio or Azure Data Studio to create and run Python based machine learning scripts. For this article, we shall use Azure Data Studio. Open Azure Data Studio by clicking Start à Azure Data Studio à Azure Data Studio.
In the Azure Data Studio page, click Create a connection to create a connection to the database instance. See Figure 2.
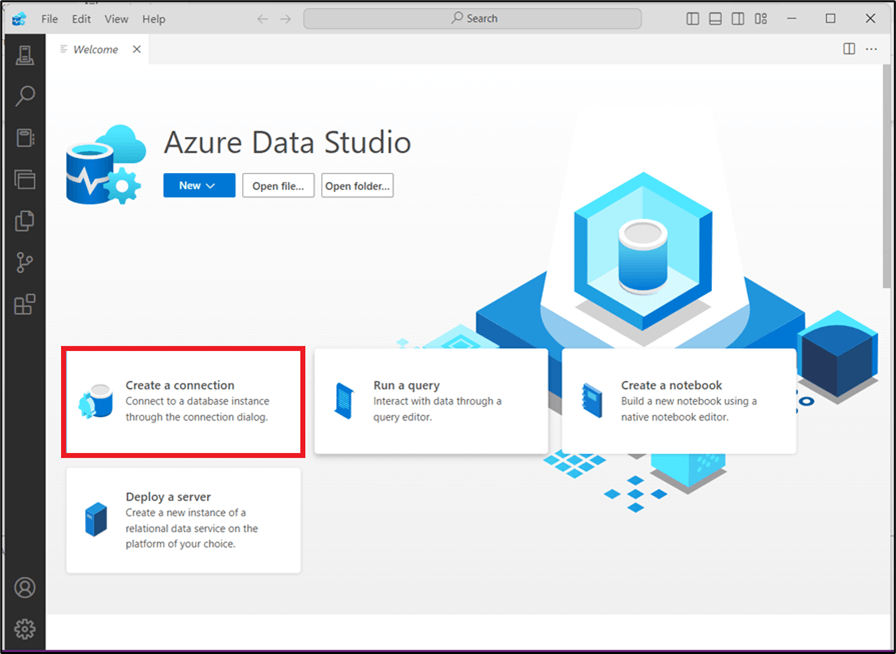
Figure 2: Azure Data Studio Page
Provide the connection details, on the Connection Details page, in the Server box, type the server name. Set the authentication type by clicking the Authentication type drop-down list and selecting appropriate authentication. Click Connect. See Figure 3.
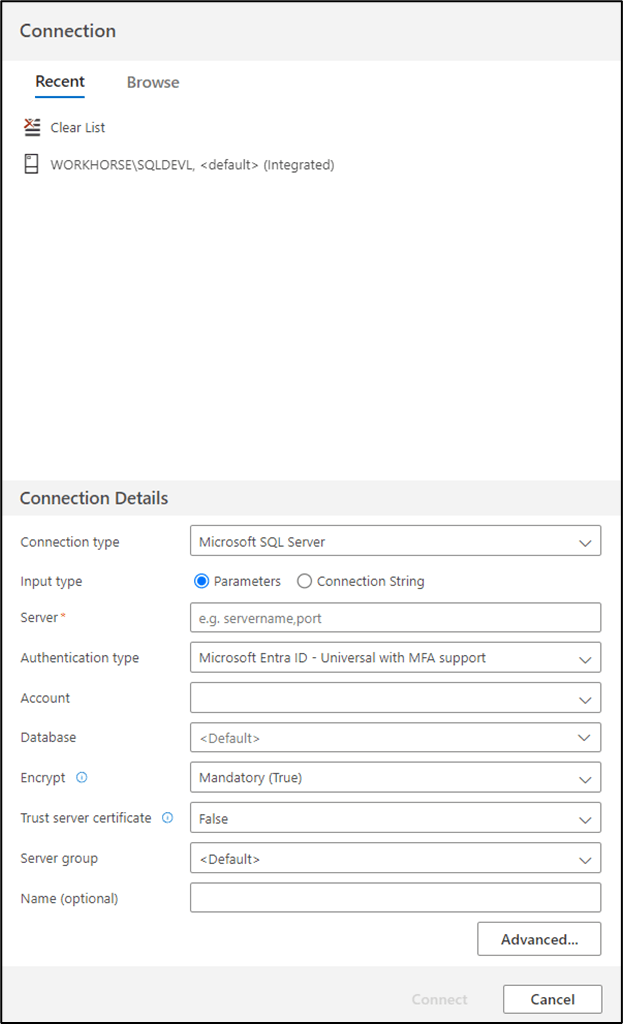
Figure 3: Connection and Connection Details Page
You may receive a Connection error. To resolve this, click Enable Trust server certificate and enable the trust server certificate. See Figure 4.
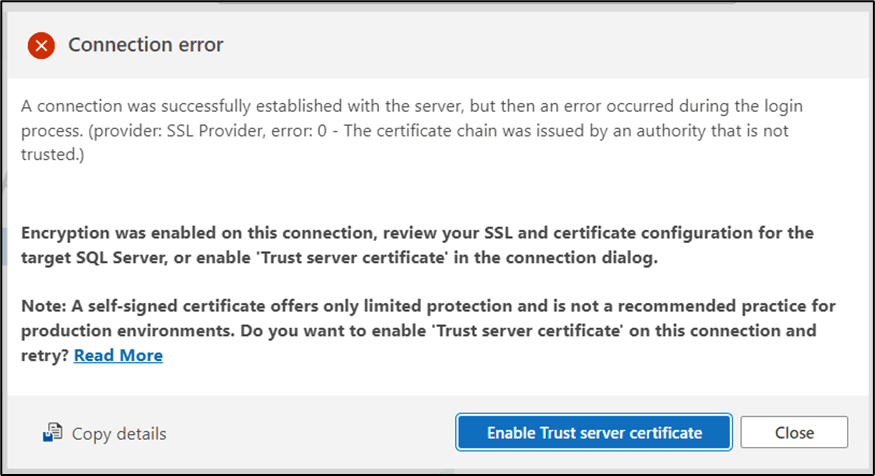
Figure 4: Connection error Page
A new connection to the SQL Server will be established. Click the Welcome tab at the top left corner to go back to the home page of Azure Data Studio.
You will need to interact with the database data through a query editor. So, on the Azure Data Studio page, click Run a query as shown in Figure 7.
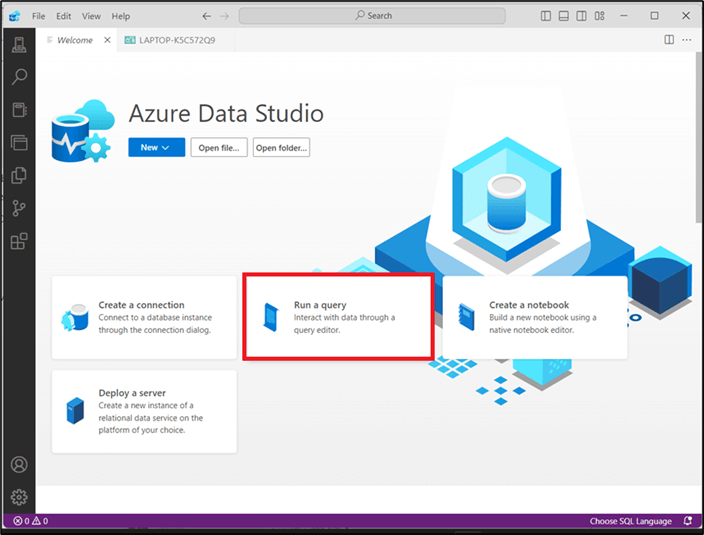
Figure 5: Run a Query Option - Azure Data Studio Page
Python scripts are considered as external scripts and won't run by default in the query editor.
The external scripting feature must be enabled to allow this. In the query editor, type following commands:
EXEC sp_configure 'external scripts enabled',1; RECONFIGURE WITH OVERRIDE
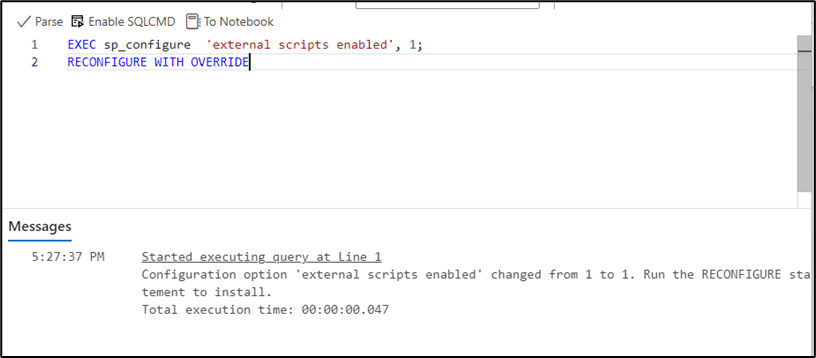
Figure 6: Enabling External Scripts
Verify successful execution of the query by confirming that the values for config_value and run_value are displayed as 1, respectively. See Figure 7.
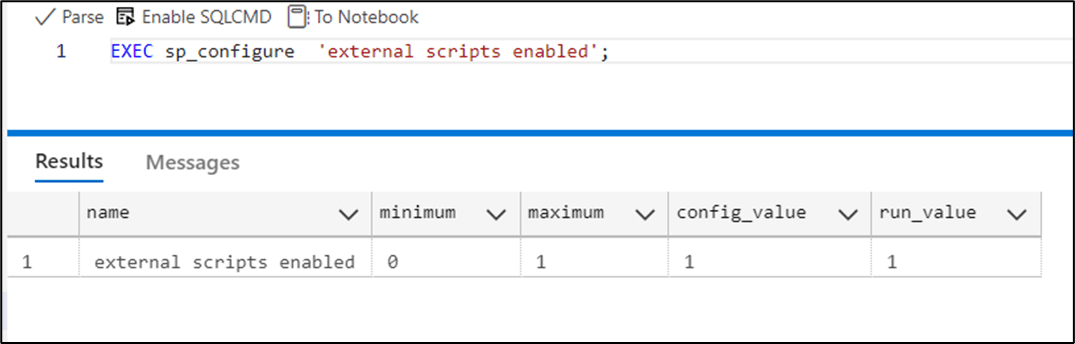
Figure 7: Results Page
Restart the SQL Server service. Open Services in the Control Panel, right-click SQL Server (MSSQLSERVER), and from the context menu, click Restart as shown in Figure 8. Restarting the SQL Server service automatically restarts the related SQL Server Launchpad service.
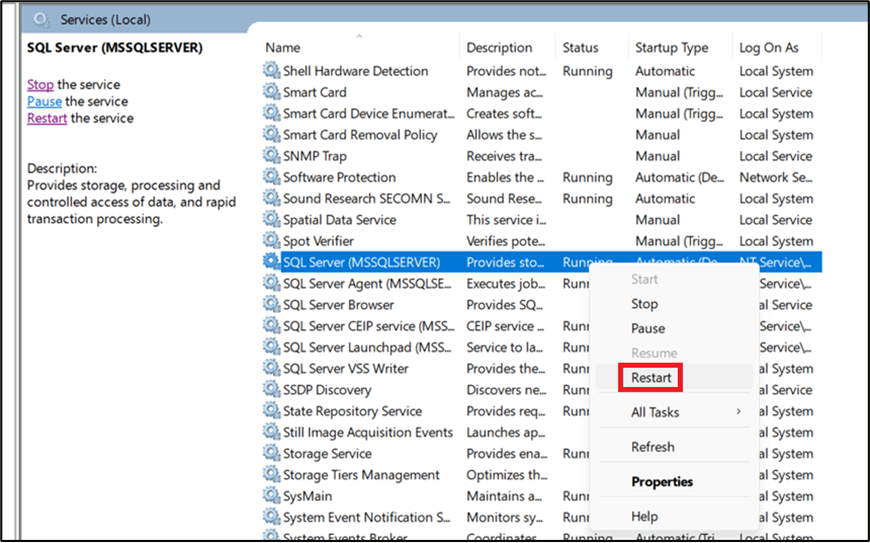
Figure 8: Services Window
Test a simple Python script installation, in the query editor, type a script like the one below and execute it.
EXEC sp_execute_external_script @script=N 'import sys;print(sys.version) ', @language=N 'Python' GO
This script displays the version of Python installed. See Figure 9.
Figure 9: Testing a Python Script Execution
Now you are all ready to start writing machine learning scripts to work on SQL Server data.
Applying SQL Server Machine Learning and Linear Regression for Data Prediction
Linear regression in statistics is a method that depicts the relationship between dependent and independent variables. In Machine Learning, linear regression is a type of Machine Learning algorithm used to predict future values based on actual values. The training data on which this algorithm will be applied comprises past observations. These observations include the observed attributes or features of the item being observed, and the known value of the item you want to train a model to predict (called as the label).
Here are some links to get more familiar with this concept:
- https://machinelearningmastery.com/linear-regression-for-machine-learning/
- https://towardsdatascience.com/introduction-to-machine-learning-algorithms-linear-regression-14c4e325882a
As this link says, "The study of linear regression is a very deep topic: there's a ton of different things to talk about and we'd be foolish to try to cover them all in one single article", https://mlu-explain.github.io/linear-regression/
So what we'll do is, we look at an oversimplified example just to understand how this works with SQL Server. A movie hall runs two kinds of shows each week - morning show and evening show. The manager wants to estimate ticket sales for an upcoming week based on ticket sales this week. Let's see how machine learning and linear regression might possibly give some clue regarding this.
To begin with, we increase the memory pool size because ML operations can be memory intensive and SQL Server or Azure Data Studio can cause memory errors and terminate processing.
ALTER EXTERNAL RESOURCE POOL [default]
WITH (
MAX_MEMORY_PERCENT = 95
)
GO
ALTER RESOURCE GOVERNOR RECONFIGURE
GO
We'll create TicketSales table with four fields and 15 rows of data under a database TicketSalesDB. For morning and evening show, we'll use the bit data type to store the data. Let's begin with the database creation.
USE master;
GO
IF NOT EXISTS (
SELECT name
FROM sys.databases
WHERE name = N'TicketSalesDB'
)
CREATE DATABASE [TicketSalesDB];
GO
IF SERVERPROPERTY('ProductVersion') > '12'
ALTER DATABASE [TicketSalesDB] SET QUERY_STORE = ON;
GO
USE TicketSalesDB
GO
-- Create a new table called 'MovieTickets' in schema 'dbo'
-- Drop the table if it already exists
IF OBJECT_ID('dbo.MovieTickets', 'U') IS NOT NULL
DROP TABLE dbo.MovieTickets;
GO
-- Create the table in the specified schema
CREATE TABLE dbo.MovieTickets (
[Day] int NOT NULL,
[MorningShow] bit NOT NULL,
[EveningShow] bit NOT NULL,
[TicketsSold] int NOT NULL
);
GO
The database and table are now created, the next task is to add rows to the table.
USE TicketSalesDB GO INSERT INTO dbo.MovieTickets ( [Day], [MorningShow], [EveningShow], [TicketsSold] ) VALUES (1,1,0,440), (2,1, 0,329), (3,0, 1,380), (4,1, 0,428), (5, 1, 1,900), (6,0,1,255), (7,1,1,850), (8,1,0,250), (9,1,0,310), (10,0,1,170), (11,1,0,182), (12,1,1,944), (13,0,1,280), (14,1,0,200), (15,1,0,425) GO
This populates the table with some numbers for ticket sales.
We are now ready to write some machine learning logic to perform the predictions. The entire logic for the predictions, including the Python script, is enclosed within a stored procedure, named TrainModel. We start with creation of the stored procedure within which a variable PythonScript is set to contain the Python code. This code imports necessary libraries/packages such as LinearRegression and mean_squared_error. Then, we create a connection to the database using pyodbc.connect() method, build a query to retrieve records from MovieTickets table using pd.read_sql(), and store the results in a dataframe.
The basic approach to train a regression model involves four steps: Splitting the training data (randomly) to create a dataset with which to train the model, while holding back a subset of the data to later validate the trained model, using a linear regression algorithm to fit the training data to a model, using the validation data that was earlier held back to test the model by predicting labels (values) for the features and and finally, comparing the known actual labels in the validation dataset to the labels that the model predicted.
So we'll train the model now which means that we build a model that represents the dependency between the variables in our dataset. The training dataset will be a subset of the entire dataset. We also want to filter out data for the machine learning model based on two columns from the table, Day and TicketsSold. So we store these column names in a variable named columns.
We generate the training and testing data sets based on the table data, each of which will have 4 columns, but the testing data will be a small set of the training data and not all the records in it. The random_state parameter enables you to specify a seed value for the underlying pseudo-random number generator given in the sample() method. In other words, it gives you a way to draw a random sample, while at the same time making it reproducible. When you use this parameter, the output will be the same random value each time.
Then, we fit the training model to the training data we defined and also specify the columns we had set earlier. Going further, we generate our predictions for the testing data set and aggregate the differences between predicted and actual TicketsSold values to calculate a metric mean_squared_error (MSE) indicating accuracy level of the predictions. A smaller MSE is always preferred. Lesser the MSE means smaller the error and therefore, better will be the predictions.