

Most SQL Server developers are used to using SQL Server Integration Services (SSIS) to load data. I expect that most of us can take data – be it from a database or in the form of flat files – and load it into a SQL Server table.
A few determined spirits have even pushed SSIS to its limits. They have shown how terabytes of data can be squirted into a receptive database in amazingly short times – if you have a 96 processor server and an infrastructure costing millions.
The real world that most database professionals inhabit lies somewhere between the extremes of the occasional data load and the rarefied atmosphere of relational big data. For everyday data integration practitioners the requirement is to use the short windows of opportunity in daily or weekly processing runs to load data without breaking service level agreements or tripping up subsequent processes. This means knowing a suite of tricks and techniques that enable you to go beyond the simple data load and to apply the various parallelisation and optimisation approaches that you can develop using SSIS.
In this short series of articles we will look at some of the options that are available to accelerate data loads using SSIS. I will be taking a resolutely real-world approach that tries to deliver the best result for a reasonable investment in time and energy. Moreover I am presuming that most organizations are using everyday hardware. The techniques that you will be looking at do not presume unbelievable amounts of memory or hundreds of processor cores. Neither will we be looking for the last few percent that can be squeezed out of a system - where the law of diminishing returns tends to apply (that is, the effort required for a minor improvement far outweighs the gain).
All I want to do is look at:
- How to parallelise data loads – using multiple destinations, multiple sources and parallel paths.
- How to optimise bulk loads
- How to load multiple identical files efficiently
This means that we will specifically be focusing on potential bottlenecks in a classic ETL job. These are:
- Input
- Output
- Input and output
- The data Source (file or database)
- The data Destination (file or database)
Consequently we will be looking at various combinations of these elements in this short series of articles.
The Balanced Data Distributor
As an introduction to optimising data loads, let’s move on to a simple practical example of a parallel data load using an existing tool that is extremely easy to use – the SSIS Balanced Data Distributor.
This SSIS task was first released in 2011 for SQL Server 2008. It has since been upgraded to a SQL Server 2012 version and is available in 32-bit and 64-bit versions. This task can be used to accelerate data loads considerably in certain circumstances. Essentially you can reduce data load times by a factor of between three and five (in my experience) if the following are true:
- You have a large input data load. Large can mean wide as well as deep, so it is impossible to say how many rows or how many megabytes or gigabytes of data – but if you can fill more than a couple of SSIS pipelines then you can probably benefit from using the Balanced Data Distributor
- The data source can be read faster than the destination can write the data. Essentially this means that the bottleneck is in the output, not the source.
- Your server has multiple available processors or cores. The Balanced Data Distributor is a parallel processing task, and so cannot oncrease throughput on a single processor machine.
- Your server has a reasonable amount of memory
- The data can be loaded without needing to be in any particular order.
- The destination allows for parallel loads. The rules for bulk loading in parallel can get a little complex, so let’s say (to oversimplify) that loading into a heap table (that is without a clustered index) where you have dropped any indexes and enabled table locking should do the trick.
- The destination database is configured for bulk loading.
- If possible that the recovery mode is SIMPLE or BULK LOGGED. While this is not a prerequisite (and it will speed up data loads that are not parallelised as well) it certainly increases the throughput of parallelised data loads in my experience.
Assuming, then, that you have a data load challenge that meets these requirements, here is how to use the Balanced Data Distributor to load a single source into a destination table using parallel data flows.
First you have to download the Balanced Data Distributor from the following URL: http://www.microsoft.com/en-gb/download/details.aspx?id=30147
Once you have downloaded the .Msi package to a folder on your computer you can double-click on it to install the SSIS task. After a short time the setup process will finish, and you can open SQL Server Development Tools (or BIDS, if you are using SQL Server 2008) and find the new SSIS task added to the Common Transforms that are available to any Data Flow task – as you can see in the following screenshot:
With the Balanced Data Distributor installed you can set up a data load that uses it.
In this example (and indeed in all the examples in this short series) I will be using a destination database named CarSales_Staging. You are free to use any database when trying out the process for yourself, of course. With all these prerequisites in place, here is an example of how to use the Balanced Data Distributor:
- Create a table named dbo.Stock in the destination database using the script StockTable.SQL in the sample data.
- Create a new SSIS project. Rename the startup package BalancedDataDistributor.dtsx.
- Add a data flow task – or click on the Data Flow tab and then on the “Click here to add a new data flow task”.
- Add an SSIS data source. In this example I will use a flat file source.
- Double-click on the Flat File source, click New to configure a new Flat File Connection Manager and browse to the file C:\SSISParallelProcessing\Stock01.csv.
- Click on Columns in the left pane to finish the configuration, followed by OK, twice.
- Drag the Balanced Data Distributor task on to the Data Flow surface and connect the Flat File source to it.
- Add a new OLEDB Destination Task to the package, connect to the destination database (CarSales_Staging in this example) and name it OLEDB_CarSales_Staging.
- Add three OLEDB destination tasks.
- Connect the Balanced Data Distributor task to each of the OLEDB Destination tasks.
- Double-click on each of the destination tasks and configure them to use the OLEDB_CarSales_Staging Connection Manager.
- Set the data access mode to Table or View – Fast Load.
- 1Check the Table Lock check box.
- Select dbo.Stock as the destination table.
- Click on Mappings in the left-hand pane and ensure that the fields are mapped correctly.
- Click OK to confirm the settings.
The package should look something like the following:
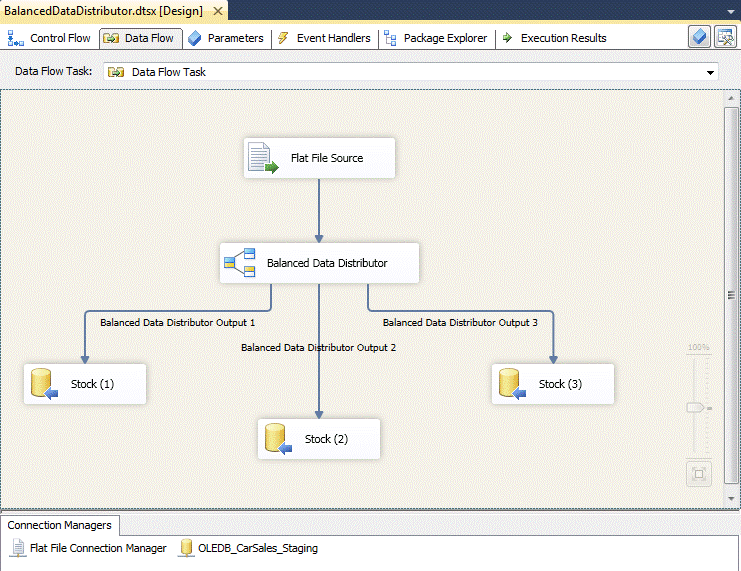
You can now run the package and load data in parallel. The Balanced Data Distributor will create as many pipelines as there are destination tasks and will use them cyclically to distribute and parallelize the output data flow. The load balancing is fairly approximate (you will not see the same number of rows processed along each path) but it is certainly efficient as it operates using SSIS pipelines and the bulkload API rather than a row-by-row approach.
This example used an extremely small text file as the data source. In reality you could be looking at an OLEDB, .Net or ODBC source to a database – and a massive amount of data. In fact the sample data set is so small that it will load using a single output path. This is because I did not want to force readers to download massive files just to demonstrate a simple concept. However what matters is the principle. Once you know how to set up a parallel data load you can use it in your application development and use your own large data sets to discover just how useful this tool can be.
Configuring the Balanced Data Distributor
There is virtually nothing that you can do to configure the Balanced Data Distributor. It has no advanced editor, and the only properties are those that you can see in the following image:

You can, theoretically, add as many output paths as you have available processor cores in your server. However the load time is unlikely to decrease in a linear fashion and will probably hit a plateau sooner rather than later. So you are best advised to begin with two or three parallel load destinations and then increase the number of paths slowly – testing the load and recording the time taken to load the same test data set with each path added. Remember also that you need sufficient available memory for an efficient parallel data load. This too implies that you will need to test various configurations until you find an optimum solution.
The Balanced Data Distributor does have certain limitations. It is not suitable for selective outputs (where you want to send data to different destinations according to a specific criterion) or when the data needs to be loaded in a defined sort order into the destination table (to map to a clustered index, for instance). However if simplicity and speed are what interest you, then it could prove very useful and could be worth adding to your SSIS armoury.
Ensuring Bulk Load using the OLEDB Destination Task
In steps 12 & 13 above you set the OLEDB destination to use Fast Load and a table lock. These two selections were fundamental for an efficient load – be it as a single data path or as a parallel load.
This is because (however many SSIS outputs are used) you will want to accelerate the load by forcing SQL Server to use the Bulk Copy API rather than loading data row by (agonizing) row.
The key requirements to get a significantly faster data load are simply:
- Set the OLEDB data Access Mode to Table or View - Fast Load to indicate that you want to use the Bulk Load API
- Check the Table Lock check box, this will apply a BU (Bulk Update) lock on the table that allows for parallel load into the destination table.
- Load into an empty table without indexes.
The last point is, unfortunately vastly oversimplified. However as bulk loading and indexes is a huge subject I am going to have to reduce this to an oversimplification – and refer you to a whitepaper (https://technet.microsoft.com/en-us/library/dd425070(v=sql.100).aspx) if you need all the multiple variations on a theme of indexes and bulk loads. However, in a real-life parallel data load you will probably be loading data into an empty staging table having disabled any indexes before a load and will probably want to reapply any indexes (both clustered and non-clustered) once the data load has finished.
As a final point a data load operation can be a bulk load operation without being minimally logged. A minimally logged data load should run faster, but even without the minimal logging, bulk load has less overhead than when you are inserting data on a row by row basis. The important point is log space. It is all too easy to fill up the transaction logs when loading large amounts of data. Minimally logged operations use considerably less log space - and so reduce the risk of either log growth slowing a process down - or running out of log and/or disk space and so crashing the entire load process.
That is, then, a short introduction to increasing processing throughput - and decreasing processing times – using the Balanced Data Distributor. In the next article in this series we will look at creating a load balancing package from scratch to give you greater control over parallel processing.
Adam is the author of Business Intelligence with SQL Server Reporting Services – Apress, February 2015, which you can purchase at Amazon.



