

Today we’re going to take a look at a problem that I’ve seen occur relatively frequently on the forums, and hopefully offer some insight into how you can artificially manufacture date ranges when only a single date column exists in your table. This is most useful when you have a table with multiple rows in a grouping, which have a single effective date on each row, and you want to establish the row where the date range applies to a specific date of interest.
First, let’s consider some sample data and explain the business requirements.
CREATE TABLE dbo.ProductPrices
(
ProductID INT
,EffectiveStartDT DATETIME
,ProductPrice MONEY
,CONSTRAINT md1 PRIMARY KEY (ProductID, EffectiveStartDT)
--,CONSTRAINT md2 UNIQUE NONCLUSTERED (ProductID, EffectiveStartDT)
);
-- Insert some initial sample data
INSERT INTO dbo.ProductPrices (ProductID, EffectiveStartDT, ProductPrice)
VALUES (1, '2013-06-04', 15.25)
,(2, '2013-05-01', 42.13)
,(1, '2013-06-17', 16.33)
,(1, '2013-06-25', 16.45)
,(2, '2013-08-09', 45.88)
,(2, '2013-08-10', 45.85)
,(1, '2014-02-23', 16.65)
,(3, '2013-12-31', 22.75);
-- Show table contents in order by Product
SELECT ProductID
, EffectiveStartDT
, ProductPrice
FROM dbo.ProductPrices
ORDER BY ProductID
, EffectiveStartDT;Because our table has a PRIMARY KEY that spans both ProductID and EffectiveStartDT, we know that within a specific ProductID each date row is unique. You can also see a second INDEX CONSTRAINT (commented out) that we’ll use in later performance testing. It is there to show the effect such an INDEX might have, in the event that in your table having the PRIMARY KEY (clustered INDEX) on ProductID and EffectiveStartDT doesn’t make sense.
The data returned by the final SELECT is as follows.
ProductID EffectiveStartDT ProductPrice 1 2013-06-04 00:00:00.000 15.25 1 2013-06-17 00:00:00.000 16.33 1 2013-06-25 00:00:00.000 16.45 1 2014-02-23 00:00:00.000 16.65 2 2013-05-01 00:00:00.000 42.13 2 2013-08-09 00:00:00.000 45.88 2 2013-08-10 00:00:00.000 45.85 3 2013-12-31 00:00:00.000 22.75
Business Requirements (Basic) – Part 1
Ignoring for the moment our ProductPrice, our initial business requirement is that the first row in each partition (ID) represents the true, effective start date. That row’s implied end date is the day before the start date of the following row (at the end of that day). If there is no following row, the end date is NULL. While those business requirements should be pretty easy to understand, seeing the expected results might help to clarify the requirements further.
ProductID EffectiveStartDT EffectiveEndDT 1 2013-06-04 00:00:00.000 2013-06-17 00:00:00.000 1 2013-06-17 00:00:00.000 2013-06-25 00:00:00.000 1 2013-06-25 00:00:00.000 2014-02-23 00:00:00.000 1 2014-02-23 00:00:00.000 NULL 2 2013-05-01 00:00:00.000 2013-08-09 00:00:00.000 2 2013-08-09 00:00:00.000 2013-08-10 00:00:00.000 2 2013-08-10 00:00:00.000 NULL 3 2013-12-31 00:00:00.000 NULL
You can see how the EffectiveEndDT for each row is either the same as the EffectiveStartDT of the following row or is otherwise NULL for the last row (by EffectiveStartDT) within the partition.
Business Requirements (Extended) – Part 2
The extended business requirements occur when you have a separate table of Products:
CREATE TABLE dbo.Products
(
ProductID INT
,ProductDescription VARCHAR(100)
);
INSERT INTO dbo.Products
( ProductID, ProductDescription )
VALUES ( 1, 'Calculator' ),
( 2, 'Cabinet' ),
( 3, 'Chair' );In the ProductPrices table, we’ve established that a product’s price can change over time. Ultimately we’ll be interested in finding what price is effective for a product (or all products) at a particular point in time.
When we finally solve the extended business requirements, we’ll show how we can use the expected, derived EffectiveEndDT in a way to achieve this result. We’ll show this at the end of the article, because most of the effort involves deriving that EffectiveEndDT.
SQL 2012 Makes Short Work of the Basic Requirement
We have four ways we can solve this in SQL Server 2012.
Solution #1 (SQL 2012): Using the LEAD Analytic Function
If you have used SQL 2012 you’re probably saying to yourself that this is quite a trivial problem, because using the LEAD analytic function will get you to the result very quickly. This is most certainly true.
-- Solution #1 (SQL 2012): Using LEAD to establish End Date (last row is open ended)
SELECT ProductID
, EffectiveStartDT
, EffectiveEndDT = LEAD(EffectiveStartDT, 1) OVER ( PARTITION BY ProductID ORDER BY EffectiveStartDT )
FROM dbo.ProductPrices
ORDER BY ProductID
, EffectiveStartDT;It is also pretty cool to note that if the basic business requirements were somewhat reversed, specifically that the first row represents an end date and so it is the open-ended row (its start date should be NULL), the solution is equally easy using LAG.
-- Using LAG to establish Start Date (first row is open ended)
SELECT ProductID
, EffectiveStartDT = LAG(EffectiveStartDT, 1) OVER ( PARTITION BY ProductID ORDER BY EffectiveStartDT )
, EffectiveEndDT = EffectiveStartDT
FROM dbo.ProductPrices
ORDER BY ProductID
, EffectiveStartDT;These results are:
ProductID EffectiveStartDT EffectiveEndDT 1 NULL 2013-06-04 00:00:00.000 1 2013-06-04 00:00:00.000 2013-06-17 00:00:00.000 1 2013-06-17 00:00:00.000 2013-06-25 00:00:00.000 1 2013-06-25 00:00:00.000 2014-02-23 00:00:00.000 2 NULL 2013-05-01 00:00:00.000 2 2013-05-01 00:00:00.000 2013-08-09 00:00:00.000 2 2013-08-09 00:00:00.000 2013-08-10 00:00:00.000 3 NULL 2013-12-31 00:00:00.000
By now you’re probably asking yourself why someone would bother to write an article about such a trivial solution. I guess you’ll just need to read on to find out why. Hopefully you won’t be disappointed.
Some Traditional Solutions
If you haven’t been gifted with the luxury of running your queries on SQL 2012, you will need to construct a query that runs on an earlier version of SQL. What are the choices?
- Commonly when confronted with a problem of this nature, people will immediately think of a self-JOIN. Doing a self-JOIN is somewhat complicated by the fact that in order to establish an exact match with the following row, you need to use ROW_NUMBER(). We’ll show how to do this in a moment.
- One traditional approach that will work as far back as SQL 2000 (or earlier) is to use a sub-query to retrieve the end date from the following row.
- SQL 2005 introduced the OUTER APPLY, which is also applicable in this case. We’ll take a look at this option also.
Compatibility for each of the solutions we’ll look at is indicated within parentheses in the subsection header.
Solution #2 (SQL 2005): Using a Self-JOIN
There are probably other ways to establish an exact match for the JOIN criteria of a self-JOIN that would be compatible back to SQL 2000, but we’ll simplify the task somewhat by using ROW_NUMBER(), which was introduced in SQL 2005.
-- Solution #2 (SQL 2005): Using a self-JOIN (ROW_NUMBER establishes exact match criteria)
WITH ProductPrices AS
(
SELECT ProductID, EffectiveStartDT
,rn=ROW_NUMBER() OVER (PARTITION BY ProductID ORDER BY EffectiveStartDT)
FROM dbo.ProductPrices
)
SELECT a.ProductID, a.EffectiveStartDT, EffectiveEndDT=b.EffectiveStartDT
FROM ProductPrices a
LEFT JOIN ProductPrices b ON a.ProductID = b.ProductID AND b.rn = a.rn + 1
ORDER BY a.ProductID, a.EffectiveStartDT;I’ll be honest in that I am not generally a fan of self-JOINs, but I’m going to be open-minded and give it a shot.
Solution #3 (SQL 2000): Using a Sub-query
Using a sub-query, we can do an ordered TOP 1 match on ProductID where the start date on the following row is greater than the start date on the current row, like this:
-- Solution #3 (SQL 2000): The subquery approach to establish the End Date
SELECT ProductID, EffectiveStartDT
,EffectiveEndDT=
(
SELECT TOP 1 EffectiveStartDT
FROM dbo.ProductPrices b
WHERE a.ProductID = b.ProductID AND b.EffectiveStartDT > a.EffectiveStartDT
ORDER BY a.EffectiveStartDT
)
FROM dbo.ProductPrices a
ORDER BY ProductID, EffectiveStartDT;You can run this query yourself to confirm that it produces the correct results.
Solution #4 (SQL 2005): Using OUTER APPLY
Using an OUTER APPLY is quite similar to the sub-query approach. A CROSS APPLY cannot be used because of the NULL end date returned for the last row.
-- Solution #4 (SQL 2005): The OUTER APPLY approach to establish the End Date
SELECT ProductID, EffectiveStartDT, EffectiveEndDT
FROM dbo.ProductPrices a
OUTER APPLY
(
SELECT TOP 1 EffectiveStartDT
FROM dbo.ProductPrices b
WHERE a.ProductID = b.ProductID AND b.EffectiveStartDT > a.EffectiveStartDT
ORDER BY a.EffectiveStartDT
) b (EffectiveEndDT)
ORDER BY ProductID, EffectiveStartDT;Once again, you can run this query to confirm it produces the expected results.
Performance Comparison
Recently one of my articles was published comparing The Performance of the T-SQL Window Functions. In that article we found that LAG/LEAD solutions were not always faster than equivalent solutions that would run in earlier versions of SQL. So it got me to wondering if the same could be said for this case.
Let’s construct a test harness we can use to compare the solutions we’ve developed.
TRUNCATE TABLE dbo.ProductPrices;
WITH Tally (n) AS
(
SELECT TOP 1000 ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
FROM sys.all_columns a CROSS JOIN sys.all_columns b
)
INSERT INTO dbo.ProductPrices (ProductID, EffectiveStartDT, ProductPrice)
SELECT a.n
,DATEADD(day, 10*b.n + 1+ABS(CHECKSUM(NEWID()))%8,'1999-12-31')
,.01*(1000+ABS(CHECKSUM(NEWID()))%4000)
FROM Tally a
CROSS JOIN Tally b;This creates 1,000 rows of dates for 1,000 ProductIDs (total of 1M rows of test data). We’ll be running against this data for the cases where:
- There is no indexing on the table.
- There is a clustered index on ProductID, EffectiveStartDT (in this case as a PRIMARY KEY).
- There is a non-clustered index on ProductID, EffectiveStartDT.
You can run these three cases yourself by simply including or not the appropriate CONSTRAINT on the temporary table, using the SQL Profiler test harness included in the attached resources files. We’ll graph CPU and elapsed times (Duration) for our four queries times three cases, averaged over five Profiler runs each.
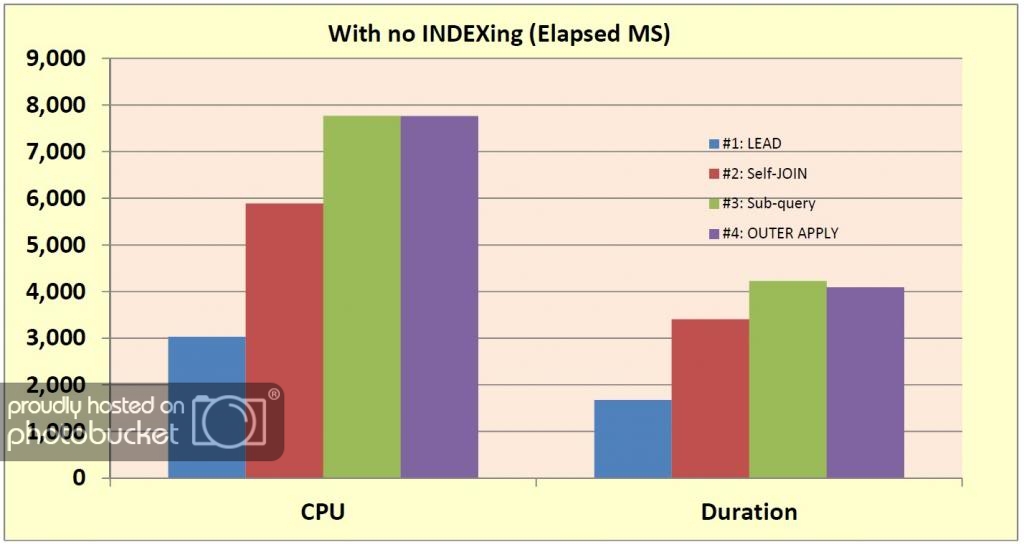
In the unlikely event that you have no INDEXing at all on the table the LEAD solution performs the best, probably because the other approaches involve two table scans as opposed to the single one using LEAD. Even with parallelization (note how the other approaches use significantly more CPU time compared to duration), it doesn’t help enough here to make up for that. If you’re not using SQL 2012, the self-JOIN seems to be best for this case.
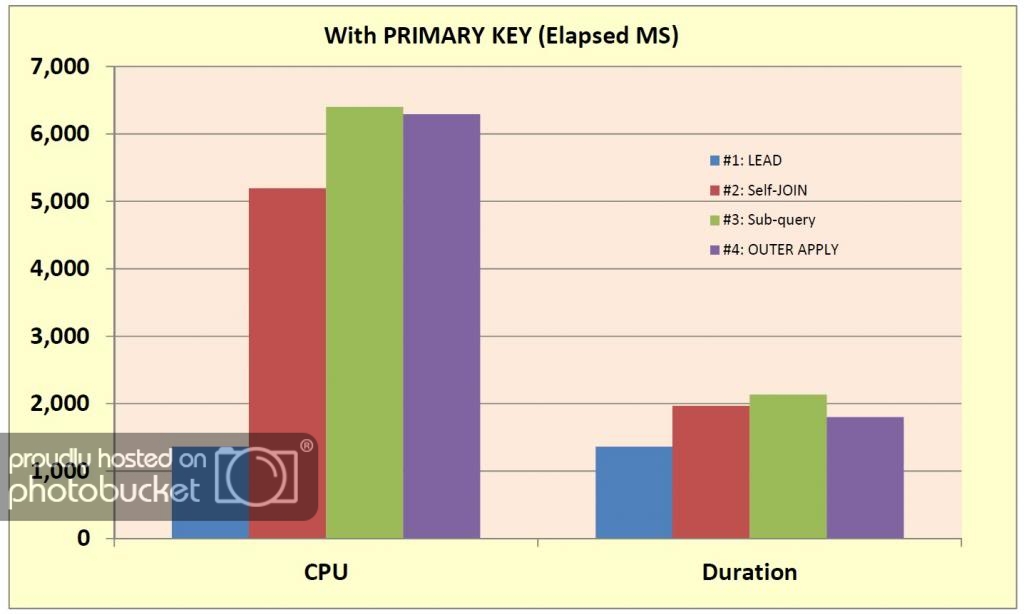
In the case where we have a PRIMARY KEY on ProductID, EffectiveStartDT, while the other solutions’ elapsed times are improved and close to LEAD, the CPU times are still comparatively high. LEAD remains the clear winner here. Because of the lower CPU time and a duration that is competitive, I’d say that once again the self-JOIN is the reasonable choice if you’re not on SQL 2012.
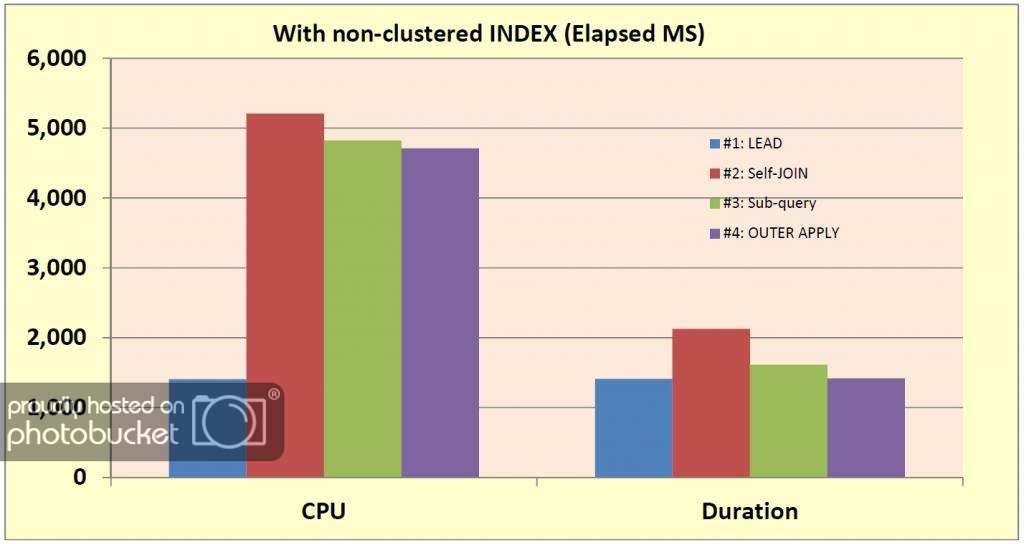
I consider this to be the most likely case, because it may not be possible for your clustered INDEX to be on ProductID and EffectiveStartDT, so this scenario uses the non-CLUSTERED index. We see that duration is once again relatively close, but LEAD is still in the lead. Once again though, CPU for the all the other solutions is relatively high. If it weren’t for parallelization, the CPU times for those would also be quite high. This may be the only case where the self-JOIN is not the second best choice (I’d award that to the OUTER APPLY solution).
Not charted but also important is the reads count returned by Profiler – in all of the scenarios tested except for the self-JOIN, they were significantly higher for the pre-SQL 2012 solutions. The self-JOIN was only marginally higher than LEAD on reads.
Revisiting the Extended Business Requirements
Now that we’ve identified the most-likely, best solutions for each particular INDEXing scenario, let’s apply them to the extended business requirements. Recall our Products table. Suppose we wish to identify the price of all products on a particular date, even at a specific time of day. We can now do that easily enough as follows:
DECLARE @DateOfInterest DATETIME = '2013-07-31 15:22';
-- Using Solution #1 (LEAD) to identify product price on a given date
WITH ProductPricesByDate AS
(
SELECT ProductID, ProductPrice
FROM
(
SELECT ProductID, EffectiveStartDT
,EffectiveEndDT=LEAD(EffectiveStartDT, 1)
OVER (PARTITION BY ProductID ORDER BY EffectiveStartDT)
,ProductPrice -- Retrieve the price along with the effective dates
FROM dbo.ProductPrices
) a
-- Add a WHERE filter using best practice to establish date within a range
WHERE @DateOfInterest >= EffectiveStartDT AND
(
EffectiveEndDT IS NULL OR @DateOfInterest < EffectiveEndDT
)
)
SELECT a.ProductID, ProductDescription, ProductPrice
FROM dbo.Products a
JOIN ProductPricesByDate b ON a.ProductID = b.ProductID
ORDER BY a.ProductID;
-- Using Solution #2 (Self-JOIN) to identify product price on a given date
WITH ProductPrices AS
(
SELECT ProductID, EffectiveStartDT, ProductPrice
,rn=ROW_NUMBER() OVER (PARTITION BY ProductID ORDER BY EffectiveStartDT)
FROM dbo.ProductPrices
),
ProductPricesByDate AS
(
SELECT a.ProductID, a.EffectiveStartDT, EffectiveEndDT=b.EffectiveStartDT, a.ProductPrice
FROM ProductPrices a
LEFT JOIN ProductPrices b ON a.ProductID = b.ProductID AND b.rn = a.rn + 1
-- Add a WHERE filter using best practice to establish date within a range
WHERE @DateOfInterest >= a.EffectiveStartDT AND
(
b.EffectiveStartDT IS NULL OR @DateOfInterest < b.EffectiveStartDT
)
)
SELECT a.ProductID, ProductDescription, ProductPrice
FROM dbo.Products a
JOIN ProductPricesByDate b ON a.ProductID = b.ProductID
ORDER BY a.ProductID;Each of those queries places our previously developed code into a Common Table Expression (CTE) and adds a WHERE filter on the date range. Both of these solutions return the following results, which do not include ProductID =3 (Chair) because on the date of interest that product did not have an established price.
ProductID ProductDescription ProductPrice 1 Calculator 16.45 2 Cabinet 42.13
Whenever you need to determine whether a date (including the time component) is between a specified range of dates, the best practice is to use greater than or equal to the start date of the range and less than (but not equal to) the end date of the range. The special handling in our WHERE filter of the NULL EffectiveEndDT for the last row keeps the query SARGable to ensure the use of available INDEXing when possible.
Conclusions
It is clear that there are cases where the new SQL LAG/LEAD functions provide a superior alternative to solutions available in prior SQL versions. While this is not always true (for example, compare the solution for finding gaps in sequence numbers using LAG or LEAD in my referenced article on Window function performance), it may occur often enough that I did not want to give these new analytic functions a bad rap for a single isolated case.
For this particular case of creating a date range when only one date is present, using the SQL 2012 LEAD analytic function is clearly superior in both speed (elapsed and CPU time) and in simplicity of coding. It is also interesting to note that there was not a lot of variation in elapsed times, regardless of whether INDEXing was present or not.
If you do need a solution that will work prior to SQL 2012, the self-JOIN approach is probably better than the other test scenarios, based on elapsed times and CPU. The possible exception to that is the case of the non-CLUSTERED INDEX, where OUTER APPLY may be a better choice.
All of the solutions proposed can be modified to address the reverse case, i.e., where the date on our row is the end date and we want to construct a start date for the range (with the first row being open ended). We’ll leave this as an exercise for our intrepid readers.
Two resource files (.sql), and an Excel spreadsheet with the raw Profiler results and graphics, are attached to this article:
- Basic Queries.sql – These are the four basic solutions developed in the article to demonstrate that all produce correct results with the minimal sample data. It also includes the LAG solution for the reverse case and the final two queries that satisfy our extended business requirements.
- Profiler Test Harness (1M Rows).sql – This is the SQL Profiler test harness used to establish the relative timings of the four solutions for the three INDEXing scenarios.
Thanks for listening once again folks! Your valuable time is as always, very much appreciated.
Dwain Camps
SQL Enthusiast
© Copyright Dwain Camps Feb 07, 2014 All Rights Reserved
