

Introduction
Continuous Delivery is a pattern that has gained popularity over the last years. At times, it’s used as a synonym of releasing more frequently. But, we could all release more frequently. Continuous Delivery is about releasing code in a way that is safer, easier, with higher quality and more frequently. This brings complexity to all the application layers, including the database. One of the main changes is how we develop under this context, to which I intend to provide some guidance for all database developers; especially on the scenario that Trunk-Based Development is the strategy chosen for the source control branch.
What is Continuous Delivery?
Continuous Delivery can be summarized as:
- The ability to make changes into production quickly
- The mindset to keep code releasable always with every check-in
- The mindset of frequently integrating your code with everyone's code
What are the benefits of Continuous Delivery?
There are many benefits of continuous delivery, since it involves changes in all steps of the software development cycle. One way of summarizing the benefits of Continuous Delivery is that the time it takes from feature design to feature delivery to the consumer is drastically reduced. Due to this reduction in cycle time and increased frequency, high level of automation and repeatability are needed for Build, Testing and Deployment.
What is Trunk-Based development?
Trunk-Based Development is the practice of checking code into trunk only, not branching your code.. Using development patterns and techniques like "Feature Toggles”, "Branching by Abstraction” and “Expand and Contract", which allow you to hide code that is not completed so you can keep the software releasable. Please note that branching is referred to as master branches not local development branches. (*common to GIT)
What are the benefits of Trunk-Based Development?
Trunk-Based development is the recommended branching strategy for Continuous Delivery. Simply put, no more branches, only trunk. Every check-in keeps the code releasable. Check-ins are frequent. The longer it takes to check-in, the more possibilities the code will not integrate properly with all the code base. When branches are created (per release or by feature), more merges are needed to release frequently. Overtime, the code base in the branches will start to differ from trunk. New tables will be created and main procedures will be changed. All the above make the merge of defects from trunk to branches a very manual task, requiring different implementations. "The idea behind trunk-based development is that the overhead from feature toggles and branching by abstraction will be much less than the manual merge and branching". The team of “Thought Works” and Martin Fowler have arrived at this conclusion after many implementations of Continuous Delivery. If your team is not well aligned with these patterns, the overhead could be more than branching and merging.
Development Patterns for Trunk-Based Development
Let's review some simple examples and patterns that can be used. Don't look at these like rules. In each situation, it is important to determine which pattern is more suitable to keep the database releasable. Keep it simple and readable for other developers. Any database system has three main areas of development.
- Data Structure (Tables)
- Programmability Objects (Stored Procedure, Functions, Views)
- Migration Scripts (Scripts)
Let's discuss the pattern and see how they apply to each area.
Branching by Abstraction Pattern

This technique can be used without Continuous Delivery to save time during development. Since we always want to keep the code releasable, this technique will be used more frequently. Discipline to go back and refactor the code is crucial. otherwise, the application overtime will become slower. Other database objects that can be used to create abstraction layers are Synonyms, Procedures, and Functions. This pattern is more suitable for table redesign, refactor or partitioning.
Expand and Contract pattern
“Parallel change, also known as “Expand and Contract”, is a pattern to implement backward-incompatible changes to an interface in a safe manner, by breaking the change into three distinct phases: expand, migrate, and contract."(Martin Fowler). This pattern can be applied to programmability objects or table design.
Example Code:
ALTER PROCEDURE dbo.Get_UserDetails( @Username NVARCHAR(256) )
AS
BEGIN
-- Return 1 dataset of 3
SELECT Firstname, LastName -- , .....
FROM dbo.tbl_user
WHERE Username = @Username
/*
Return 2 dataset of 3
a few select here
Return 3 dataset of 3
more select here
*/
ENDLet's assume we want to change the signature of the procedure to use "@userid" instead of "@username". This is what can be done as a transitory step until all callers are changed to use the new signature. Now let's Expand.
ALTER PROCEDURE dbo.Get_UserDetails( @Username NVARCHAR(256) = NULL, @userid INT = NULL)
AS
BEGIN
-- Return 1 dataset of 3
IF @userid IS NULL
SELECT Firstname, LastName -- , .....
FROM dbo.tbl_user
WHERE Username = @Username
ELSE
SELECT Firstname, LastName -- , .....
FROM dbo.tbl_user
WHERE userid = @userid
/*
Return 2 dataset of 3
a few select here
Return 3 dataset of 3
more select here
*/ENDAfter expanding, the new code can use the new parameters. The old code needs to be refactored, one-by-one. After that has been completed, now let's Contract.
ALTER PROCEDURE dbo.Get_UserDetails( @userid INT)
AS
BEGIN
-- Return 1 dataset of 3
SELECT Firstname, LastName -- , .....
FROM dbo.tbl_user
WHERE Username = @Username
/*
Return 2 dataset of 3
a few select here
Return 3 dataset of 3
more select here
*/
ENDRemember, this is done to keep the code releasable with every check-in. It is important to understand that refactoring the code base completely could not be possible as a priority for other teams (ex. testing). If a new procedure with the new signature is created to avoid integration issues, it will lead to many procedures doing the same on your database. This eventually will become big debt to maintain (code logic duplication).
Feature Toggles Pattern (this if by far the most used and talked pattern)
"Feature Toggles are a powerful technique, allowing teams to modify system behavior without changing code. They fall into various usage categories, and it's important to take that categorization into account when implementing and managing toggles. Toggles introduce complexity. We can keep that complexity in check by using smart toggle implementation practices and appropriate tools to manage our toggle configuration, but we should also aim to constrain the number of toggles in our system." (Martin Fowler)
Example:
ALTER PROCEDURE dbo.Get_PromotionEmailTemplate( @templateid INT = NULL)
AS
BEGIN
DECLARE @TemplateBody XML = NULL;
SELECT @TemplateBody = Template
FROM tbl_emailtemplates
WHERE emailtemplateid = @templateid
IF fn_IsFeatureToggleEnabled('AddPromoAsFooter') = 1 --- toggle the footer promo for the email
SELECT TOP 1 @TemplateBody = @TemplateBody + TemplatePromo
FROM tbl_FooterPromo
WHERE emailtemplateid = @templateid
ORDER BY NEWID()
ENDToggles should be small in nature. Avoid toggles like "new-pet-module", instead, use small toggles like "add-pet-promotion-email". Toggles should have 3 stages: On, Off and Retired, and these toggles should not be re-used. That is why you need to keep the inventory of retired toggles (see “Knightmare a DevOps Cautionary Tale”). If an umbrella toggle exists at the application level, there is no need to create a new feature toggle at the database layer.
Toggles categories
Release toggles: Allows for uncompleted code release on production. Also allows for dark launches. This type of toggle is usually short lived, and it is retired after being released.
Experiment toggles: This could be used to produce A/B testing. Performance and usage information need to be collected. These toggles may be used by user, or by group of users.
Ops toggles: Similar to “release toggles”, but these are meant for an operational feature. This type of toggle is usually long lived, as they might have many uses for the Operational(Ops) teams.
Permission toggles: Like “release toggles” but these are meant for the product team to allow premium features to be accessed by user or user groups.
Toggles Type
Static: Only changed at deployment time. This type of Toggle is easy to troubleshoot since only one code path is on production.
Dynamic: It can change at any time, and it can be turned on or off at runtime.
Possible Implementation for a toggle table
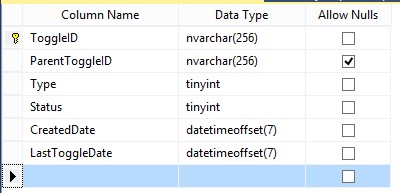
Using a dynamic feature router is always recommended. This can be implemented using a scalar function ex: fn_IsFeatureToggleEnabled([nvarchar]). Creating this abstraction layer allows you to change the feature Toggle table at any time for any other mechanism. Feature toggles are more suitable for Migration Scripts and Programmability objects.
Summary
We have covered Continuous Delivery, Trunk-Based Development, and three main development patterns that will help keep the database releasable. If you are interested in this topic, I recommended reviewing the reference section. Releasing the database was not mentioned on this article intentionally. However, this is a very important topic that should be discussed as part of Continuous Delivery of the database. There are some vendors like RedGate (ReadyRoll) that could help jumpstart the release process, or It can be built in-house using SSDT from Visual Studio. Keep in mind that tooling is important, but culture is always the determining factor in the implementation of Continuous Delivery.
References
http://martinfowler.com/articles/feature-toggles.html
http://martinfowler.com/bliki/BranchByAbstraction.html
http://martinfowler.com/bliki/ParallelChange.html
http://martinfowler.com/articles/evodb.html
https://dougseven.com/2014/04/17/knightmare-a-devops-cautionary-tale/
https://www.atlassian.com/continuous-delivery/business-case-for-continuous-delivery

