

Introduction
We are comfortable with inserting/deleting record(s) into/from a table. But we sometimes get confused when we need to insert or delete records conditionally from a table. Let us look at an example.
Example scenario
Suppose we have a table, called ALL_EMPLOYEES, which contains all employees' information who are working or had ever worked for the company. Suppose we also have a table, called SEP_EMPLOYEES, which contains those employees' information who have separated from the company. Now, the company wants to clean up their database of all the separated employees' information from the ALL_EMPLOYEES table. In this case, we need to do a conditional delete from the ALL_EMPLOYEES table.
Delete Join support
PostgreSQL does not support the DELETE JOIN statement. But we can use the USING clause with the DELETE statement to have the same functionality achieved.
The syntax looks like:

In the above syntax:
- After the USING clause, specify the table expression, which can be one or even more tables (equivalent to join)
- In the WHERE clause, use the columns from the tables in the USING clause to join the data (equivalent to join condition).
Solution for our example scenario
To solve our problem we discussed, we need to use this DELETE with USING. First we need to create the tables as:
DROP TABLE IF EXISTS ALL_EMPLOYEES;
CREATE TABLE ALL_EMPLOYEES(
employee_id serial PRIMARY KEY,
first_name varchar(50) NOT NULL,
last_name varchar(50) NOT NULL,
department varchar(15) NOT NULL
);
DROP TABLE IF EXISTS SEP_EMPLOYEES;
CREATE TABLE SEP_EMPLOYEES(
employee_id INT NOT NULL UNIQUE
);Now let's feed some dummy data into these tables as:
INSERT INTO ALL_EMPLOYEES (first_name, last_name, department) VALUES ('Sabyasachi', 'Mukherjee', 'IT Analyst');
INSERT INTO ALL_EMPLOYEES (first_name, last_name, department) VALUES ('Stephen', 'Johnas', 'Senior Dev');
INSERT INTO ALL_EMPLOYEES (first_name, last_name, department) VALUES ('David', 'Willson', 'DBA');
INSERT INTO SEP_EMPLOYEES VALUES (1);
INSERT INTO SEP_EMPLOYEES VALUES (2);
INSERT INTO SEP_EMPLOYEES VALUES (4);So now when we need to remove the data of SEP_EMPLOYEES from ALL_EMPLOYEES, we can write:
DELETE FROM ALL_EMPLOYEES USING SEP_EMPLOYEES WHERE SEP_EMPLOYEES.EMPLOYEE_ID = ALL_EMPLOYEES.EMPLOYEE_ID RETURNING ALL_EMPLOYEES.FIRST_NAME || ' ' || ALL_EMPLOYEES.LAST_NAME;
The resultant rows returns:
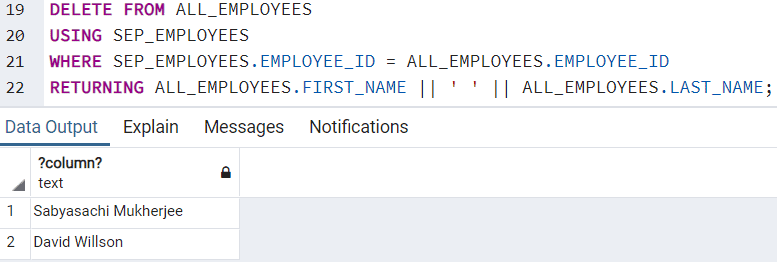
It shows the names which have been removed from the ALL_EMPLOYEES table. The record set in the ALL_EMPLOYEES table looks like:
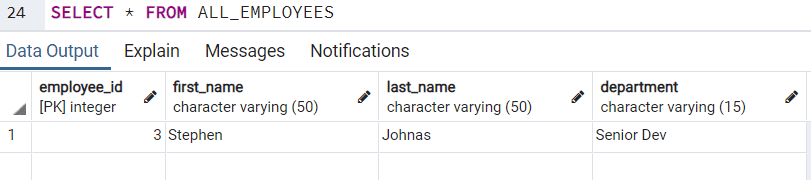
Example Scenario
Well, now suppose we have this ALL_EMPLOYEES table containing the present address of employees, too. Assume that we get a batch of employees every day whose details need to be entered into this table. Now this batch contains both new employees joining the company and also employees requesting for a change in their postal address. In such case, we cannot simply run an INSERT query because that would create multiple employee ids for the same employee requesting an address update. So here the insert should be conditional.
PostgreSQL UPSERT support
UPSERT is basically INSERT+UPDATE, i.e., it says that if no similar record is found, then you may insert the record, otherwise update the matching existing record with the information provided. To take the benefit of this feature, we need to use the INSERT ON CONFLICT syntax which is like:

The target can be either a column name or a constraint name or a WHERE clause. On the other hand, the <action_to_be_performed> can be either the DO NOTHING or the DO UPDATE statement.
Solution for our example scenario
First, we need to re-create the table with the present address column as:
DROP TABLE IF EXISTS ALL_EMPLOYEES; CREATE TABLE ALL_EMPLOYEES( employee_id serial PRIMARY KEY, first_name varchar(50) NOT NULL, last_name varchar(50) NOT NULL, email_id varchar(50) NOT NULL UNIQUE, department varchar(15) NOT NULL, present_address varchar(255) NOT NULL );
Now let's insert few records into this table running the below queries:
INSERT INTO ALL_EMPLOYEES (first_name, last_name, email_id, department, present_address) VALUES ('Sabyasachi', 'Mukherjee', 'sabya.mukh@gmail.com', 'IT Analyst', 'India, WB, Kolkata');
INSERT INTO ALL_EMPLOYEES (first_name, last_name, email_id, department, present_address) VALUES ('David', 'Willson', 'david.will@gmail.com', 'DBA', 'USA, New Jersey');
INSERT INTO ALL_EMPLOYEES (first_name, last_name, email_id, department, present_address) VALUES ('John', 'Vancock', 'john.van@gmail.com', 'Senior Dev', 'USA, San Francisco');To ensure that only fresh records are inserted and existing records does an update in the present address column, we can write a query as:
INSERT INTO
ALL_EMPLOYEES (first_name, last_name, email_id, department, present_address)
VALUES
('Sabyasachi', 'Mukherjee', 'sabya.mukh@gmail.com', 'Senior Dev', 'USA, Canada')
ON CONFLICT (email_id)
DO UPDATE
SET present_address = present_address;Now, suppose we get a batch of employees which contains 2 new employees (named: Stephen Havard and Anthony Wickwood) and 1 existing employee (named: Sabyasachi Mukherjee) requesting an address update, then the bulk INSERT ON CONFLICT queries generated would look like:
INSERT INTO
ALL_EMPLOYEES (first_name, last_name, email_id, department, present_address)
VALUES
('Sabyasachi', 'Mukherjee', 'sabya.mukh@gmail.com', 'Senior Dev', 'USA, Canada')
ON CONFLICT (email_id)
DO UPDATE
SET present_address = EXCLUDED.present_address;
INSERT INTO
ALL_EMPLOYEES (first_name, last_name, email_id, department, present_address)
VALUES
('Stephen', 'Havard', 'stephen.harv@gmail.com', 'Junior Dev', 'Indonesia')
ON CONFLICT (email_id)
DO UPDATE
SET present_address = EXCLUDED.present_address;
INSERT INTO
ALL_EMPLOYEES (first_name, last_name, email_id, department, present_address)
VALUES
('Anthony', 'Wickwood', 'anthony.wick@gmail.com', 'Finance Auditor', 'USA, New Jersey')
ON CONFLICT (email_id)
DO UPDATE
SET present_address = EXCLUDED.present_address;So if we run these all queries in a batch, then there should be 2 new employees created while 1 employees address should be updated from India, WB, Kolkata to USA, Canada.
The result looks like:
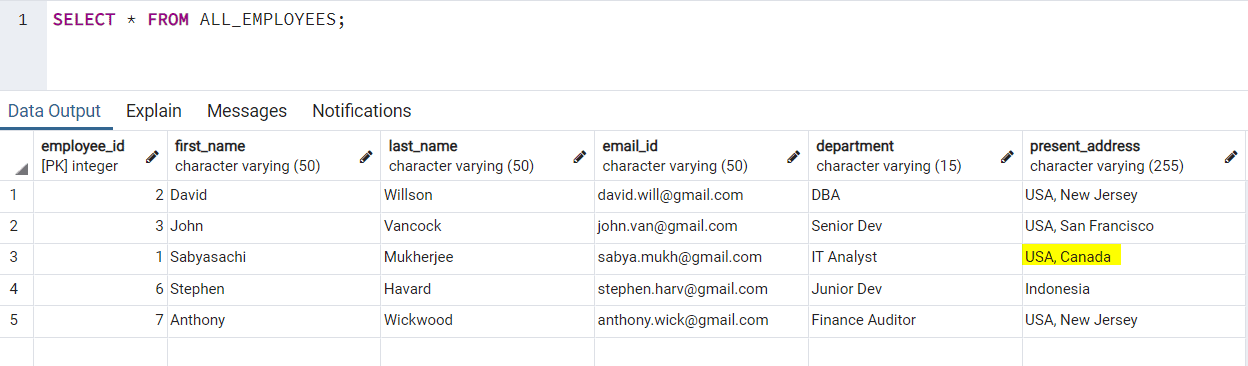
In case we do not want to do anything for any existing employee, we can use DO NOTHING instead.
Note: We are using email_id as an unique identifier here to understand whether the employee is an existing or new since 2 employees cannot have same email_id in an organization.
Conclusion
In this article, we have learnt on how to insert/update data into a table and delete data from a table joining other table(s).