

Computed columns are one of those features that we all know about but tend to
forget about when it's time to implement. Are they really a useful option since
we're denormalizing our data in some cases? Can they boost performance? The
answer to both is yes and they can actually save you some effort compared to
other options. We'll use a simple reporting example to drive our discussion.
Let's use Adventureworks for the examples. We'll start simple. You've been
helping build reports and a very common task is to list data from Person.Contact
including showing contact names as lastname then a comma and a space, then a first name (Warren, Andy). Because you're a
power user you just create it in your select statement, like this:
select lastname + ', ' + firstname as Fullname from person.contact
One way to to help out the less technical users is to create a view that
encapsulates that usage, like this:
create view vPersonContact as
--note, you could alternatively use the * to indicate all columns, I just prefer to specify
select
lastname + ', ' + firstname as Fullname
,ContactID
,NameStyle
,Title
,FirstName
,MiddleName
,LastName
,Suffix
,EmailAddress
,EmailPromotion
,Phone
,PasswordHash
,PasswordSalt
,AdditionalContactInfo
,rowguid
,ModifiedDate
from person.contactYou'll need to grant select permissions on the view to the same users that
currently have select permissions on the Person.Contact table. At that point
they can use the view in place of the table and get the fullname column for
free. Conceivably not all the users will 'get' that the view is really the table
plus a column. You could - using a little care and doing this off hours - rename
the Person.Contact table to Person.ContactBase, and then modify your view as
follows:
create view Person.Contact as
--note, you could alternatively use the * to indicate all columns, I just prefer to specify
select
lastname + ', ' + firstname as Fullname
,ContactID
,NameStyle
,Title
,FirstName
,MiddleName
,LastName
,Suffix
,EmailAddress
,EmailPromotion
,Phone
,PasswordHash
,PasswordSalt
,AdditionalContactInfo
,rowguid
,ModifiedDate
from person.contactbaseThis can take a little work if you have foreign keys, but it's doable, and ends up being being a nice transparent change to your report writers and to any application
using the table/view. I'm leaving that as an exercise for you, and we'll just
proceed using the first view. Now let's see what happens when they start to take
advantage of our new column in unexpected ways such as filtering against it:
select * from vPersonContact where fullname like '%, andy'
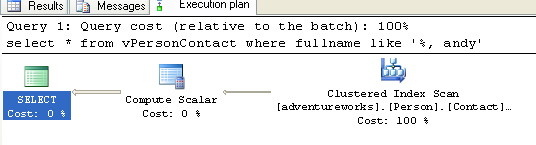
In my copy of Adventureworks I have separate indexes on lastname and firstname. You can see the user is trying to identify rows in the table with a firstname of Andy.
SQL typically doesn't give us great query plans with a leading wild card so it
goes back to the dependable clustered index scan (essentially a table scan,
meaning it has to look at every row in the table to see if it matches or
doesn't). There's nothing to stop them from filtering on firstname and
displaying fullname, but most users wouldn't know that or tend to do that by
default. But, let's look at what would happen if they did:
select * from Person.Contact where firstname='andy'
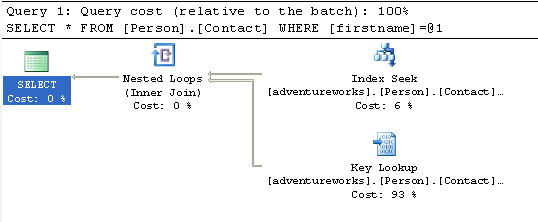
We get a much better plan (always use Profiler to confirm that the plan truly
is more effective by comparing reads for the two queries). Clearly we'd like to
avoid a table scan and the best way short of turning our users into DBA's is to
index the column. One way we can accomplish this is to modify the view to change
it to an indexed view which would allow us to index fullname after creating a
unique clustered index on the view. Indexed views are useful, but they add some
weight and complexity that we might not yet need. Another option would be to add
FullName to the table as a real column, and then create insert and update
triggers on the table that maintain the column based on changes to either first
or last name. We could then index FullName and avoid the extra complexity of the
indexed view. Our final solution and of course our target for today is to use a
computed column which is almost the the same as adding the column and creating
the triggers as you'll see next.
To add a computed column via TSQL the syntax is easy:
ALTER TABLE Person.Contact ADD FullName AS lastname + ', ' + firstname
By default computed columns are not persisted; that is, it's really just adding the expression to the table much as we added it to the view earlier. It's cleaner than
the view if you always want the column to be present. Each time we access the
column SQL will calculate the value and then display or filter against it
appropriately. It will not change our query performance though as we're
still doing it all on the fly. Here's what the plan looks like now:

If we change the definition to persisted that will eliminate the overhead of
calculating the value every time, the trade off is that we have to store the
calculated value and maintain it (essentially our trigger based solution from
above). We'll just add another column called FullName2 that will be persisted
and then retest our query:
ALTER TABLE Person.Contact ADD FullName2 AS lastname + ', ' + firstname PERSISTED

Just a minor change in the plan and one that probably doesn't greatly affect
performance as we're still scanning the table. The final option we have is to
index the column, but does it make a difference whether we index the persisted
or non persisted column? We'll create a non clustered index on each column and
then run our queries again:
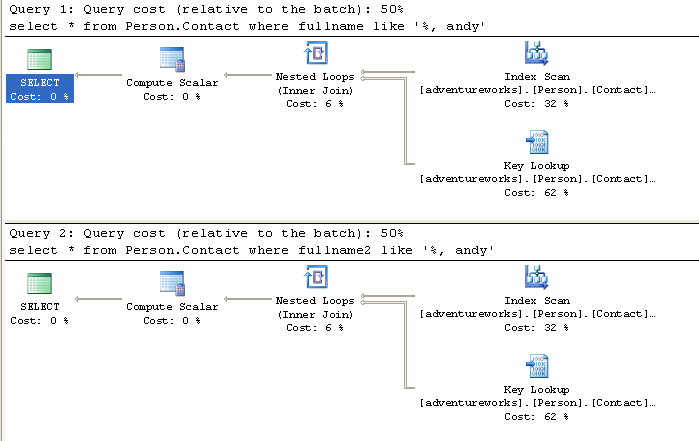
The query plans are identical which makes sense since regardless of how we
got the values, the final index would turn out exactly the same. We get an index
scan because we're still using the leading wild card (maybe training them not to
use that isn't such a bad idea after all) and that usually eliminates a seek as
an option. It's still considerably faster than a table scan though and that's
better than where we started.
At this point I haven't tested with more complex computed columns to see if I
can see a difference in overhead to maintain them. Persisting and indexing would
take up more space than just indexing or just persistently used singly. I
typically opt to just index the computed column rather than persist it, but
that's not a best practice - just my practice. The best guidance I can offer is
that if you're about to write triggers to maintain a column take a hard look at
computed columns first, then indexed views, as a way to let SQL do all the work
for you in a standard way. Denormalizing data should not be our first choice and
we want to look at all the options, but as you can see from the example we
really were denormalizing to help our users rather than just to boost
performance.
I blog once a week or so at
http://blogs.sqlservercentral.com/blogs/andy_warren/default.aspx about
SQLServer, SQL user groups, and related topics. I hope you'll visit and comment
occasionally!


