

Problem
In an ideal universe, data types would always match. A phone number would always be a BIGINT and a license plate number would always be a VARCHAR(12). Systems developed over a long period of time rarely have the hindsight to pick the correct data types in order to ensure optimal storage and performance. Eventually, we run into a scenario such as this, where we want compare data of two different types:
SELECT
EMP.BusinessEntityID,
EMP.LoginID,
EMP.JobTitle
FROM HumanResources.Employee EMP
WHERE EMP.NationalIDNumber = 658797903This simple query against AdventureWorks would be expected to perform a quick index seek, return a row, and we’d be good to go. Instead we get the following:
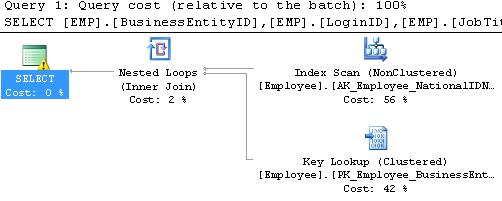
An index scan on such a simple query is unexpected to say the least! The yellow exclamation mark over the leftmost SELECT indicates that something is amiss here. Hover over the index scan and we see the cause:
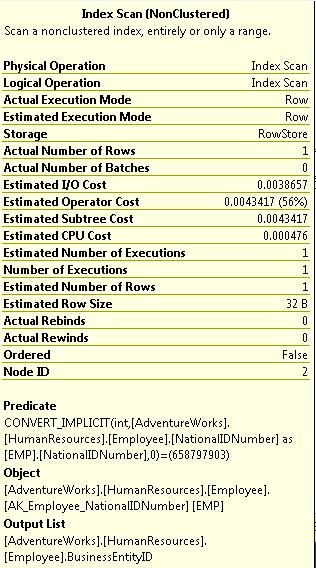
It turns out that NationalIDNumber is, in fact, an NVARCHAR(15) and not an INT. SQL Server cannot make this comparison without some additional effort on its part to convert the data type FOR EVERY SINGLE ROW in the table before being able to correctly evaluate the WHERE clause that we provided. For a large table, this can be a very expensive bug.
Solution
There are a number of ways to approach the problem, with the ultimate goal to ensure that the column we are evaluating is being compared using the same data type. In our above example, the simplest solution would be to cast our scalar value to an NVARCHAR(15):
SELECT
EMP.BusinessEntityID,
EMP.LoginID,
EMP.JobTitle
FROM HumanResources.Employee EMP
WHERE EMP.NationalIDNumber = CAST(658797903 AS NVARCHAR(15))As a result of this small change to our scalar input, we now get an index seek:
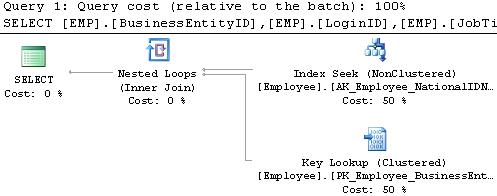
What other options exist for us in these scenarios? What if we have another table that we want to join to that has a NationalIDNumber that is an INT? The following is SQL that will generate a new table that contains the data to simulate this challenge:
CREATE TABLE EmployeeData
( BusinessEntityID INT,
HireDate DATE,
VacationHours SMALLINT,
SickLeaveHours SMALLINT,
NationalIDNumber INT,
CONSTRAINT PK_EmployeeData PRIMARY KEY CLUSTERED (BusinessEntityID))
INSERT INTO dbo.EmployeeData
( BusinessEntityID ,
HireDate ,
VacationHours ,
SickLeaveHours ,
NationalIDNumber
)
SELECT
BusinessEntityID ,
HireDate ,
VacationHours ,
SickLeaveHours ,
CAST(NationalIDNumber AS INT)
FROM HumanResources.Employee
CREATE NONCLUSTERED INDEX NCI_EmployeeData_NationalIDNumber ON EmployeeData (NationalIDNumber)
When we try to join these tables together, we run into a familiar sight:
SELECT
EMPLOYEE_DATA.*
FROM EmployeeData EMPLOYEE_DATA
INNER JOIN HumanResources.Employee EMPLOYEE
ON EMPLOYEE.NationalIDNumber = EMPLOYEE_DATA.NationalIDNumber
WHERE EMPLOYEE_DATA.NationalIDNumber = 658797903 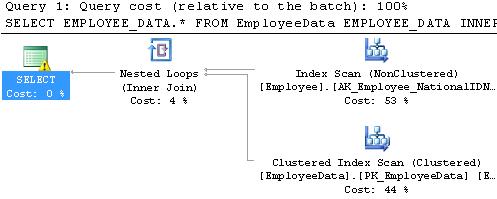
We can cast the joined column from an INT to a NVARCHAR(15), and in doing so the scan on Employee will be removed:
SELECT
EMPLOYEE_DATA.*
FROM EmployeeData EMPLOYEE_DATA
INNER JOIN HumanResources.Employee EMPLOYEE
ON EMPLOYEE.NationalIDNumber = CAST(EMPLOYEE_DATA.NationalIDNumber AS NVARCHAR(15))
WHERE EMPLOYEE_DATA.NationalIDNumber = 658797903Unfortunately, a scan is still being performed on the EmployeeData table:
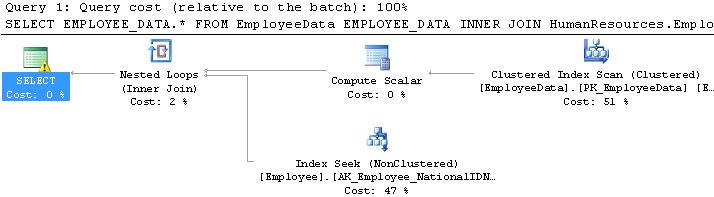
We are left realizing a design flaw in our database. By allowing a value to exist as both an INT and a NVARCHAR, we are forced to endure suboptimal performance whenever we join these tables together. We allow for confusion with regards to which data type is correct and even allow the potential for bad data to exist. For example, what would happen if a NationalIDNumber was entered into HumanResources.Employee with a value of 123-45-6789? This cannot convert to an INT and could lead to errors when executing queries and SQL Server tries to cast that string as an INT.
The perfect solution would be to alter the data type for one of the underlying columns such that both were INT or both were NVARCHAR(15). Doing so would immediately remove opportunities for implicit conversions as well as eliminate the chance of bad data being entered into this column.
If this solution is too disruptive, there are a few other (less pretty) options available:
- Create a new computed column that contains our column with the correct data type. This will need to be indexed, will take additional storage, and acts solely as a workaround. This should be avoided as anything but a stopgap measure while a better solution is being formulated.
- Cast one of the columns in the joins between tables and accept some improvement, but not optimal performance.
- Move the data needed from one table into a temporary table, creating the column in question with the correct data type. Index the column and continue from there using the temporary table in place of the original. This solution requires quite a bit of effort at the onset to achieve the index seeks we want, and is therefore only going to be helpful in a case where the base table is very large, but the rows needed are very few.
Conclusion
The data types of columns that we use for filtering and joining are critical to ensuring the best possible performance. Good database design is the key to preventing data type clashes in the future. Building a database with the foresight to choose the correct types & lengths for each column can be a time-consuming chore, but the effort needed to fix TSQL, code, and data types at a later date will be far greater than that initial cost would have been.
When faced with a situation where data types are mismatched, the best solution is to change your database schema to remove the inconsistency altogether. In addition to improving execution plans, ambiguity will be removed as to what a column is supposed to be. It will also eliminate the entry of bad data, which could lead to application errors, database errors, and the arduous task for a DBA to clean up that data after-the-fact.
If making fundamental changes to database schema is not possible, then casting the offending data type on the fly can improve performance as a short-term fix. Temporary data storage can also help when the set of data to manipulate is relatively small. Just be sure to emphasize the temporary nature of these fixes, so as to ensure that the root cause can and will be eventually fixed
