

Introduction
We want to be up to date when it comes to technology and especially how databases work. This desire made me try the new clustered column store index feature in SQL Server 2014 on our ETL loads. My loads ran blazingly fast, and I have seen huge performance gains in terms of CPU, time taken for queries, etc. However I recently ran into the “Unable to find index entry” error with clustered column store indexes.
Scenario
Our application is a BI reporting tool that connects and queries SQL Server through Java. We have implemented clustered column store indexes on all our tables, which is a new feature in SQL Server 2014. Our ETL loads involve three types of tables: staging tables, fact tables and dimension tables. Data is loaded into the staging tables from flat files. After each load, the data of previous load is deleted and new rows are inserted for new loads.
As part of my testing, I ran a few ETL loads to see the performance gains after the implementation of clustered column store indexes. There was a huge improvement in performance, and loads completed extremely fast. CPU utilization was low, while parallel loads ran very quickly. I was thrilled to see SQL Server handling parallel queries very efficiently.
However, after a few runs my load failed and I received the below error in error logs. A memory dump was also generated in addition to the error.
2014-06-03 18:15:30.32 spid76 Error: 8646, Severity: 21, State: 1.
2014-06-03 18:15:30.32 spid76 Unable to find index entry in index ID 1, of table xxxxxxx, in database 'xxx’. The indicated index is corrupt or there is a problem with the current update plan. Run DBCC CHECKDB or DBCC CHECKTABLE. If the problem persists, contact product support.
2014-06-03 18:21:13.61 spid89 **Dump thread - spid = 0, EC = 0x0000000D6BD20AE0
2014-06-03 18:21:13.61 spid89 ***Stack Dump being sent to C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\LOG\SQLDump0025.txt
My table is neither corrupted nor is the index deleted. I receive this error when 5 (or) more sequential loads on same schema are run or 16 (or) more parallel loads on different schemas are run. This is the information found in memory dump.
00000000`2e26dd70 000007fe`b6137ca5 sqlmin!CPerIndexMetaQS::ErrorAbort+0xb5
00000000`2e26ddd0 000007fe`b33f1437 sqlmin!CValFetchByKeyForUpdate::ManipData+0x29
This means the key the index is looking for is not found in the row group causing the error. First, let me explain what a row group is. When a clustered column store index is created on a table, the data is divided into small chunks (each chunk with a maximum of 1 million rows) called row groups. Depending on the size of row group, it is categorized in 3 categories: open, closed and compressed. A row group is in open state when the size of row group is less than 1 million and is compressed by optimizer only when it reaches 1 million. A compressed row group performs better than open row group because the rows are logically deleted during the delete opeartion. Rows are physically deleted on next rebuild. An open row group behaves like the traditional method where the rows are physically deleted from the table.
Due to this, when the clustered column store index tries to delete rows that are not physically present in an open row group, this error is generated. I pasted the row group status of my table below in Figure 1.
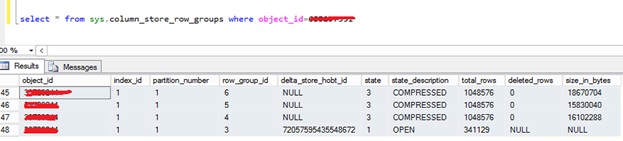
Figure 1 - Output from DMV sys.columnstore_row_groups.
We can see there are 4 row groups present in total – 3 compressed and 1 open. It is always better to keep the number of open row groups at a minimum to avoid errors.
Solution
It takes time and numerous attempts to arrive at a conclusion. Here are the results of my attempts.
Action | Error generated on running few loads? | Reason |
Drop clustered column store index | No | Since there is no clustered column store index on table and rows are physically inserted, deleted and updated when DMLs are run |
Drop clustered column store and create clustered index | No | Clustered index physically inserts, deletes and updates rows when DMLs are run |
Turn off Auto create stats and Auto update stats | No | Because a different execution plan is picked when stats are off |
Rebuild index after each load | No | Because all open row groups are compressed and logical deletes happen when deletes and updates are run |
Rebuilding the index is the preferred method because here the index is dropped, and the clustered column store index is created on the entire table. Global dictionaries are created when rebuild index is run on a table. Global dictionaries are created at entire column level, i.e., dictionary is built on values based on entire column. Local dictionaries are created whenever a new row group is created after the creation of clustered column store index. Local dictionaries are created at rowgroup level, i.e., dictionary is built on values based on column values in the current rowgroup.
Well, is it worth rebuilding indexes after each ETL load?
It’s definitely a NO because I cannot spend so many minutes rebuilding indexes after each load, and it’s more than time taken with traditional row-based approach. We can instead plan daily maintenance and rebuild indexes during off-peak hours depending on the number of rows being modified on the tables.
I would also like to explain why turning off auto create stats and auto update stats is not recommended. When stats are turned off, table statistics are not up to date and this results in performance issues. I ran parallel loads with stats off and the load time increased from 30 minutes to 2 hours. When we were working on this case with Microsoft, they recommended this option. This is because according to them, optimizer picks a different execution plan when stats are turned on and error is generated.
Conclusion
I definitely recommend implementing clustered column store indexes for ETLs but please spend some time designing a perfect maintenance activity to overcome unexpected errors. Hope my article was helpful to you.

