

In part I of this article we used undocumented DBCC PAGE command to explore how data is physically stored within DATA PAGES in SQL Server. Then we looked in detail what are different scenarios when changing table schema does not causes any change in physical data pages. In this part we will explore two remaining scenarios related to changing table schema i.e. when
1. SQL Server examines the existing data to ensure it is consistent with schema change you are making.
2. SQL server changes the physical data stored in every row.
Schema changes needing data examination and meta-data change
There are certain changes where SQL server first examines the data to ensure that changes are possible and then goes ahead and updates meta-data without physically changing the data pages. This includes changing a NULL column to NOT NULL. Obviously it will be allowed only when all the rows contain NOT NULL value for that column. Other cases are like making a fixed length column smaller in size (e.g. ‘int’ to ‘smallint’). In all such cases only data is examined and if all the rows satisfy new schema then change is made only in meta-data and no physical storage is changed. So to see this in action run following queries in a new query window. Here we are creating a new table and then checking the results of modifying table
DROP TABLE tbTestChange
GO
CREATE TABLE tbTestChange
(
PK_id INT NOT NULLPRIMARY KEY,
Col1 SMALLINT NOT NULL,
Col2 VARCHAR(10)NOT NULL,
COl3 CHAR(5)NOT NULL
)
INSERT INTO tbTestChange
SELECT 1,100,'AAAAAA','aaaa'
UNION
SELECT 2,101,'BBBBBBB','bbbbb'
GO
DBCC IND('tempdb','tbTestChange',-1)
GO
Run DBCC PAGE command using correct file and page numbers. Note the two memory dumps for two rows added above. Now alter the data type of Col1
ALTER TABLE tbTestChange
ALTER COLUMN Col1 TINYINTNOT NULL
SELECT c.nameAS column_name,c.column_id,t.name AS column_type_name,c.max_length,c.is_nullable
FROM sys.columns c
INNER JOIN sys.types t
ON c.system_type_id = t.system_type_id
WHERE c.object_id= object_id('tbTestChange')
ORDER BY c.column_id
DBCC TRACEON(3604) -- use DBCC TRACEON(3604,-1) to set it globally
DBCC PAGE('tempdb',1/* file num*/,157/*page num*/,1)
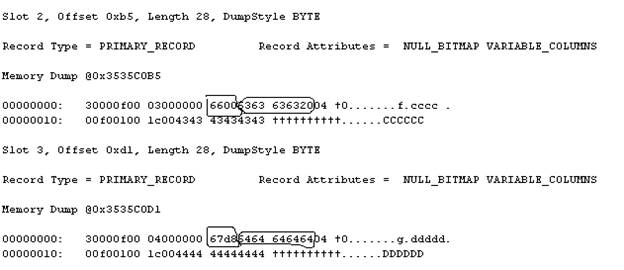
You will find that change is allowed but DBCC PAGE output is same as previous time. So no physical change took place. However if you insert a new row you will find that Col1 will still take 2 bytes and not 1 byte. So insert two more rows
INSERT INTO tbTestChange SELECT 3,102,'CCCCCC','cccc' UNION SELECT 4,103,'DDDDDD','ddddd'
Run DBCC PAGE again and you will find that new rows continue to take 2 bytes for Col1 (and not 1 byte even though it’s now TINYINT). Memory dump shows that Col3 continues to start at same offset.
Now try shortening Col3 to 3 chars. This will fail. . Though this is extremely obvious result but it does indicates that SQL server verifies the validity of change by examining data. So for large tables this can be lengthy operation.
Schema changes needing meta-data change and physical data changes
Lets recreate our test table and try few other schema changes. To begin with we will explore the effect of increasing size of a fixed length column.
DROP TABLE tbTestChange
GO
CREATE TABLE tbTestChange
(
PK_id INT NOT NULLPRIMARY KEY,
Col1 SMALLINT NOT NULL,
Col2 VARCHAR(10)NOT NULL,
COl3 CHAR(5)NOT NULL
)
INSERT INTO tbTestChange
SELECT 1,100,'AAAAAA','aaaa'
UNION
SELECT 2,101,'BBBBBBB','bbbbb'
GO
DBCC IND('tempdb','tbTestChange',-1)
GO
Run DBCC PAGE and note the memory dump for above 2 rows.

Now run following query that will give the column information for this table along with the offset of each column in the data row.
SELECT c.nameAS column_name, c.column_id, c.max_length, t.nameAS column_type_name, leaf_offset
FROM sys.system_internals_partition_columns pc
INNER JOIN sys.partitions p
ON p.partition_id = pc.partition_id
INNER JOIN sys.columns c
ON column_id = partition_column_id AND c.object_id= p.object_id
INNER JOIN sys.types t
ON c.system_type_id = t.system_type_id
WHERE p.object_id=object_id('tbTestChange')
ORDER BY c.column_id
The output of above query should be like
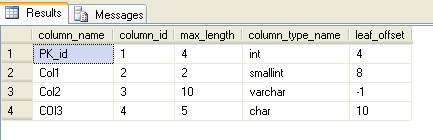
In the result above leaf_offset shows the offset of each column in the row. Note that for variable length column this is -1 indicating its 1st variable length column (as seen above actual end position is stored in 2 byte integer stored with every variable length column).
Now change Col1 from smallint to int.
ALTER TABLE tbTestChange ALTER COLUMN Col1 int NOT NULL
Now run the above mentioned query to get column offsets. The output should like this
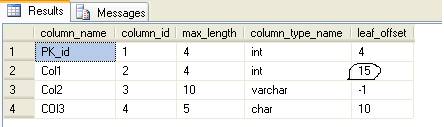
Note that offset for Col1 is now 15 (it was 8 earlier). This indicates that a new Column has been added and is stored at offset 15 (after last fixed length Col3 which is of size 5). The column at offset 8 is no loner visible.
Now run DBCC PAGE. The memory dump for 2 rows should like this
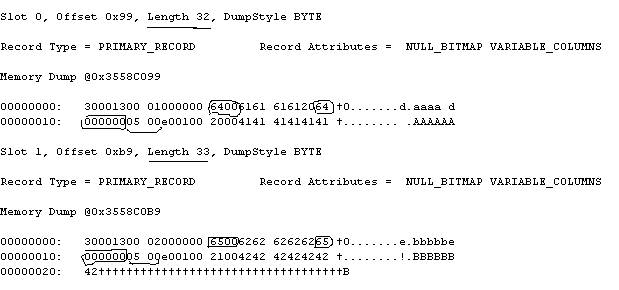
This indicates that a new column has been added with size of 4 bytes and that now contains value for Col1. The old 2 byte values for Col1 are also there. Also note that number of columns is now 5 for these rows and the length of each record has increased by 4 bytes. So what this means is increasing fixed column length leads to a new column being added to table and the space used by smaller length column is not reclaimed until we rebuild clustered index. Inserting new rows will continue to consume (waste) 2 bytes for old representation of Col1 and 4 bytes (real data) for int value of Col1.
Now let’s see what happens when we add a new NOT NULL column. As the column is NOT NULL so we need to provide some default value.
ALTER TABLE tbTestChange ADD Col4 smallint NOT NULLDEFAULT(0)
This I guess is most obvious case. Now if you run query to check column offsets then you will get following results
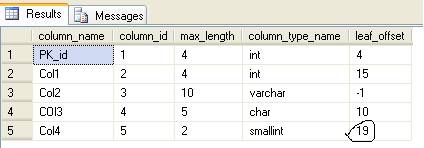
So we can see that a new column has been added after Col2 (last fixed length column). If you run DBCC PAGE command you will find that all data rows have been modified to accommodate this new column (with value 0). The output of DBCC PAGE should look like this

So if you compare this with previous DBCC PAGE output you can see lot of obvious things that indicate that new column has been added to all the rows with a value of 0 (one specified as default). The total number of columns for each row now is 6. Also length of each row record has been increased by 2 bytes (size of smallint).
Lastly we will explore what happens when we reduce the size of fixed length column. So start by recreating out test table and inserting some data using following queries
USE tempdb
GO
DROP TABLE tbTestChange
GO
CREATE TABLE tbTestChange
(
PK_id INT NOT NULLPRIMARY KEY,
Col1 SMALLINT NOT NULL,
Col2 VARCHAR(10)NOT NULL,
COl3 CHAR(5)NOT NULL
)
INSERT INTO tbTestChange
SELECT 1,100,'AAAAAA','aaaa'
UNION
SELECT 2,101,'BBBBBBB','bbbbb'
GO
DBCC IND('tempdb','tbTestChange',-1)
GOGet the file and page num and then run DBCC PAGE command to see the memory dumps for these two rows. Also check the query to get column offsets and its result will be something like this
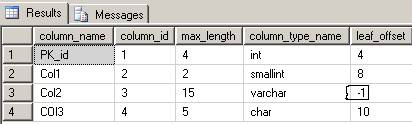
Now reduce the size of Col2 using following query
ALTER TABLE tbTestChange ALTER COLUMN Col2 VARCHAR(8)NOT NULL
Now run the query to check column offsets. Its result will be something like this
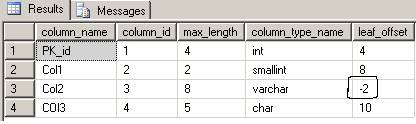
This shows that Col2 is now 2nd in the list of variable length columns.
Now run DBCC PAGE command and output will be something like this

So, many things to notice here. Number of columns in each row is now 5. Number of variable length columns is 2. Values for Col2 are now stored twice. Now insert a new record
INSERT INTO dbo.tbTestChange(PK_id,Col1,Col2,COl3) VALUES(3,103,'CCCCCC','ccccc')
Run DBCC PAGE again. You will find results similar to this
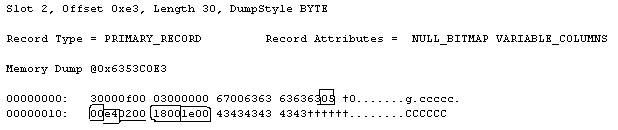
So things to note here are, total number of columns is still 5 and total number of variable columns is still 2. However the end position of 1st variable length column is ‘1800’ (24 in decimal)indicating that actual value of 1st variable length column is empty (NULL). The end position of 2nd variable length column is ‘1e00’ (30 in decimal) which points to correct end position for value ‘434343434343’ (value ‘CCCCCC’ inserted above). So the effect of reducing variable length column is as if old size column is dropped and a new is created with reduced size. The new rows will not use any space (apart from 2 byte for storing end position of a variable length column which is no longer accessible) but data space will be wasted in old rows. Again the way to reclaim old space would be to rebuild clustered index.
Summary
Following table summarizes various ALTER TABLE options and their details on what actually they mean in terms of schema changes.
| Type of table Schema Change | Meta-data change | Existing Data examination | Physical Data change | Comments/caveats |
| ADD NULL column | Yes | No | No | |
| DROP fixed length column | Yes | No | No | Storage space is not reclaimed and new rows continue to use space allocated to dropped column. Rebuild clustered index to claim space. |
| DROP Variable length column | Yes | No | No | Storage space is not reclaimed for already present rows but new rows will not use space allocated to dropped column. NULL bitmap for new rows will indicate that dropped column is NULL. Rebuild clustered index to claim space. |
| Change NOT NULL to NULL | Yes | No | No | |
| Increase size of Variable length column | Yes | No | No | |
| Reduce size of fixed length column (e.g. int to smallint) | Yes | Yes | No | New rows continue to use old data type i.e. changing int to smallint will still take up 4 bytes even in newly inserted rows. Rebuild clustered index to reclaim space. |
| Change NULL column to NOT NULL | Yes | Yes | No | |
| Increasing size of fixed length column | Yes | No | Yes | SQL server retains column with old (smaller) data type and add a new column with new (larger) data type. All the old and new rows continue to use space for smaller and new larger data type (e.g. changing smallint to int means every row now uses 2+4 bytes). Rebuild clustered index to reclaim space. |
| Adding NOT NULL column with default value | Yes | No | Yes | |
| Decreasing size of variable length column | Yes | Yes | Yes | A new variable length column is added. The old rows contain two copy of data for changed column. Rebuild clustered index to reclaim that space. |
Please note that in very large tables any schema change that involves examining data rows will take considerably long time. Any change that involves changing physical rows will take even longer time and more resources. More ever if you try to rebuild clustered index to reclaim any space then that can also be resource extensive and lengthy operation.
NOTE: All the above tests were done on SQL Server 2005 Developer Edition (SP2) and SQL 2005 Express edition (SP2).
Bibliography / Sources Consulted:
- SQL Server Books Online 2005
- Inside Microsoft SQL Server 2005: The Storage Engine - by Kalen Delaney
