

Some applications are designed to pull data from a central database into a local cache. These applications need a way to track data changes in order to know what data has been changed. Before SQL Server 2008, application developers had to implement custom tracking solutions using triggers or timestamp columns, and create additional tables in order to track data changes. As we know, triggers are expensive. Each table involved in the DML operation is checked recursively via an internal function for the presence of a trigger. In addition, because triggers are executed as a part of the transactions that cause them to be invoked, the transactions take longer to commit and introduce complicated blocking issues.
SQL Server 2008 provides a new feature, Change Tracking. Change tracking is great for building one-way or two-way synchronization applications and is designed to work with Sync Services for ADO.NET. Change Tracking is a light-weight feature which provides a synchronization mechanism between two applications. In other words, it tracks a table for the net DML (INSERT, UPDATE and DELETE) changes that occur on a table, so that an application (like a caching application) can refresh itself with just the changed dataset.
Today, let's discuss in detail about how to configure and enable Change Tracking and how Change Tracking works, for this we will create a new table, enable Change Tracking on Database and on this newly created table and then after performing some DML operation will see how Change Tracking helps in getting the information of the change done previously.
We begin by creating a table named “tblEmployee”.
Step 1: Create table “tblEmployee”
Here we will create a table named “tblEmployee” in database “Perspective”. This table has 5 columns with EmployeeID as Primary Key and other columns with details of the Employee’s.
CREATE TABLE [dbo].[tblEmployee]
(
[EmployeeID] [int] NOT NULL,
[ManagerID] [int] NULL,
[FirstName] [varchar](20) NOT NULL,
[LastName] [varchar](20) NOT NULL,
[Gender] [bit] NULL,
CONSTRAINT [PK_tblEmployee] PRIMARY KEY CLUSTERED
(
[EmployeeID] ASC
)
WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF,
IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]Step 2: Enable Change Tracking on Database
Now before we enable Change Tracking on a table we need to enable it at the database level. The SQL code below does this. Here we set the “Auto Cleanup” option ON, and changes will be retained for 3 days only. After 3 days the tracked change will no longer be available.
Depending on the project requirement you should plan to have a retention period, but make sure not to have it too long else as it will consume space on the database server. A too short time frame will not let you capture changes effectively. Generally speaking, 2 to 10 days of retention is preferred.
Alter Database Perspective Set Change_Tracking = ON (Auto_CleanUP=ON, CHANGE_RETENTION=3 Days)
AUTO_CLEANUP: With this option we can switch ON or OFF automatic tracking table cleanup process
CHANGE_RETENTION: With this option, you can specify the time frame for which tracked information will be maintained
Step 3: Enable Change Tracking at Table Level
Now we enable the Change Tracking for the table “tblEmployee” as well. Here we can mention specific columns that we want to monitor for tracking changes, if no column is mentioned, by default all the columns within the table are tracked.
ALTER TABLE tblEmployee ENABLE CHANGE_TRACKING WITH (TRACK_COLUMNS_UPDATED = ON)
Step 4: Check if Change Tracking is enabled correctly
Let’s check if the Change Tracking has been enabled on the database and the table where we want it to be. This is basically a verification step, to make sure above queries have performed their task as expected.
SELECT DB_NAME(database_id) AS NAME,
retention_period_units,
retention_period_units_desc
FROM sys.change_tracking_databases
SELECT t.name As TableName
FROM sys.change_tracking_tables ctt
JOIN sys.tables t ON ctt.object_id = t.object_idThe results are shown below:
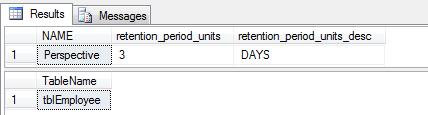
The table "sys.change_tracking_databases" shows a row for each database if Change Tracking is enabled for it.
The table "sys.change_tracking_tables" shows a row for each table that has Change Tracking enabled.
SQL Server creates an internal tracking table, the details of which are stored in “sys.internal_tables”. The naming convention for these internal tables is “change_tracking_<Table Object_ID>”
We cannot query the Change Tracking table directly, but we are provided with set of functions that help in getting the changes that are tracked.
Step 5: Retrieve Changed Information
To retrieve changed information we can use following system functions:
SELECT CHANGE_TRACKING_CURRENT_VERSION ()
SELECT CHANGE_TRACKING_MIN_VALID_VERSION(OBJECT_ID('tblEmployee'))
SELECT *
FROM CHANGETABLE (CHANGES tblEmployee,0) as CT
ORDER BY SYS_CHANGE_VERSIONCHANGE_TRACKING_CURRENT_VERSION: This function is used to get the current version number at the database level, possibly the higher boundary for retained change information
CHANGE_TRACKING_MIN_VALID_VERSION: This function gives the minimum version after the information for a table change has been retained or lower boundary for a table change information
CHANGETABLE: This function is used to retrieve change information after version 0. Since we have not performed any DML operations yet after enabling Change Tracking, this function returns no records.
Step 6: Perform some DML operations
Let's insert some data to test Change Tracking.
INSERT INTO tblEmployee Values (1, Null, 'Mike', 'Fields', 1) INSERT INTO tblEmployee Values (2, 1, 'John', 'Hopkins', 1) INSERT INTO tblEmployee Values (3, 1, 'Henry', 'III', 1) Delete tblEmployee Where EmployeeID = 2 Update tblEmployee Set FirstName = 'Suresh', LastName = 'Sankar' Where EmployeeID = 3
Here we first insert 3 records, then delete record number 2 and update the 3rd record in our tblEmployee table.
Step 7: Retrieve Changed Information
Let us now retrieve the tracked information.
SELECT CHANGE_TRACKING_CURRENT_VERSION ()
SELECT CHANGE_TRACKING_MIN_VALID_VERSION(OBJECT_ID('tblEmployee'))
SELECT *
FROM CHANGETABLE (CHANGES tblEmployee,0) as CT
ORDER BY SYS_CHANGE_VERSIONThe results are shown below
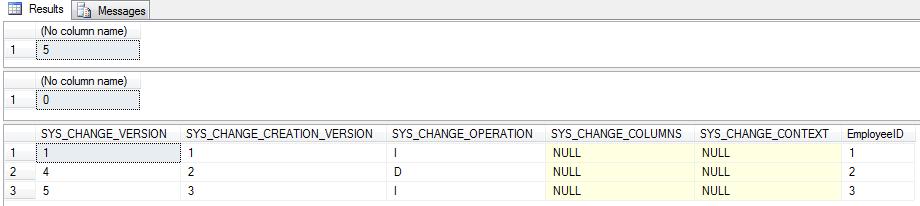
CHANGE_TRACKING_CURRENT_VERSION: This function is used to get the current version number at the database level, possibly the higher boundary for retained change information. This returns 5, because 5 DML operations have been performed after enabling Change Tracking
CHANGE_TRACKING_MIN_VALID_VERSION: This function gives the minimum version after the information for a table change has been retained or lower boundary for a table change information. This still returns 0 indicating the change information has been retained after version 0 for table tblEmployee
By passing the minimum valid version to CHANGETRACKING function we get all the change information after that specified version. We can pass any version number between the minimum valid version and current version and this function will give changed information if there are any changes between these boundaries.
Step 8: Retrieve all DML changes
From the SQL code below we are able to retrieve all the changes that have been performed on tracked table using DML operation.
DECLARE @PreviousVersion bigint = 0 SELECT CTTable.EmployeeID, CTTable.SYS_CHANGE_OPERATION, Emp.FirstName, Emp.LastName, Emp.Gender, CTTable.SYS_CHANGE_VERSION, CTTable.SYS_CHANGE_COLUMNS, CTTable.SYS_CHANGE_CONTEXT FROM CHANGETABLE (CHANGES tblEmployee, @PreviousVersion) AS CTTable LEFT OUTER JOIN tblEmployee AS Emp ON emp.EmployeeID = CTTable.EmployeeID
The results are shown below:

Step 9: Get impacted Column information only
Once we know which records were modified/inserted we might be interested in knowing the columns which got impacted. Change Tracking gives us this ability to track based on individual columns as well. The code below will help in identifying if a particular column was impacted / changed or not. Here a “1” means a change occurred and a “0” mean this column was not changed. For Insert operations since all columns get impacted it will display “1” for all columns.
DECLARE @PreviousVersion bigint = 0
SELECT
CTTable.EmployeeID,
CTTable.SYS_CHANGE_OPERATION,
Emp.FirstName,
Emp.LastName,
Emp.Gender,
[FirstNameChanged?] = CHANGE_TRACKING_IS_COLUMN_IN_MASK(COLUMNPROPERTY(OBJECT_ID('tblEmployee'),
'FirstName', 'ColumnId'), SYS_CHANGE_COLUMNS),
[LastNameChanged?] = CHANGE_TRACKING_IS_COLUMN_IN_MASK(COLUMNPROPERTY(
OBJECT_ID('tblEmployee'),'LastName', 'ColumnId')
, SYS_CHANGE_COLUMNS),
[Gender?] = CHANGE_TRACKING_IS_COLUMN_IN_MASK(COLUMNPROPERTY(OBJECT_ID(
'tblEmployee'),'Gender', 'ColumnId')
, SYS_CHANGE_COLUMNS)
FROM CHANGETABLE (CHANGES tblEmployee, @PreviousVersion) AS CTTable
LEFT OUTER JOIN tblEmployee AS Emp
ON emp.EmployeeID = CTTable.EmployeeIDThe results can be seen here:

If it depends from which point you want to track the changes, the version number comes handy. In the SQL code above if we change the value of @PreviousVersion from “0” to “2” you will see a different result (shown here):

This change lets you know the change that has happened to a particular record in database from the time when you want to its current state. Change @PreviousVersion to values from 0 to 5 and see the differences. I would leave this as an exercise to the readers.
Note: Change tracking does not provide support for recovering from the loss of data. However, there are two options for detecting these types of synchronization issues:
- Store a database version ID on the server, and update this value whenever a database is recovered or otherwise loses data. Each client application would store the ID, and each client would have to validate this ID when it synchronizes data. If data loss occurs, the IDs will not match and the clients would reinitialize.
- When a client queries for changes, record the last synchronization version number for each client on the server. If there is a problem with the data, the last synchronized version numbers would not match. This indicates that a re-initialization is required.
Change tracking in SQL Server 2008 enables applications to obtain only changes that have been made to the user tables, along with the information about those changes. With change tracking integrated into SQL Server, complicated custom change tracking solutions no longer have to be developed.
Change tracking is an important building block for applications that synchronize and replicate data in scenarios in which end-to-end replication solutions do not work and a custom solution is required.

