

There are numerous technical articles on the world wide web that give us advice on every facet of SQL Server, "how to do this", "how to configure that", "what does this new feature do". This is great, being able to research a problem on the internet is a key skill we all need to do our jobs effectively. However, I rarely see articles regarding T-SQL coding approach. How to structure your T-SQL objects and incorporate design principles. The iterative programming world is full of coding practices and code design principles. T-SQL is a language and like any language there are poor and good ways of implementing it
Let's take a minute to review some well known principles.
KISS: Keep it simple, stupid.
Set based problems are often complex and require us to build tabular images in our minds as we're trying to solve them. Not easy, but necessary. This design principle can be difficult to achieve, so we should aim for the objective "as complex as it needs to be".
DRY: Don't repeat yourself.
Again this isn't easy to achieve in T-SQL as the language often benefits in performance terms from very explicit code. Dynamic or abstract code doesn't always achieve good performance. I've seen many times in the past object oriented programmers try to make T-SQL behave in a similar manner by mimicking object overloading and using scalars as enums. Why did I become so familiar with what the object oriented programmers were doing? Because I had to solve the performance issues their code was experiencing.
SRP: Single Responsibility Principle.
An object has a single responsibility. The object has a single objective which makes it simpler, smaller and easier to isolate. Objects with these characteristics are easier to debug and unit test.
For the rest of this article I'm going to analyse a coding practice that is seen everywhere in the T-SQL world. You'll see it in legacy systems, you'll see it in green field systems, you'll see it in every incarnation of the SQL language and you'll see it in all manner of web articles and textbooks. What is this practice? Sub-querying. An essential part of the SQL language is to preprocess some data before joining it with another set of data. In the modern T-SQL language this often achieved by using the WITH clause to define aliased sets of data neatly before joining it with another table or sub-set of data. Since its introduction the WITH clause has become a very popular tool in the T-SQL coders toolbox.
I'm now going to attempt to demonstrate why the over use of the WITH clause and any other sub-querying methods brings with it poor code design.
I'll need a simple schema to help demonstrate my reasoning. So I've created a theoretical order processing schema.
Simple Entity Diagram

Over the schema I've created a sproc that calculates order summary information. The sproc has many nested subqueries using a WITH statement.
/*****************************************************************************************************
System : OrderProcessing
Created By : Gary Strange
Description : Create original sproc version
Date : 2017-06-30
*****************************************************************************************************/
/*****************************************************************************************************
Section : Create pOrder_GetSummary
*****************************************************************************************************/if (object_id('dbo.pOrder_GetSummary') is not null) drop procedure dbo.pOrder_GetSummary
go
create procedure dbo.pOrder_GetSummary
@Category varchar(100)
as
begin
;with
cte_Orders
AS
(
SELECT
OrderId
,OrderCategory
,OrderDate
FROM
OrderHeader
WHERE
--Get one quarter of data
OrderDate BETWEEN '2017-01-01' AND '2017-01-03'
AND
OrderCategory = @Category
)
,cte_OrderParts
AS
(
SELECT
SUM(UnitPrice * Quantity) AS Amount
,o.OrderId
FROM
cte_Orders o
left JOIN OrderLine ol
ON ol.OrderLineId = o.OrderId
GROUP BY
o.OrderId
)
,cte_OrderSpend
AS
(
select OrderId, sum(Amount) TotalSpend
from cte_OrderParts
group by OrderId
)
, cte_spend_aggregates as
(
select os.OrderId, os.TotalSpend
, QualifiesForDiscount = CASE WHEN os.TotalSpend > od.SpendLimit THEN 1 ELSE 0 END
, od.DiscountValueApplied
, RevisedBill = os.TotalSpend - od.DiscountValueApplied
, AdditionalSpendRequired = od.SpendLimit - os.TotalSpend
from cte_OrderSpend os
left join dbo.OrderDiscounts od on od.OrderId = os.OrderId
where od.IsActive = 1
)
SELECT
OrderId
, TotalSpend
, DiscountValueApplied = case when QualifiesForDiscount = 1 then DiscountValueApplied else 0.0 end
, RevisedBill = case when QualifiesForDiscount = 1 then RevisedBill else TotalSpend end
, AdditionSpendRequired = case when QualifiesForDiscount = 0 then AdditionalSpendRequired else 0.0 End
FROM
cte_spend_aggregates sa
;
end
goThere are some deliberate faults in the solution (plus some red herrings). But don't try and fix it now as I have a challenge for you later.
Customer services are complaining that the sproc does not return the correct results. So how do I debug the sproc to determine the problem? If I use the built-in debugger I won't get very far as the whole query is interpreted as one instruction and I can't interrogate the intermediate steps. So typically the T-SQL programmers next course of action is to start a new query window and debug the problem by issuing various select * from table commands, checking counts and cut and pasting fragments of the code to see the intermediate output.
An alternative way of coding this sproc is to use the power of in-line queries.
New Sproc
/*****************************************************************************************************
System : OrderProcessing
Created By : Gary Strange
Description : Create new sproc version
Date : 2017-06-30
*****************************************************************************************************/
/*****************************************************************************************************
Section : Create fOrdersForCategory
*****************************************************************************************************/IF (OBJECT_ID('dbo.fOrdersForCategory') IS NOT NULL)
DROP FUNCTION dbo.fOrdersForCategory
GO
CREATE FUNCTION dbo.fOrdersForCategory (@Category VARCHAR(100))
RETURNS TABLE
AS
RETURN
(
SELECT
OrderId,
OrderCategory,
OrderDate
FROM dbo.OrderHeader
WHERE
--Get one quarter of data
OrderDate BETWEEN '2017-01-01' AND '2017-01-03'
AND OrderCategory = @Category
)
GO
/*****************************************************************************************************
Section : Create fOrderAmounts
*****************************************************************************************************/IF (OBJECT_ID('dbo.fOrderAmounts') IS NOT NULL)
DROP FUNCTION dbo.fOrderAmounts
GO
CREATE FUNCTION dbo.fOrderAmounts (@Category VARCHAR(100))
RETURNS TABLE
AS
RETURN
(
SELECT
ofp.OrderId,
ol.OrderId OrderLineOrderId,
ol.OrderLineId,
ol.ProductName,
ol.OrderLineDate,
ofp.OrderCategory,
ofp.OrderDate,
UnitPrice * Quantity AS Amount
FROM dbo.fOrdersForCategory(@Category) ofp
INNER JOIN dbo.OrderLine ol
ON ofp.OrderId = ol.OrderLineId
)
GO
/*****************************************************************************************************
Section : Create fOrderTotals
*****************************************************************************************************/IF (OBJECT_ID('dbo.fOrderTotals') IS NOT NULL)
DROP FUNCTION dbo.fOrderTotals
GO
CREATE FUNCTION dbo.fOrderTotals (@Category VARCHAR(100))
RETURNS TABLE
AS
RETURN
(
SELECT
OrderId,
SUM(Amount) TotalAmount
FROM dbo.fOrderAmounts(@category)
GROUP BY OrderId
)
GO
/*****************************************************************************************************
Section : Create fOrderDiscounts
*****************************************************************************************************/IF (OBJECT_ID('dbo.fOrderDiscounts') IS NOT NULL)
DROP FUNCTION dbo.fOrderDiscounts
GO
CREATE FUNCTION dbo.fOrderDiscounts (@Category VARCHAR(100))
RETURNS TABLE
AS
RETURN
(
SELECT
os.OrderId,
os.TotalAmount,
QualifiesForDiscount =
CASE
WHEN os.TotalAmount > od.SpendLimit THEN 1
ELSE 0
END,
od.DiscountValueApplied,
RevisedBill = os.TotalAmount - od.DiscountValueApplied,
AdditionalSpendRequired = od.SpendLimit - os.TotalAmount
FROM dbo.fOrderTotals(@category) os
LEFT JOIN dbo.OrderDiscounts od
ON od.OrderId = os.OrderId
WHERE od.IsActive = 1
)
GO
/*****************************************************************************************************
Section : Create fOrderSummary
*****************************************************************************************************/IF (OBJECT_ID('dbo.fOrderSummary') IS NOT NULL)
DROP FUNCTION dbo.fOrderSummary
GO
CREATE FUNCTION dbo.fOrderSummary (@Category VARCHAR(100))
RETURNS TABLE
AS
RETURN
(
SELECT
OrderId,
TotalAmount,
DiscountValueApplied =
CASE
WHEN QualifiesForDiscount = 1 THEN DiscountValueApplied
ELSE 0.0
END,
RevisedBill =
CASE
WHEN QualifiesForDiscount = 1 THEN RevisedBill
ELSE TotalAmount
END,
AdditionalSpendRequired =
CASE
WHEN QualifiesForDiscount = 0 THEN AdditionalSpendRequired
ELSE 0.0
END
FROM fOrderDiscounts(@category) sa
)
GO
/*****************************************************************************************************
Section : Create pOrder_GetSummaryNewApproach
*****************************************************************************************************/IF (OBJECT_ID('dbo.pOrder_GetSummaryNewApproach') IS NOT NULL)
DROP PROCEDURE dbo.pOrder_GetSummaryNewApproach
GO
CREATE PROCEDURE dbo.pOrder_GetSummaryNewApproach @Category VARCHAR(100)
AS
BEGIN
SELECT
*
FROM dbo.fOrderSummary(@Category)
END
GO
The sproc has been broken down into component pieces. Both old and new versions produce very similar query plans (the new approach is marginally better). The compiler first merges all the in-line components into a single query before creating the plan. So even though the code has been broken down into small digestible pieces, the resulting query strategy is unimpeded.
The new approach has many discrete objects. Each object implements a discrete simple query. The results of each query are then passed back to the calling object, effectively creating a logical stack or query graph. Using this approach we now have some code that adheres to the KISS and SRP design principles. Each object can be used many times to achieve further system requirements, so we have also achieve the DRY principle. For example the dbo.fOrdersForCategory function could easily be adopted in any other query that targets a category or orders.
Unit Testing
Typically unit testing would be carried out using SSDT for Visual Studio. But as not every reader will be using SSDT I'll use a hand rolled unit test approach. My approach is crude and after writing it I've decided that everyone should be using SSDT or something similar for unit testing.
You'll notice that my only option to unit test the original version of the procedure is to test the final output. With the new version I can test the output for correctness at each stage, achieving much finer test coverage.
Challenge
So it's challenge time. Thanks for holding out till now, but it was important to convey the articles subject matter before getting your hands dirty with this sample code.
I have a few scripts to support this article so I'll first list and explain them here.
| Script | Explanation |
| Script1 - ArticleSchemaAndData.sql |
|
| Script2 - ArticleOriginalAndNewObjects.sql |
|
| Script3 - ArticleUnitTestProject.sql |
|
Setup for Challenge
First of all create a test database and execute the ArticleSchemaAndData script. This will deploy the orders schema and orders schema data. Next, execute the ArticleOriginalAndNewObjects script to create both versions of the sproc. Now run the ArticleUnitTestProject script. This will setup various expected output data and test execution components. All tests should run and fail.
Now you're ready to take the challenge. As I said before the sprocs have a number errors lurking in them. So time yourself. Spend 5 minutes to debug and fix the original sproc and 5 minutes to debug the new version. Once the problems are fixed, the unit tests should complete with success.
Isolated Query Plan Tuning
An additional advantage to this approach is query plan isolation. Using this method you can inspect the plan generated at each stage in the query graph, with the potential to identify problems or performance improvements. However this is not an exact science, there is no guarantee that the fragmented plans will reflect the final composite plan. The optimizer is a clever and complex engine which you can never second guess. So take caution when isolating query plan fragments in this manner and always ensure that the final plan is what you'd expect.
An example of where this method worked well for me is when I was investigating a query plan that had parallelised. The query stack/graph I was inspecting had 5 stages and I was able to identify that the 1st stage had the potential to execute serially, when the final stage was introduced, my plan opted for a table scan with a massive amount of reads.
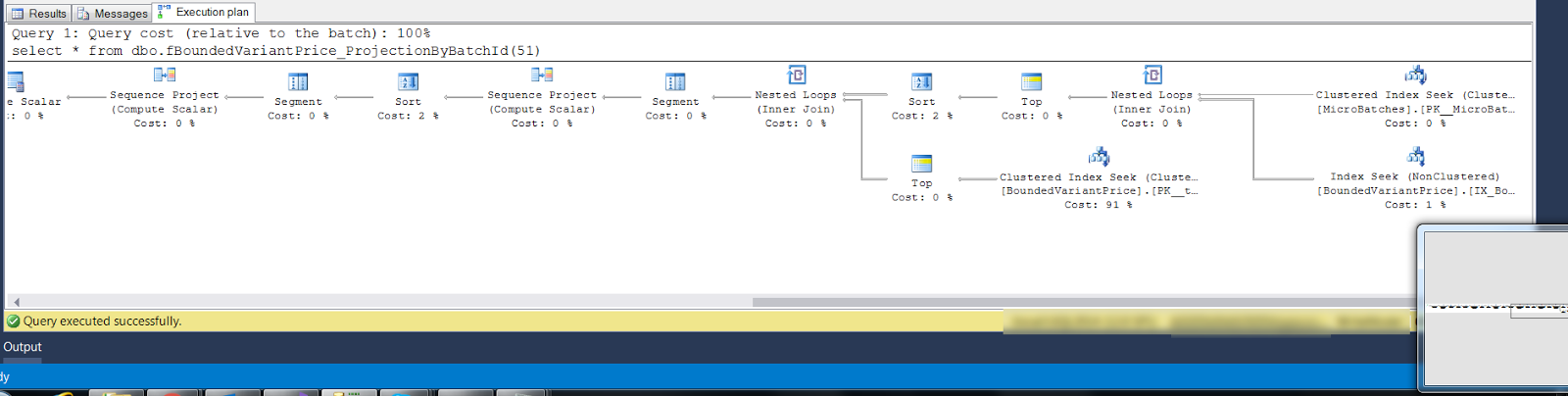
Here is an example of this is action on a pricing system I work on. I'll only show the query plans as I don't want to dive to deep into the mechanics of the pricing system. This is my misbehaving plan which is generated when I execute the full pricing query graph with 5 steps. The query produces only 31 rows.
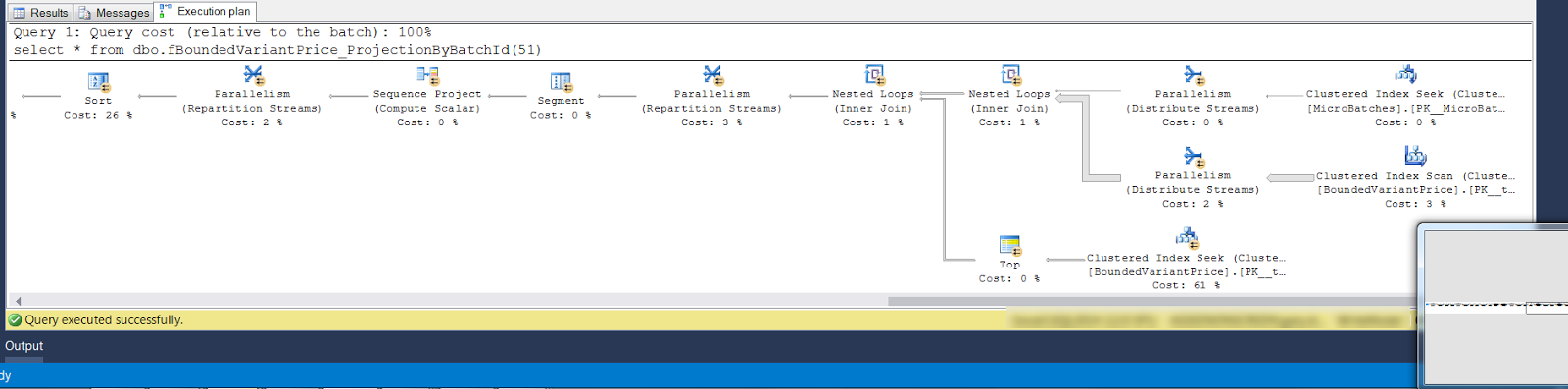
As you can see the full plan is slim with many linear operators and you can also see the parallelism taking place. The parallelism is required because it decides to scan a table index.
If I then take a look at the plan generated from the 2nd stage in the query graph I can see that I still have parallelism but a really small number of rows. That's odd.
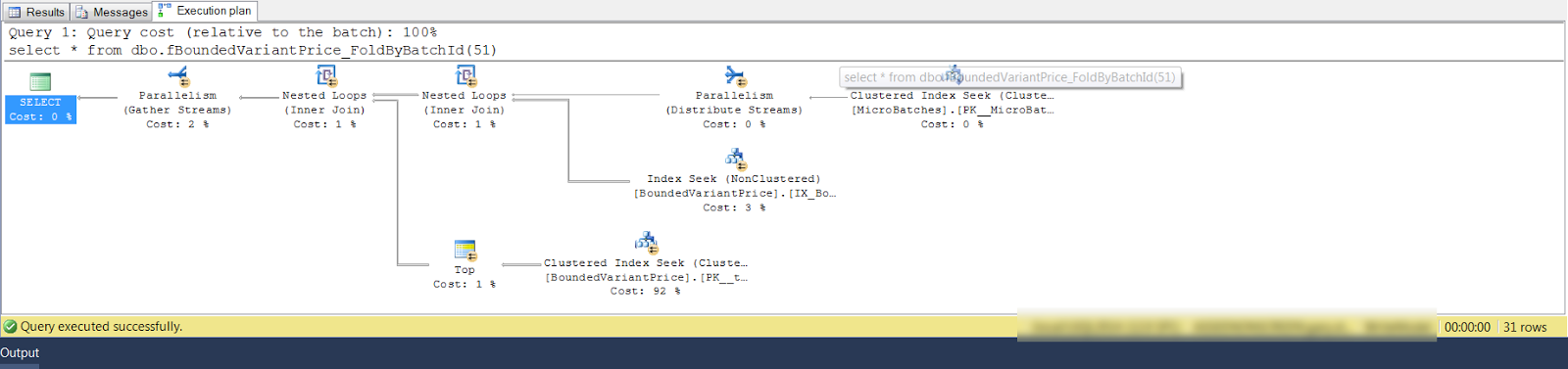
And if I check the plan from the 1st stage I still see parallelism for a small number of rows (skinny arrows between operators). The complete query produces 31 rows and only read 50 rows in from the table indexes, something's not right here.
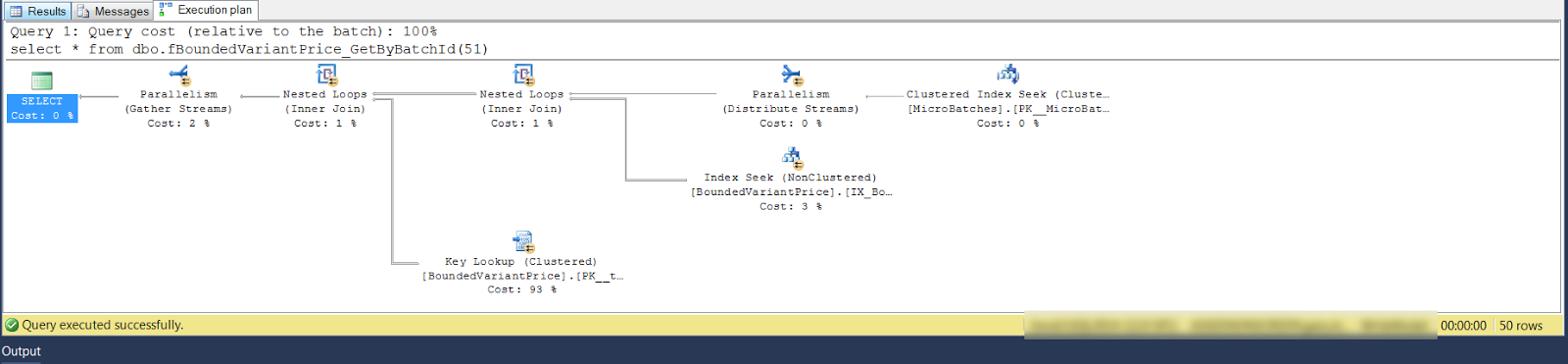
I now have a very isolated problem. After checking the query, table structure and index structures I was able to correct an estimation error and produce the following plan for the first stage…
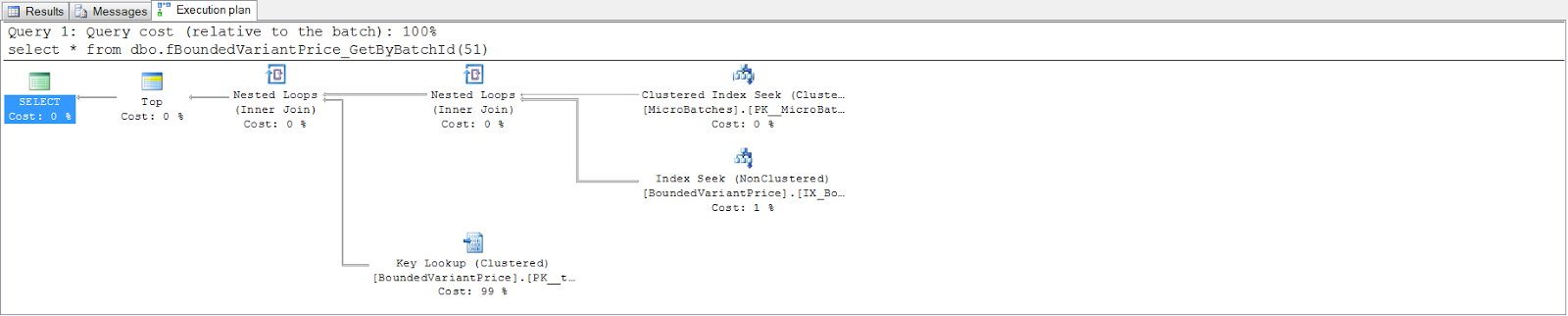
No more unnecessary parallelism. If I now execute the whole graph, I can see that I've solved the problem in its entirety. I'm very happy
Conclusion
I ask you the reader to take the challenge and make your own conclusions. Please provide your feedback in the article comments.