

Introduction
I sat through a YouTube webinar on Data Lakes, and I’ll have to admit that it was pretty cool. With the advent of ‘Big Data’, the various cloud offerings, Big Table, Hadoop, python, Atlas/Atlas SQL, etc., the question arises: is the traditional Data Warehouse (DW) even needed? I noticed that when installing Microsoft SSAS the default for SQL 2022 is now the Tabular data model. So, is the multi-dimensional model even used today?
The traditional, multi-dimensional DW cannot be replaced; it offers data analysis that is unmatched I believe. As I assembled this article, I saw several other writings and videos on the ‘death of the star schema’, ‘death of the traditional data mart’, and others. One would expect a suitable replacement if it were in fact dying, but as of yet, I have not seen that replacement. The question should be, “Do I need that depth of analytics?”.
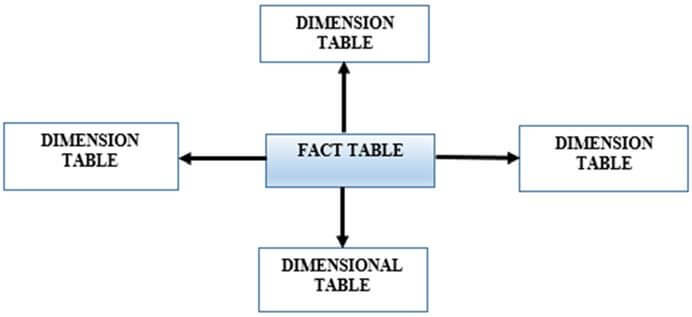
In this article I show how to create a Kimball DW. A Kimball DW or data mart is, to me, fact and dimension tables developed from one or more sources. It could be sourced from the transactional system or from another source. Although the final product is familiar, the method is not. In the end, we’ll have clean dimensions and a narrow fact table that displays its values from the dimension tables. This is not endorsed by or approved by Mr. Kimball or any of his former employees at The Kimball Group. Well, darn.
Background
Throughout my database career, I have used SQL Server mostly and have ‘dabbled’ in several areas; as a consultant, I was required to touch all aspects of SQL Server. From coding to performance tuning to data warehousing, I was exposed to a lot, and expected to be fluent no matter what area a task may have been. As I have gotten older and more experienced, I have learned that I must yield to those who are experts within their area. “Render to Caesar the things that are Caesar's,” it has been said. Looking back at my SQL Server career, as such, my focus has been more than anything else on data mart and DW development using Kimball methodologies over the past 25 years, at least more so than the other areas of SQL Server.
The traditional star-schema with the fact table and accompanying Dim tables, popularly used for a long time for data analysis, is still needed. However, what is also needed I believe is to modernize how we think of a traditional DW. In order to maintain the feasibility of the star-schema on a transactional database, some of the old rules need to be challenged and bent, so to speak.
The Issues
Two things must categorically change. Ralph Kimball used to say 1) ‘show them something in 90 days’, meaning that the development team produce a working data mart or DW within 90 days of its inception. I say that we should shorten this to 90 minutes. The 90 days caveat used to work well, but it is far too slow these days. What also must change is 2) the cost for the modern data warehouse must be driven down considerably. For example, one of the first DW that I worked on cost one million dollars, or so I heard. I wonder - did the company save millions or make millions with this DW? Did it pay for itself? Was the expenditure worth the cost?
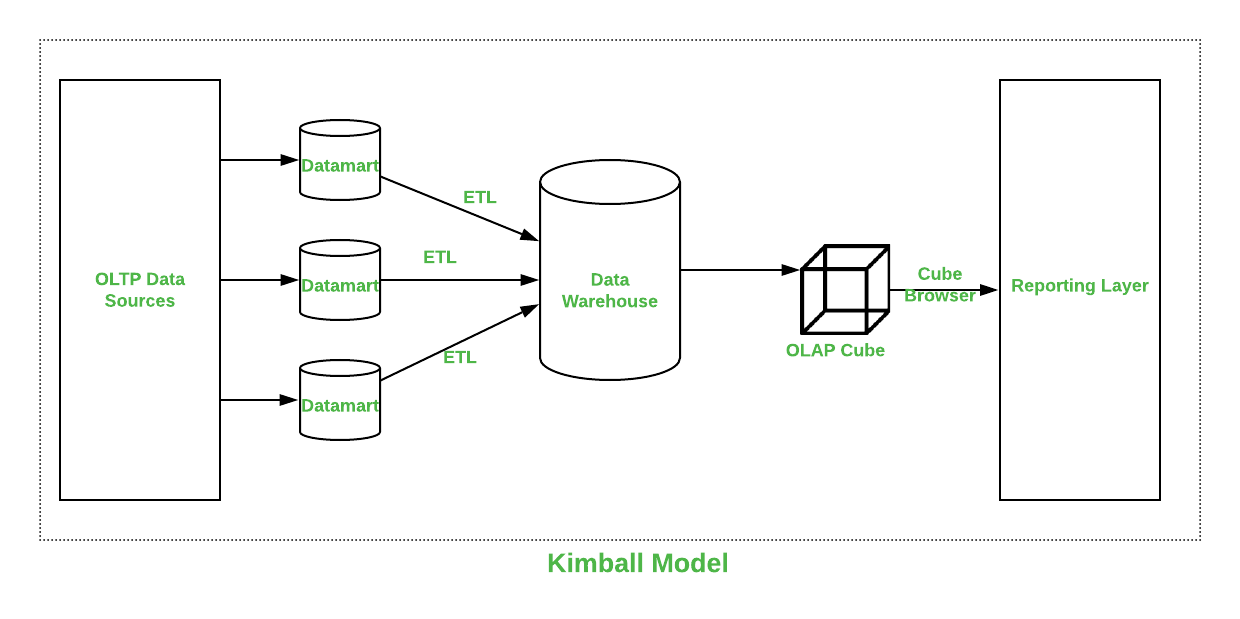
I use the term data warehouse loosely, here. I subscribe to the traditional definition that these are data marts, and more than one data mart could be thought of cumulatively as a data warehouse. A DW is not a database where records from the online production system are stored; the junior database developer at match.com back years ago said that he was going to create a ‘data warehouse’ by simply moving rows or storing aggregate tables – this is not a data warehouse!
My training and background rests on the Kimball Methodology; I once attended a weeks-long dimensional modeling course led by Mr. Kimball himself and his sidekick Margy (SAY Mar-gee) Ross back in the early 2000’s. I have all his books around here somewhere, all autographed. As a matter of fact, in 2005 I actually introduced a concept to him. He was like ‘send it to me’. At the time, my ego was too big, and I was like ‘Hell no’ to myself. What’s an idea worth if you can’t share it with others? Years later I was consulting at a pharmaceutical company, and happened to run across someone that was in the course with me. With elation and excitement, I contacted the person, only to get a ‘Um, oh hi’, ‘yeah’, ‘good to hear from you’, blah blah. What a disappointment!
Today's Data Warehouse
I have built dozens of dimensional data marts using both for clients as a consultant, and for a company as a full-time employee. I have mentioned that the traditional rules of the DW must be bent. (In my opinion). Some of those are:
Rule #1 – Simplify Dimensions. Dimension tables (dims) I believe, are the heart of the DW. But, in Kimball’s methodology, dimensions need to be almost perfect. I contend that this is not true. Spending valuable time going back and forth with various department members is fruitless, and a waste of time. The DW practitioner would do well to instead make a choice and move on. For instance, it would be better suited to pick ‘Rd.’ instead of ‘road’ inside of the I.T. shop, rather than spend weeks discussing with teams across the business units. Or it may be smarter to build a simple dimension, rather than saving space to combining columns into a single dimension, which may take weeks or months to create, or be difficult to build. The users may in fact choose ‘road’ later, which is fine, but don’t halt production deciding on this.
Rule #2 – Use the front-end often. A stealth-minded data practitioner should rely on his/her presentation layer often, rather than make changes to the DW. It is much easier to change labels, as opposed to making structural changes inside of SQL Server.
Rule #3 – Don’t be afraid to trash development and start over.
Rule #4 – Don’t assume that the fact table must be at the lowest grain.
Use aggregations and roll-ups as you see fit. Although there may have been an instance, I do not remember a time where I needed to drill-down to the lowest level, usually the transaction itself. If you can skip this, it may save you time. Remember that storing aggregations might make them non-additive. Try it out for yourself – sometimes, I have to see the results in a view or cube, I can’t tell if it’s a good addition until it is finished.
Rule #5 – Load the fact table vertically.
Loading the fact table one row at a time is deathly slow. Use, or take advantage of recordset logic and minimally logged operations (SELECT INTO and the hint TABLOCKX are two in SQL Server that come to mind) and load column by column. Hints work for both INSERT and UPDATE statements. A degenerate dimension helps considerably when vertically loading a fact table.
My Experiences
That million-dollar data mart that I mentioned earlier originally took a weekend to load. After it was rewritten, it loaded in only a few hours. Which reminds, if you are loading through Linked Servers, move the data first through the server, and then operate on it. I lowered the load time for a DW from 24 hrs. to 25 minutes. So, I became a hero for a day.
This is a ‘minimalist’ data mart; for learning purposes, there is one Fact table, and two dim tables. Normally, you may see the configuration of one Fact and 10-20 dim tables, or more.
The DateDim is renamed from this one; I borrowed this dimension as it was one of the first ones that I came across and thought it was a good one. I liked this one because you can set the currentDate and endDate parameters; going back to the year 1754 leaves too many ‘empty cells’; our data starts in 2016, so there is no reason to as it bloats dropdowns and isn’t representative. The only change I made was to rename the table from dim_date to DateDim to match the naming convention that I decided upon. It comes from mssqltips.com, a good site with lots of handy scripts.
The single dimension that I created from scratch I called LocationDim; this dimension is very simple and combines State, City, and StateCode. I did happen to notice that two states came over as abbreviations, so I put my customer service hat on and fixed the data. Programming this would be difficult to accomplish, so fixing this by hand is probably the best method. If it gets published with the abbreviation, I wouldn’t sweat it, but would expect a call from a user to fix the data.
Although this data mart has only one fact table, it could have more. For example, I watched a PowerPivot video the other day where they had two fact tables, each from a different data source, that joined all the data together. It’s easy to handle this scenario; my suggestion is that each fact table be of the same grain; if for instance you wanted to combine sales with weather, then make sure that daily sales are matched to daily weather.
Here are a few steps to follow to create a data warehouse.
Step 1: Create a database
I named ours ‘DW’ and used a script like the one below. Note, this drops the database first, so it's only useful for testing.
USE MASTER GO ALTER DATABASE DW SET SINGLE_USER WITH ROLLBACK IMMEDIATE DROP DATABASE DW GO CREATE DATABASE DW GO USE DW GO
Step 2: Import the .csv file
For this minimalist data mart, we are using one data source, import that now, and call this table ‘DataRaw’. The download is here and has the correct data types already included; I skipped any column names in the file, so mine show Column1, Column2, etc.
Step 3: Create the date table
Run the DimDate schema script, then populate the schema. I then insert a key 12319999 row - take advantage of IDENTITY_INSERT and INSERT a default for each dim table as needed. Note that the default is not used in this example.
USE [DW];
GO
/****** Object: Table [dbo].[DateDim] Script Date: 3/31/2023 8:44:23 AM ******/SET ANSI_NULLS ON;
GO
SET QUOTED_IDENTIFIER ON;
GO
CREATE TABLE [dbo].[DateDim]
( [DateKey] [INT] NOT NULL
, [Date] [DATE] NOT NULL
, [Day] [TINYINT] NOT NULL
, [DaySuffix] [CHAR](2) NOT NULL
, [Weekday] [TINYINT] NOT NULL
, [WeekDayName] [VARCHAR](10) NOT NULL
, [WeekDayName_Short] [CHAR](3) NOT NULL
, [WeekDayName_FirstLetter] [CHAR](1) NOT NULL
, [DOWInMonth] [TINYINT] NOT NULL
, [DayOfYear] [SMALLINT] NOT NULL
, [WeekOfMonth] [TINYINT] NOT NULL
, [WeekOfYear] [TINYINT] NOT NULL
, [Month] [TINYINT] NOT NULL
, [MonthName] [VARCHAR](10) NOT NULL
, [MonthName_Short] [CHAR](3) NOT NULL
, [MonthName_FirstLetter] [CHAR](1) NOT NULL
, [Quarter] [TINYINT] NOT NULL
, [QuarterName] [VARCHAR](6) NOT NULL
, [Year] [INT] NOT NULL
, [MMYYYY] [CHAR](6) NOT NULL
, [MonthYear] [CHAR](7) NOT NULL
, [IsWeekend] [BIT] NOT NULL
, [IsHoliday] [BIT] NOT NULL
, [HolidayName] [VARCHAR](20) NULL
, [SpecialDays] [VARCHAR](20) NULL
, [FinancialYear] [INT] NULL
, [FinancialQuater] [INT] NULL
, [FinancialMonth] [INT] NULL
, [FirstDateofYear] [DATE] NULL
, [LastDateofYear] [DATE] NULL
, [FirstDateofQuater] [DATE] NULL
, [LastDateofQuater] [DATE] NULL
, [FirstDateofMonth] [DATE] NULL
, [LastDateofMonth] [DATE] NULL
, [FirstDateofWeek] [DATE] NULL
, [LastDateofWeek] [DATE] NULL
, [CurrentYear] [SMALLINT] NULL
, [CurrentQuater] [SMALLINT] NULL
, [CurrentMonth] [SMALLINT] NULL
, [CurrentWeek] [SMALLINT] NULL
, [CurrentDay] [SMALLINT] NULL
, PRIMARY KEY CLUSTERED ([DateKey] ASC) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]) ON [PRIMARY];
GO
SET NOCOUNT ON;
TRUNCATE TABLE DateDim;
DECLARE @CurrentDate DATE = '2015-01-01';
DECLARE @EndDate DATE = '2023-12-31';
WHILE @CurrentDate < @EndDate
BEGIN
INSERT INTO [dbo].[DateDim]
([DateKey], [Date], [Day], [DaySuffix], [Weekday], [WeekDayName], [WeekDayName_Short], [WeekDayName_FirstLetter], [DOWInMonth], [DayOfYear], [WeekOfMonth], [WeekOfYear], [Month], [MonthName], [MonthName_Short], [MonthName_FirstLetter], [Quarter], [QuarterName], [Year], [MMYYYY], [MonthYear], [IsWeekend], [IsHoliday], [FirstDateofYear], [LastDateofYear], [FirstDateofQuater], [LastDateofQuater], [FirstDateofMonth], [LastDateofMonth], [FirstDateofWeek], [LastDateofWeek])
SELECT
DateKey = YEAR (@CurrentDate) * 10000 + MONTH (@CurrentDate) * 100 + DAY (@CurrentDate)
, DATE = @CurrentDate
, Day = DAY (@CurrentDate)
, [DaySuffix] = CASE
WHEN DAY (@CurrentDate) = 1
OR DAY (@CurrentDate) = 21
OR DAY (@CurrentDate) = 31 THEN
'st'
WHEN DAY (@CurrentDate) = 2
OR DAY (@CurrentDate) = 22 THEN
'nd'
WHEN DAY (@CurrentDate) = 3
OR DAY (@CurrentDate) = 23 THEN
'rd'
ELSE
'th'
END
, WEEKDAY = DATEPART (dw, @CurrentDate)
, WeekDayName = DATENAME (dw, @CurrentDate)
, WeekDayName_Short = UPPER (LEFT(DATENAME (dw, @CurrentDate), 3))
, WeekDayName_FirstLetter = LEFT(DATENAME (dw, @CurrentDate), 1)
, [DOWInMonth] = DAY (@CurrentDate)
, [DayOfYear] = DATENAME (dy, @CurrentDate)
, [WeekOfMonth] = DATEPART (WEEK, @CurrentDate) - DATEPART (WEEK, DATEADD (MM, DATEDIFF (MM, 0, @CurrentDate), 0)) + 1
, [WeekOfYear] = DATEPART (wk, @CurrentDate)
, [Month] = MONTH (@CurrentDate)
, [MonthName] = DATENAME (mm, @CurrentDate)
, [MonthName_Short] = UPPER (LEFT(DATENAME (mm, @CurrentDate), 3))
, [MonthName_FirstLetter] = LEFT(DATENAME (mm, @CurrentDate), 1)
, [Quarter] = DATEPART (q, @CurrentDate)
, [QuarterName] = CASE
WHEN DATENAME (qq, @CurrentDate) = 1 THEN
'First'
WHEN DATENAME (qq, @CurrentDate) = 2 THEN
'second'
WHEN DATENAME (qq, @CurrentDate) = 3 THEN
'third'
WHEN DATENAME (qq, @CurrentDate) = 4 THEN
'fourth'
END
, [Year] = YEAR (@CurrentDate)
, [MMYYYY] = RIGHT('0' + CAST (MONTH (@CurrentDate) AS VARCHAR(2)), 2) + CAST (YEAR (@CurrentDate) AS VARCHAR(4))
, [MonthYear] = CAST (YEAR (@CurrentDate) AS VARCHAR(4)) + UPPER (LEFT(DATENAME (mm, @CurrentDate), 3))
, [IsWeekend] = CASE
WHEN DATENAME (dw, @CurrentDate) = 'Sunday'
OR DATENAME (dw, @CurrentDate) = 'Saturday' THEN
1
ELSE
0
END
, [IsHoliday] = 0
, [FirstDateofYear] = CAST (CAST (YEAR (@CurrentDate) AS VARCHAR(4)) + '-01-01' AS DATE)
, [LastDateofYear] = CAST (CAST (YEAR (@CurrentDate) AS VARCHAR(4)) + '-12-31' AS DATE)
, [FirstDateofQuater] = DATEADD (qq, DATEDIFF (qq, 0, GETDATE ()), 0)
, [LastDateofQuater] = DATEADD (dd, -1, DATEADD (qq, DATEDIFF (qq, 0, GETDATE ()) + 1, 0))
, [FirstDateofMonth] = CAST (CAST (YEAR (@CurrentDate) AS VARCHAR(4)) + '-' + CAST (MONTH (@CurrentDate) AS VARCHAR(2)) + '-01' AS DATE)
, [LastDateofMonth] = EOMONTH (@CurrentDate)
, [FirstDateofWeek] = DATEADD (dd, - (DATEPART (dw, @CurrentDate) - 1), @CurrentDate)
, [LastDateofWeek] = DATEADD (dd, 7 - (DATEPART (dw, @CurrentDate)), @CurrentDate);
SET @CurrentDate = DATEADD (DD, 1, @CurrentDate);
END;
--Update Holiday information
UPDATE DateDim
SET
[IsHoliday] = 1
, [HolidayName] = 'Christmas'
WHERE
[Month] = 12
AND [DAY] = 25;
UPDATE DateDim
SET SpecialDays = 'Valentines Day'
WHERE
[Month] = 2
AND [DAY] = 14;
--Update current date information
UPDATE DateDim
SET
CurrentYear = DATEDIFF (yy, GETDATE (), DATE)
, CurrentQuater = DATEDIFF (q, GETDATE (), DATE)
, CurrentMonth = DATEDIFF (m, GETDATE (), DATE)
, CurrentWeek = DATEDIFF (ww, GETDATE (), DATE)
, CurrentDay = DATEDIFF (dd, GETDATE (), DATE);
GO
USE [DW];
GO
INSERT DateDim
SELECT
99991231
, '9999-12-31'
, [Day]
, [DaySuffix]
, [Weekday]
, [WeekDayName]
, [WeekDayName_Short]
, [WeekDayName_FirstLetter]
, [DOWInMonth]
, [DayOfYear]
, [WeekOfMonth]
, [WeekOfYear]
, [Month]
, [MonthName]
, [MonthName_Short]
, [MonthName_FirstLetter]
, [Quarter]
, [QuarterName]
, [Year]
, [MMYYYY]
, [MonthYear]
, [IsWeekend]
, [IsHoliday]
, [HolidayName]
, [SpecialDays]
, [FinancialYear]
, [FinancialQuater]
, [FinancialMonth]
, [FirstDateofYear]
, [LastDateofYear]
, [FirstDateofQuater]
, [LastDateofQuater]
, [FirstDateofMonth]
, [LastDateofMonth]
, [FirstDateofWeek]
, [LastDateofWeek]
, [CurrentYear]
, [CurrentQuater]
, [CurrentMonth]
, [CurrentWeek]
, [CurrentDay]
FROM [dbo].[DateDim]
WHERE datekey = 20191121;
GOStep 4: Create the location dimension
This script will build the LocationDim table. All dimensions should be created before the FactTemp table, no exceptions.
SELECT DISTINCT column9 as State ,column6 as City ,column7 as Code ,IDENTITY (int,1,1) AS LocationID INTO LocationDim FROM dbo.DataRaw GO
Step 5: Create the FactTemp table
This is the table with the main data from your system.
SELECT column6 AS City_ , CAST (0 AS INT) AS City , column7 AS Code_ , CAST (0 AS INT) AS Code , column9 AS State_ , CAST (0 AS INT) AS State , column2 AS Date_ , CAST (0 AS INT) AS DateID , column1 AS Precip , CAST (0 AS INT) AS LocationID , column10 AS TempAvg , column11 AS TempMax , column12 AS TempMin , column13 AS WindDir , column14 AS WindSpeed INTO FactTemp FROM DataRaw;
I’ve intentionally left the City, Code, and State columns in the table. A challenge for you – create a ‘CityDim’ and then update the City column in the FactTemp table, as if you were implementing a new Dim table. I’ll put the solution code further down in this article.
Step 6: Update FactTemp.
We want to update the two ID columns in FactTemp. These reflect the ID’s in the Dim tables. Notice how I make use of ‘placeholders’ here to create the LocationID and the DateID inside of the FactTemp table; these helper columns will be ignored later when we create the Fact table. I also use the degenerate dimension often while loading the Fact or FactTemp tables where needed, although this particular FactTemp table does not have one.
UPDATE FactTemp SET DateID = DateDim.DateKey FROM DateDim WHERE FactTemp.Date_ = DateDim.Date; GO ALTER TABLE LocationDim ADD PRIMARY KEY (LocationID); UPDATE FactTemp SET LocationID = d.LocationID FROM LocationDim d WHERE FactTemp.City_ = d.city AND FactTemp.code_ = d.code AND FactTemp.State_ = d.state;
Step 7: Update the FactTemp defaults.
We want to update FactTemp to both set the defaults and make the remaining columns ‘NOT NULL’. There should be no NULL values in our Fact Table. (Once early in my DW career I put the PKs in the fact – worked OK but was incorrect. Also, SQL Server allows only so many columns when creating a PK).
UPDATE FactTemp SET TempMax = 0 WHERE TempMax IS NULL; UPDATE FactTemp SET TempMin = 0 WHERE TempMin IS NULL; UPDATE FactTemp SET WindDir = 0 WHERE WindDir IS NULL; UPDATE FactTemp SET WindSpeed = 0 WHERE WindSpeed IS NULL; ALTER TABLE FactTemp ALTER COLUMN LocationID INT NOT NULL; ALTER TABLE FactTemp ALTER COLUMN DateID INT NOT NULL; ALTER TABLE FactTemp ALTER COLUMN Precip DECIMAL(5, 2) NOT NULL; ALTER TABLE FactTemp ALTER COLUMN TempMax TINYINT NOT NULL; ALTER TABLE FactTemp ALTER COLUMN TempMin SMALLINT NOT NULL; ALTER TABLE FactTemp ALTER COLUMN WindDir TINYINT NOT NULL; ALTER TABLE FactTemp ALTER COLUMN WindSpeed DECIMAL(5, 2) NOT NULL;
Step 8: Create the Fact table
We move data from FactTemp to Fact.
SELECT DateID , LocationID , Precip , TempMax , TempMin , WindDir , WindSpeed INTO Fact FROM FactTemp;
Step 9: Set the FK relationships
We add links from the Dims to the Fact table. The Primary Keys are in the Dim tables, no exceptions, and the foreign keys are in the Fact table.
ALTER TABLE Fact ADD CONSTRAINT FK_Location FOREIGN KEY (LocationID) REFERENCES LocationDim (LocationID); ALTER TABLE Fact ADD CONSTRAINT FK_Date FOREIGN KEY (DateID) REFERENCES DateDim (DateKey); UPDATE LocationDim SET State = 'Delaware' WHERE State = 'DE'; UPDATE LocationDim SET State = 'Virginia' WHERE State = 'VA';
You’ll notice that I don’t use indexes, or the TABLOCK hint with this relatively small dataset; use them judiciously with larger tables and big inserts/updates. Also, this is a traditional ‘star-schema’ design – originally, I had four Dims, but whittled this down to two Dims. If it were still four, you’d see the ‘star’ formed around the fact table.
Finally, note that we are loading this data mart from scratch. If we were to have a file with the next years data, our code would not work. At that point we would need to use more INSERT statements and make use of NOT EXISTS often.
--Solution to challenge
SELECT DISTINCT
Column6 AS City
, IDENTITY(INT, 1, 1) AS CityID
INTO CityDim
FROM DataRaw;
UPDATE FactTemp
SET City = CityDim.CityID
FROM CityDim
WHERE FactTemp.City_ = CityDim.City;
Our Fact table, with two dimensions and five measures.
Conclusion
I have shown in this article how to create a data mart. This is a minimalist one with two dimension tables and a fact table. This is neither anything to be particularly proud nor boastful about but does display many desirable traits of a multidimensional data mart, and it serves as a good tutorial that can be created easily in a Dev environment. I have stressed both speed of development and simplicity, especially when developing dim tables.
In my opinion, the Kimball DW is still needed for data analysis. There is nothing out there that matches the depth and breadth of data analysis that you can get from the traditional data mart. Whether you require this or not will have to be addressed. What is also needed is a new paradigm, a new approach, or a new way of thinking that will extend its life another thirty+ years. We need to speed up development and lower costs drastically and simplify development efforts of the data warehouse to compete with the many alternatives available to us.
About the Author
Lee Everest has been a SQL Server developer since 1998 and enjoys golf, fishing, and computers in his spare time.

