

Introduction
Azure Databricks is a data analytics platform optimized for the Microsoft Azure cloud services platform. Azure Databricks has three working environments:
- Databricks SQL
- Databricks Data Science & Engineering
- Databricks Machine Learning
Databricks SQL
A user can run quick ad-hoc SQL queries on a data lake with Databricks SQL. Queries support multiple visualization types to explore the query results from different perspectives. Dashboards help to combine visualizations and text to share insights drawn from the queries. Alerts are used to notify when a field returned by a query meets a threshold. Databricks SQL is in Preview mode as of October 2021.
Databricks Machine Learning
Databricks Machine Learning is an integrated end-to-end machine learning platform. Databricks Machine Learning is in Preview mode as of October 2021. The following activities can be performed using Databricks Machine Learning:
- Train models either manually or with AutoML. Databricks AutoML helps to automatically apply machine learning to a dataset.
- Track training parameters and models using experiments with MLflow tracking. MLflow tracking helps to log source properties, parameters, metrics, tags, and artifacts related to training a machine learning model.
- Create feature tables and access them for model training and inference. The Databricks Feature Store is a centralized repository of features. Features are organized as feature tables.
- Share, manage, and serve models using Model Registry. The MLflow Model Registry is a centralized model repository and a UI and set of APIs that enable to manage the full lifecycle of MLflow Models.
Databricks Data Science and Engineering
Databricks Data Science and Engineering is an analytics platform based on Apache Spark. Azure Databricks helps to read data from multiple data sources such as Azure Blob Storage, Azure Data Lake Storage, Azure Cosmos DB, or Azure SQL Data Warehouse and turn the data into breakthrough insights using Spark. Databricks Data Science and Engineering comprises the complete open-source Apache Spark cluster technologies and capabilities.
Implementation of Azure Databricks
I will discuss the step-by-step process for creation of a Azure Databricks resource and will process a data file using the Databricks Data Science & Engineering environment.
Create a Databricks resource
I go to the Azure portal and select the link for creating a new resource. I search for Azure Databricks and select that resource. In the next screen, I press the Create button to create the Azure Databricks resource.
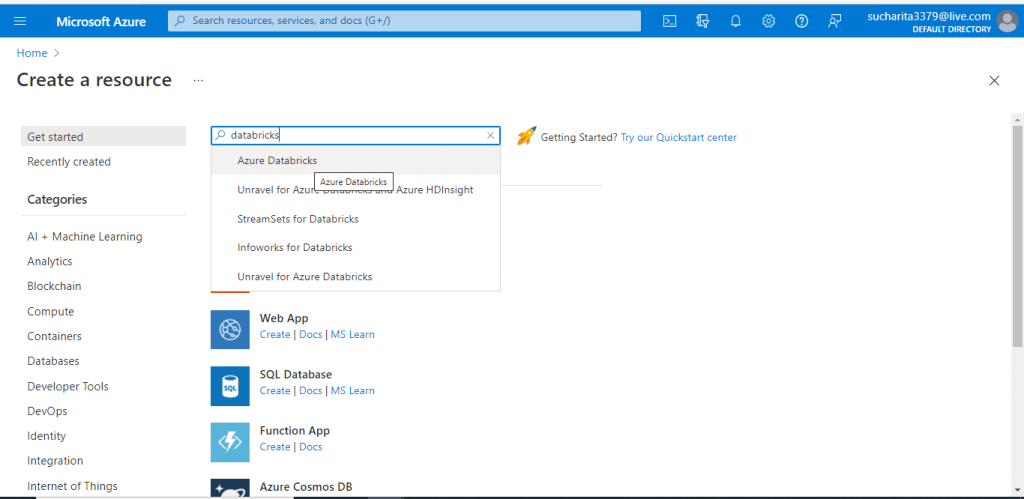
Create an Workspace
In the next screen, I need to provide the required details for creating the Azure Databricks workspace. A workspace is an environment for accessing all the Azure Databricks assets. A workspace organizes different objects like notebooks, dashboards etc. into folders and provides access to data objects and computational resources.
I give a name for the workspace and select the pricing Tier as Premium. There is another pricing tier known as Trial, which is valid for 14 days. When creating the Azure Databricks for the first time, the Trial pricing tier should be selected to save on costs.
I press the 'Review + Create' button.
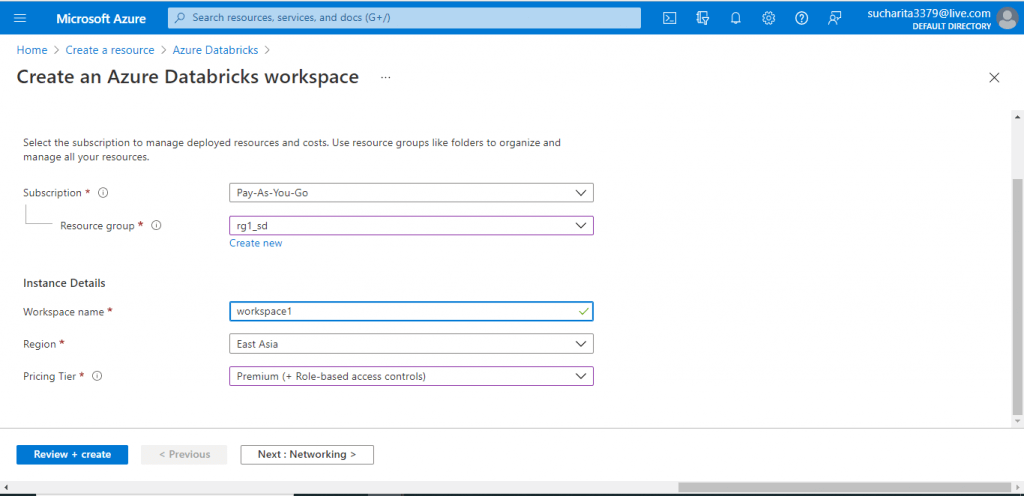
Launch Workspace
The Azure Databricks resource is now created. I am in the Overview page. I click on the 'Launch Workspace' button.
Select the environment
A new window is open for the Databricks Workspace. Three environments are available and the required environment should be selected before proceeding with the work. Data Science & Engineering is the default environment. I select the default environment.
Create a Cluster
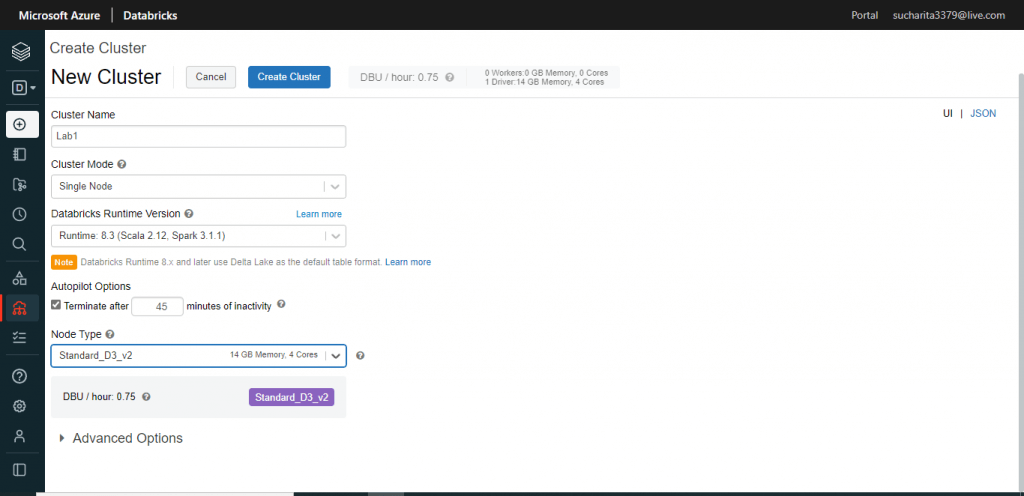
I press the Create button just below the environment and select Cluster. A new window is open where I need to provide the details about the new cluster. An Azure Databricks cluster is a set of computation resources and configurations. Data engineering, data science, and data analytics workloads are executed on a cluster. There are two types of clusters. All-purpose clusters are used to analyze data collaboratively using interactive notebooks. Job clusters are used to run fast and robust automated jobs.
I provide a name for the new cluster. Cluster mode is selected as 'Single Node'. For rest of the fields, I go with the default options. I press the 'Create Cluster' button.
Create a Notebook
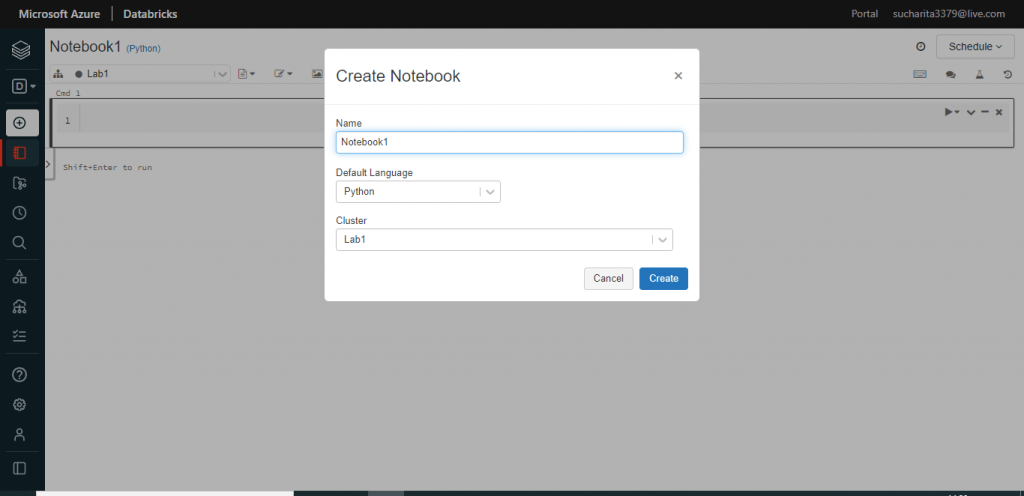
I press the Create button again to create a new notebook. A notebook is a web-based interface to a document that contains runnable code, visualizations, and narrative text.
I provide a name for the notebook and select the default language as Python. Other language choices are also available. Then, I attach the cluster Lab1 with the notebook. I can attach a cluster with the notebook later as well before executing any code. I press the Create button.
Import a CSV file from local drive
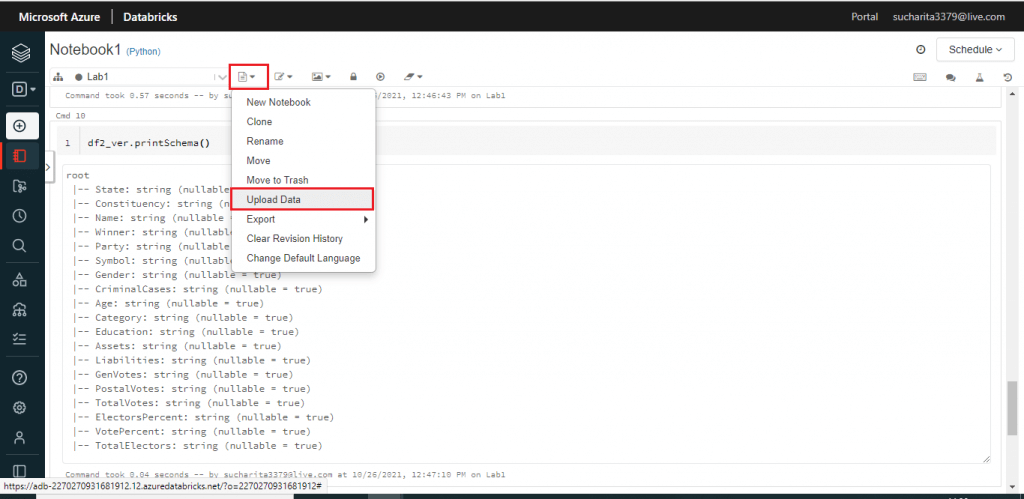
After the notebook is created, I select the 'Upload Data' option from the Notebook Toolbar item drop down.
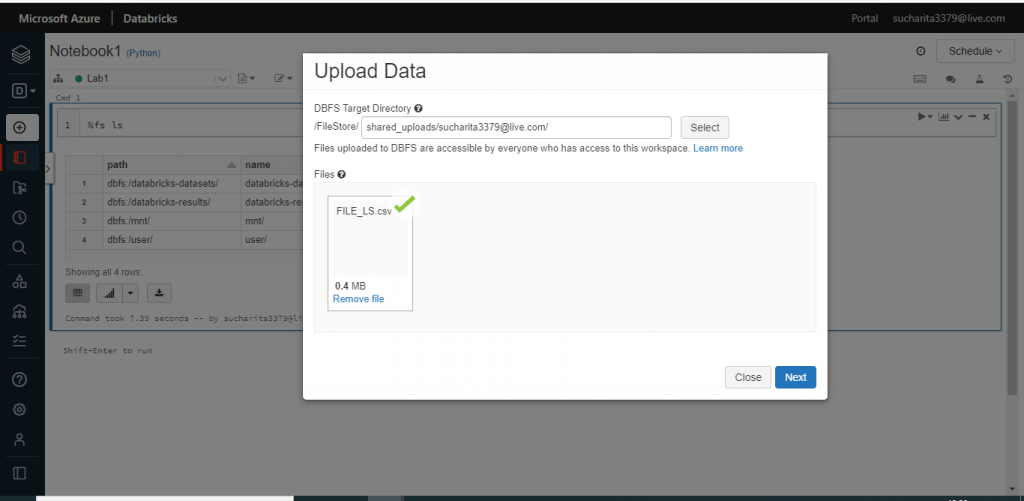
One pop-up window is open. DBFS Target Directory is shown here. I may change the target directory, if required. Then, I browse my local drive and select a file named FILE_LS.csv. Once, the upload is completed, I press the Next button.
The Databricks File System (DBFS) is a distributed file system mounted into an Azure Databricks workspace and available on the Azure Databricks clusters. The default storage location in DBFS is known as the DBFS root. Several types of data are stored in the following DBFS root locations:
- /FileStore: Imported data files, generated plots, and uploaded libraries.
- /databricks-datasets: Sample public datasets.
- /databricks-results: Files generated by downloading the full results of a query.
- /databricks/init: Global and cluster-named (deprecated) init scripts.
- /user/hive/warehouse: Data and metadata for non-external Hive tables.
The format for the uploaded file and the notebook type are selected with the default values. I press the Done button.
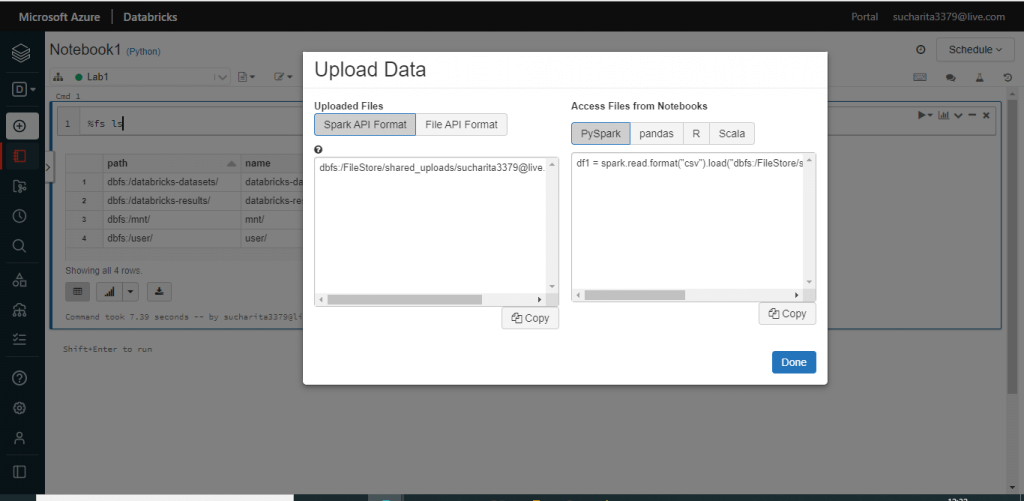
Execute commands in the notebook
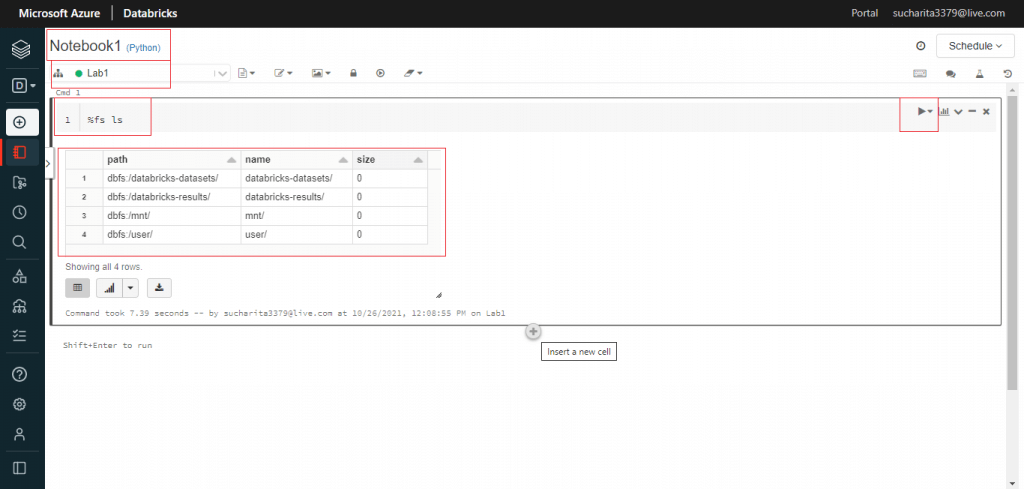
Before uploading the file, I write the following command and press the 'Run Now' link. The output shows the current DBFS structure.
%fs ls """ pathnamesize dbfs:/databricks-datasets/databricks-datasets/0 dbfs:/databricks-results/databricks-results/0 dbfs:/mnt/mnt/0 dbfs:/user/user/0 """
After uploading the file, I write the same command and execute. This time the new folder named FileStore is also available in the folder listing.
%fs ls """ pathnamesize dbfs:/FileStore/FileStore/0 dbfs:/databricks-datasets/databricks-datasets/0 dbfs:/databricks-results/databricks-results/0 dbfs:/mnt/mnt/0 dbfs:/user/user/0 """
I use the following ls command to view the uploaded CSV files in the FileStore folder.
%fs ls /FileStore/shared_uploads/sucharita3379@live.com/ """ pathnamesize dbfs:/FileStore/shared_uploads/sucharita3379@live.com/FILE_LS.csvFILE_LS.csv393620 dbfs:/FileStore/shared_uploads/sucharita3379@live.com/FILE_heart.csvFILE_heart.csv11328 """
I use the head command on the file to view the first few records of the CSV file as uploaded in the FileStore folder.
%fs head /FileStore/shared_uploads/sucharita3379@live.com/FILE_LS.csv """ [Truncated to first 65536 bytes] State,Constituency,Name,Winner,Party,Symbol,Gender,CriminalCases,Age,Category,Education,Assets,Liabilities,GenVotes,PostalVotes,TotalVotes,ElectorsPercent,VotePercent,TotalElectors Telangana,ADILABAD,SOYAM BAPU RAO,1,BJP,Lotus,MALE,52,52,ST,12th Pass,"Rs 30,99,414 ~ 30 Lacs+","Rs 2,31,450 ~ 2 Lacs+",376892,482,377374,25.33068419,35.4682479,1489790 Telangana,ADILABAD,Godam Nagesh,0,TRS,Car,MALE,0,54,ST,Post Graduate,"Rs 1,84,77,888 ~ 1 Crore+","Rs 8,47,000 ~ 8 Lacs+",318665,149,318814,21.39992885,29.96436953,1489790 Telangana,ADILABAD,RATHOD RAMESH,0,INC,Hand,MALE,3,52,ST,12th Pass,"Rs 3,64,91,000 ~ 3 Crore+","Rs 1,53,00,000 ~ 1 Crore+",314057,181,314238,21.09277146,29.53428505,1489790 """
I create a DataFrame named df2 from the CSV file data. In the output of the command, I can see that one Spark Job is executed to create and populate the DataFrame. A DataFrame is a two-dimensional labeled data structure with columns of potentially different types.
df2 = spark.read.format("csv").load("dbfs:/FileStore/shared_uploads/sucharita3379@live.com/FILE_LS.csv")
"""
(1) Spark Jobs
Job 1 View(Stages: 1/1)
Stage 1: 1/1
df2:pyspark.sql.dataframe.DataFrame = [_c0: string, _c1: string ... 17 more fields]
"""I use the printSchema() function to view the Schema of the DataFrame df2. All the columns are listed with the datatype and the Nullable property. The columns are named as _c0, _c1, _c2 and so on.
df2.printSchema() """ root |-- _c0: string (nullable = true) |-- _c1: string (nullable = true) |-- _c2: string (nullable = true) |-- _c3: string (nullable = true) """
I use the display() function on the DataFrame to view the first few records of the DataFrame. The column headers are mentioned as _c0, _c1 etc. and the actual headers of the file (State, Constituency etc.) are displayed as the first record of the file.
display(df2) """ (1) Spark Jobs Job 2 View(Stages: 1/1) _c0_c1_c2_c3_c4_c5_c6_c7_c8_c9_c10_c11_c12_c13_c14_c15_c16_c17_c18 StateConstituencyNameWinnerPartySymbolGenderCriminalCasesAgeCategoryEducationAssetsLiabilitiesGenVotesPostalVotesTotalVotesElectorsPercentVotePercentTotalElectors TelanganaADILABADSOYAM BAPU RAO1BJPLotusMALE5252ST12th PassRs 30,99,414 nullnullnullnullnullnullnull """
I create another DataFrame named df2_ver from the CSV file named File_LS.CSV. This time I use the option() function to retrieve the header from the file and use as the DataFrame columns.
While executing the printSchema() function on df2_ver DataFrame, I can see the actual file headers are used as DataFrame columns instead of the default _c0, _c1 values.
df2_ver = spark.read.format("csv").option('header',
'true').load("dbfs:/FileStore/shared_uploads/sucharita3379@live.com/FILE_LS.csv")
df2_ver.printSchema()
"""
root
|-- State: string (nullable = true)
|-- Constituency: string (nullable = true)
|-- Name: string (nullable = true)
|-- Winner: string (nullable = true)
|-- Party: string (nullable = true)
|-- Symbol: string (nullable = true)
|-- Gender: string (nullable = true)
|-- CriminalCases: string (nullable = true)
|-- Age: string (nullable = true)
|-- Category: string (nullable = true)
"""Conclusion
The Databricks Unified Data Analytics Platform enables data teams to collaborate in order to solve some of the world’s toughest problems. Databricks provides a notebook-oriented Apache Spark as-a-service workspace environment, making it easy to manage clusters and explore data interactively. Azure Databricks provides data science and engineering teams with a single platform for Big Data processing and Machine Learning. In this article, I created the basic components of a Azure Databricks resource and got familiar with the file data processing. I will explore other features and commands for Azure Databricks in the upcoming articles.