

A Reporting System Architecture
The Classic OLTP\OLAP Problem
Over the past some years as a developer and database wonk, I have worked at numerous companies. Every time I change jobs, it seems that I am faced with the same classic OLTP\OLAP delimma; the current OLTP system is experiencing performance degredation due to the fact that it is also being used to support reporting needs.
To solve this problem, someone brilliantly comes up with the idea of creating a "reporting" database to support the reporting needs. A simple solution in theory, but not nearly as simple in practice.
I've now been involved in these types of tasks numerous times and am always suprised at how non-trivial it is to setup correctly. My most recent reporting project involved the following working constraints:
- No performance impact to current production OLTP transactions
- Maximum of 15 minute lag time between reporting system and transactional system
- Dramatic improvement of report performance
- Cannot use SQL Server Reporting Services (don't ask why)
- OLTP system must be purged on a regular basis
- Reporting database must not be purged
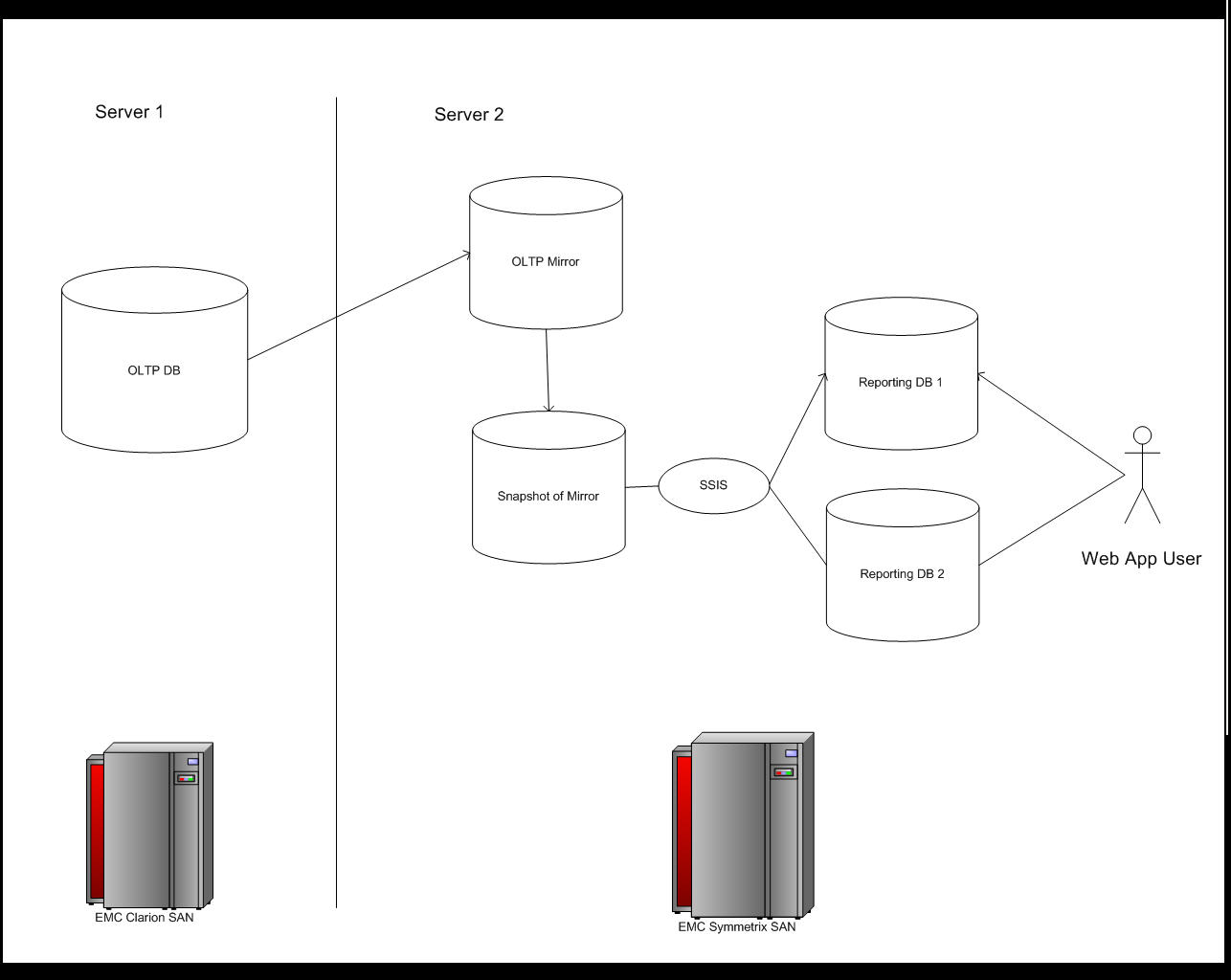
These seemingly simple requirements added more complexity to the project than one might think. We mulled over numerous ideas and varying solutions to satisfy the business needs. Our final solution involved the use of a staging database setup on the reporting server (a seperate box) that is populated via SQL Server mirroring. ETL Scripts are then written in SSIS that utilize a snapshot of the mirror database to denormalize the data and populate two reporting databases (details below). The solution turns out to be elegant, to perform well and has basically zero negative impact on the current OLTP system.
Copying OLTP Data To Reporting Server
The first step in our problem is getting new data from the OLTP system into the reporting database(s). This was complicated by the fact that we had to migrate record inserts, and record edits but we did not want to migrate record deletions. Data is never to be deleted from the reporting system (at least not yet).
In order to migrate these various data changes to the reporting system, our initial thought was to use SSIS to pump data directly out of the OLTP system and right into the reporting database (sounds simple enough). However, our primary concern was the health and performance of the transactional database. Remember, a critical requirement was that the performance of the OLTP system could not be negatively impacted. If we were to write SSIS packages that read directly from the OLTP database, we would be taxing the OLTP system unnecessarily and would compete for resources on the OLTP box. Not only would we have to worry about record locking issues on the data itself, we would also have to worry about competing for IO resources, RAM, CPU, etc. These concerns prompted us to create a staging database on a seperate physical box so that we could then use the staged data as the source for our ETL extracts. This solution effectively alleviated any contention with the OLTP environment.
Once we were able to get a staging database setup on the "Reporting Server", the next question then, was how to get the staged data copied over on a regular basis. We considered various options including restored backups, log shipping, replication and finally SQL Server 2005 mirroring. Each of the alternatives posed their own specific issues and the debates here lengthy and heated. We ultimately decided on SQL Server Mirroring due to its low impact on the OLTP system, its ease of setup and its ease of maintenance.
Mirrored databases - Unavailable
Once we got the mirrored database in place, working and synchronizing, to my suprise, we found that the target database in a mirrored configuration is not available for use (not even for read only use). This suprised me and I thought we were in trouble with our architecture until I discovered the new Database Snapshot feature in SQL Server 2005. With the Database Snapshot feature, even though the mirror itself was unavailable for use, I could take a snapshot of the mirrored database and use the snapshot as the source for our ETL jobs.
To create a snapshot of an existing database, you just use the CREATE DATABASE T-SQL statement as follows:
CREATE DATABASE MySnapshot ON
(
NAME = Snapshot_Data,
FILENAME = H:\Data\Snapshot\MySnapshot_data.ss'
)
AS SNAPSHOT OF MySourceDB
Every time we run the ETL Scripts, we just re-create the snapshot. This is a very fast operation even though our database is a fairly sizable 50GB.
ETL and Contention Issues
Another major concern of ours was the complexity of the business logic placed in our ETL Jobs. The logic is very complex, very CPU intensive and very IO intensive. The fear was the availability and performance of the reporting database while it was being loaded\updated (remember, our ETL scripts have to run every 15 minutes to keep the reporting system in synch with the OLTP data). I was very worried that users or our reports would experience contention issues when running complex reports against this system.
In order to relieve this pressure, we decided to create 2 seperate reporting databases on the reporting server; "ReportingDB1" and "ReportingDB2". By having seperate databases, we would alleviate blocking issues between our ETL jobs and people running reports. Although we didn't have money in the budget for seperate physical servers, we could seperate these 2 databases on seperate Luns on the SAN to at least relieve IO contention.
The architecture includes logic in the ETL loaders to keep track of the 2 database statuses. One database is always "live" and the other is always "loading". The 2 databases are updated in round robin fashion every 15 minutes. The reporting UI also monitors these status values to determine which of the two databases to point to when a user requests a report.
In the future, if budgets allow, we can easily move one or both of the databases to it's own box.
The Swap Logic
The swapping logic is quite simple, we have a ReportingAdmin database that keeps track of various statistics in our reporting system. The most important piece of data stored here is "ActiveReportingDB" this is a bit value where a 0 indicates that ReportingDB1 is live and a 1 indicates that ReportingDB2 is live. The first thing that the ETL jobs do is look at this value to determine which database to run updates against. Then, as the ETL jobs start to spin up transactions, they toggle the value accordingly so that the reporting UI will redirected to the new "live" database.
Resulting Architecture
Our Resulting architecture looks as follows:
Issues to consider
Record Deltas
One of the challenges was in determining what data had to be migrated from the OLTP system and into the Reporting system with each ETL iteration. This turned out to be fairly simple. We just had to add auditing columns (CreateDate, and LastEditDate) to every table in the OLTP system. These columns were not in place prior to this endeavor so we had concerns that adding columns could break middle tier code. Luckily all of our code was protected due to the use of Stored Procedures and the impact here was minimal. Once we put the auditing columns in place, our ETL logic then would look at the values in these columns and compare them to the last known run date of the ETL jobs and would act accordingly.
ETL Load
If you've never used DTS or SSIS before please beware. There is a large learning curve to it. using these tools is kind of like boxing. Anyone can throw a pair of gloves on and jump into the ring with little or no training. Howver, it takes a long time to get good at it and getting your butt kicked while learning really sucks. Let's just say, we got punched in the gut on more then one occasion even though I have had years of experience with DTS (We used SSIS). Some of the issues we ran into were fixed with SP2 of SQL Server 2005.
IO IO IO
The completion of data intensive ETL jobs is greatly the function of IO resources. Certainly our ETL jobs are CPU intensive as well. But, the bottleneck for us is always IO. I cannot stress enough that you really need to plan accordingly for the IO load when architecting this type of system. Currently our architecture is holding its own in production, but the IO subsystem (an EMC Symmetrix SAN) is really kicking up a sweat. Do your research on SQL Server file layout best practices and work with your IO system vendor for best practices and optimization.
Summary
Creating a reporting system to alleviate load in your OLTP environment is one of the most common requests in the life of a DBA or Data Architect. There's no single solution as to how to do this. You cant just click an "Easy Button" in SQL Server and have your reporting environment all setup for you. My hope in writing this article is to describe one solution in order to get you heading in the direction of implementing your own custom solution. I look forward to the numerous "why didn't you use replication" questions and other questions\recommendations. I look forward to the feedback on how to improve what we have....maybe version 2 of our reporting system will be even better.
