

Microsoft Fabric is their fourth version of a Data Warehouse. Back in September of 2008, Microsoft bought DATAllegro for its intellectual property. The first product was called SQL Server Parallel Data Warehouse which came with a purchase of both hardware and software. This MPP paradigm worked with distributing the data into 60 files. The data architect had to decide on a way to spread the data over the processing nodes (round robin, hash, replicate) and how to index the data (heap, clustered index, clustered column store index). Please see the create table syntax for details. The second product release was called Azure Data Warehouse and was release in July 2016. The third release of the product in November of 2019 was called dedicated pools in Azure Synapse Analytics. The most recent release of the product is Fabric Data Warehouse in November of 2023.
Business Problem
Our manager has asked us to research the new and improved Data Warehouse in Microsoft Fabric.
Technical Solution
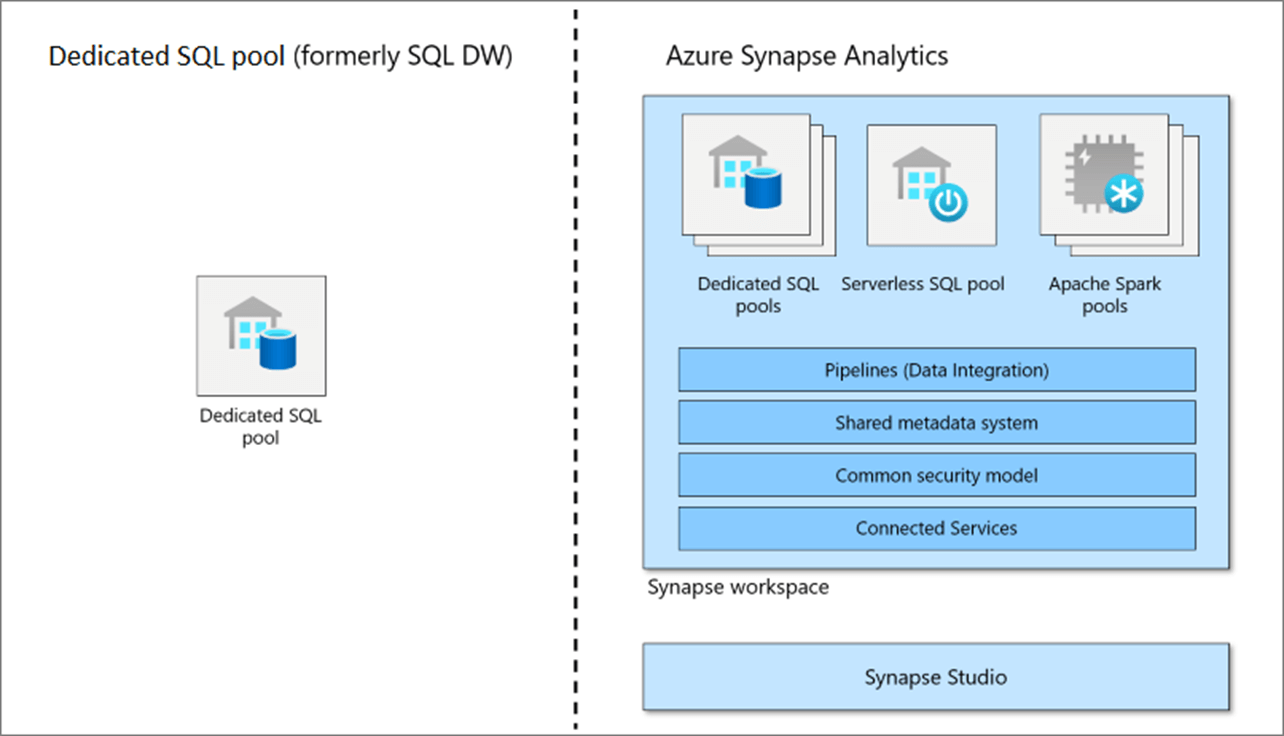
In this article, we are going to migrate the PUBS database from SQL Server to Fabric Data Warehouse. The nice thing about the four release of the data warehouse product is the fact that the developer does not have to worry about distributing the data like in the past. The image below shows Azure Synapse Analytics. We can see both a dedicated and serverless pool in the diagram. I have used the serverless pool with clients to allow for a TSQL interface to the Data Lake.
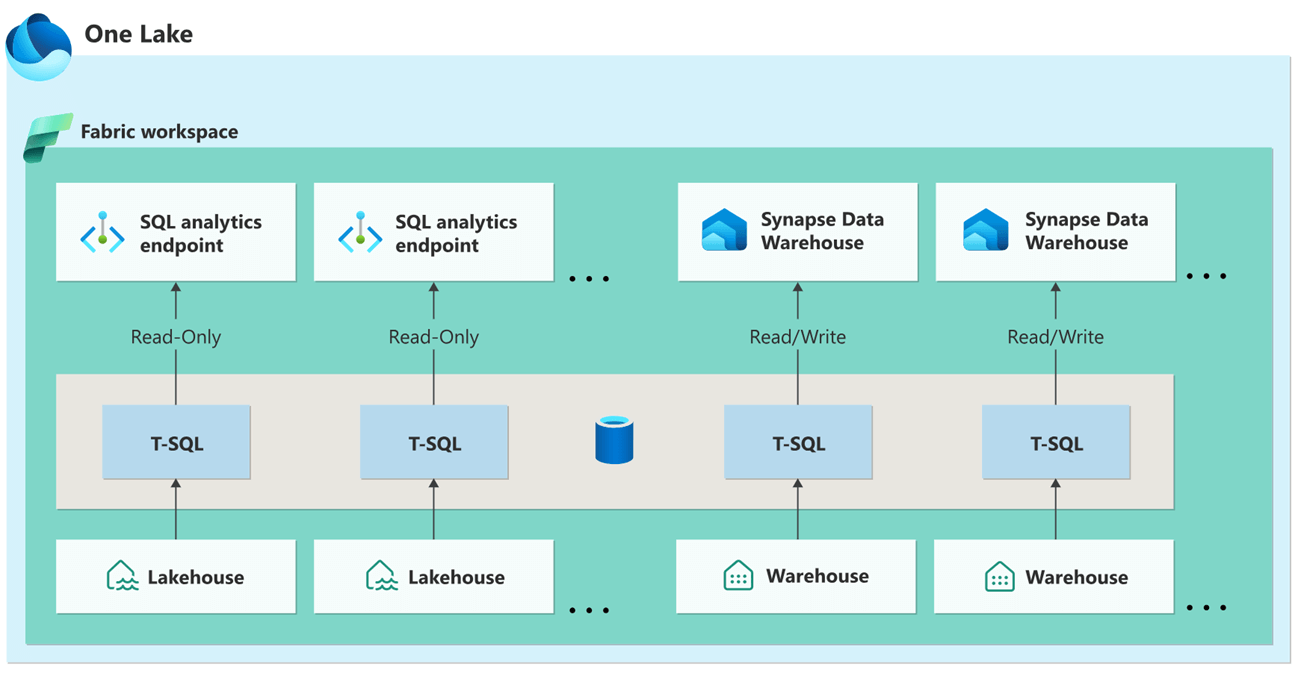
The image below shows the OneLake Fabric Workspace. First, all managed Spark and Warehouse tables are stored in delta lake format. Second, there is no need to worry about data distribution. Third, since we are using the delta file format, we could time travel up to 7 days in the past which is the default. Fourth, the SQL endpoint is read-only for the Lakehouse and read/write for the Warehouse.
Data Types
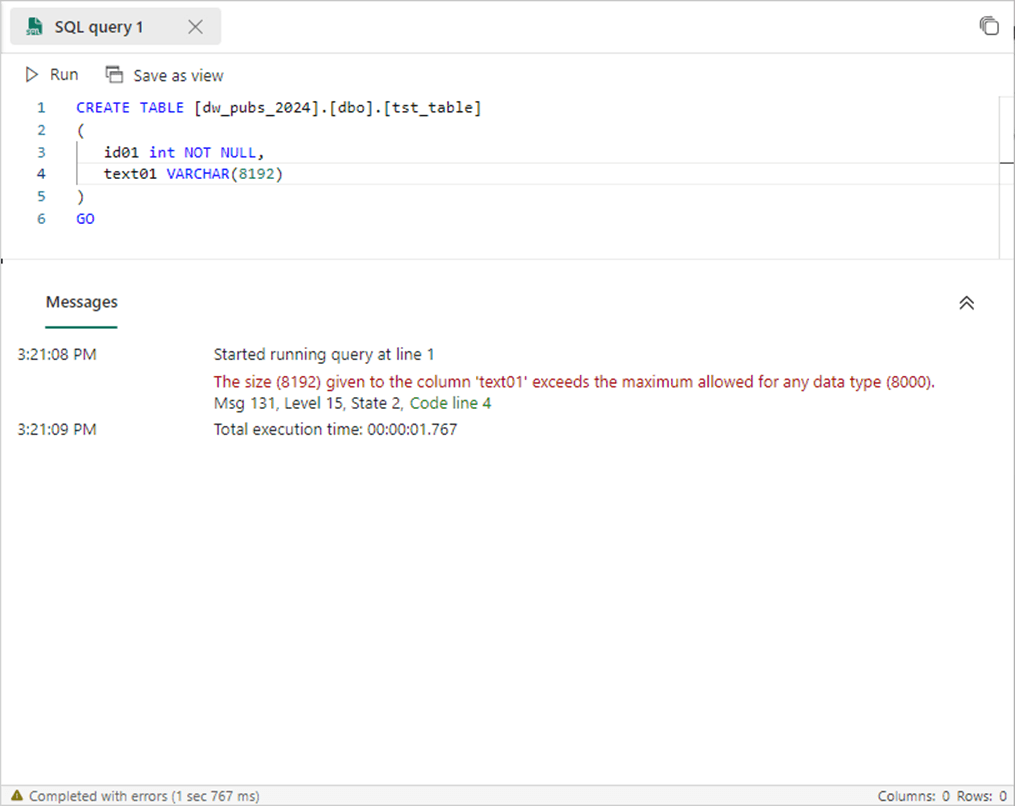
Just remember that OneLake is based upon the delta file format which uses parquet files. Thus, we are limited to the data types and sizes supported by Parquet. By default, the UTF-8 encoding is used when storing text. The image below shows me creating a test table in the PUBs database. We can see that a text field is limited to 8000 characters. There is no support for varchar max or var-binary max.
Please refer to the Microsoft documentation for more details on supported types. I am enclosing an image from the MS Learn site that has the DELTA to SQL data type mapping.
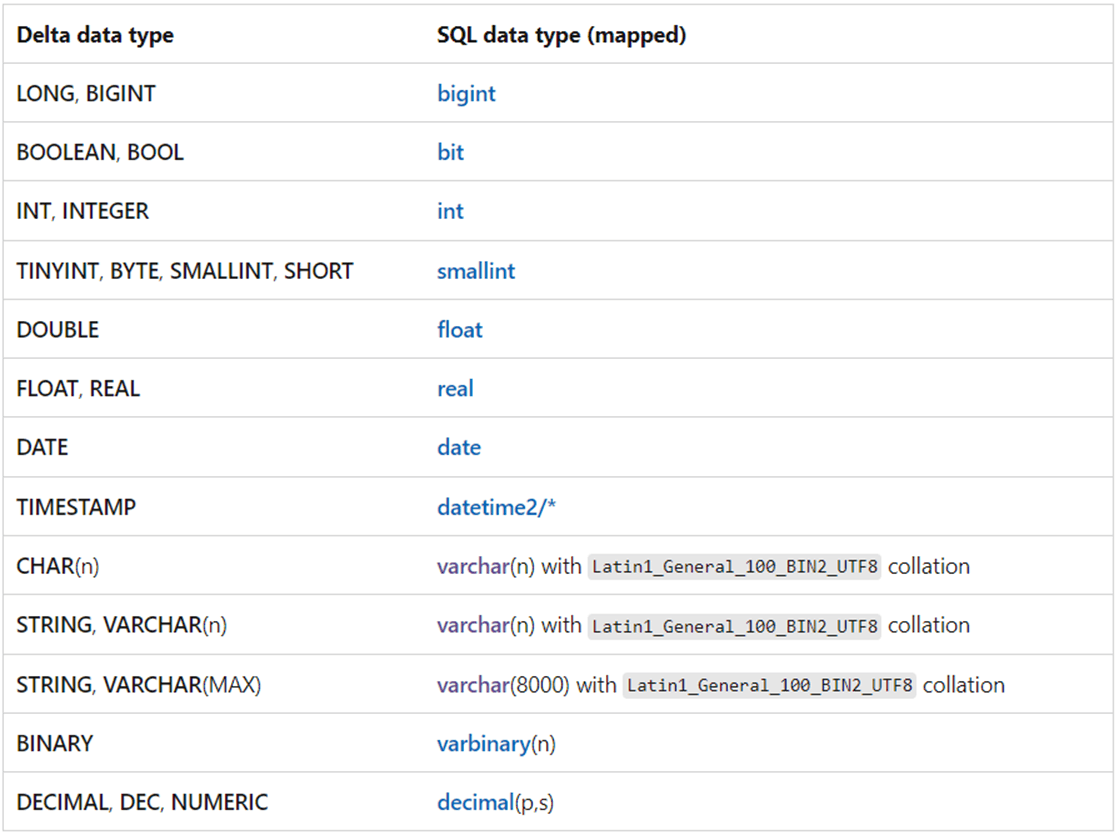
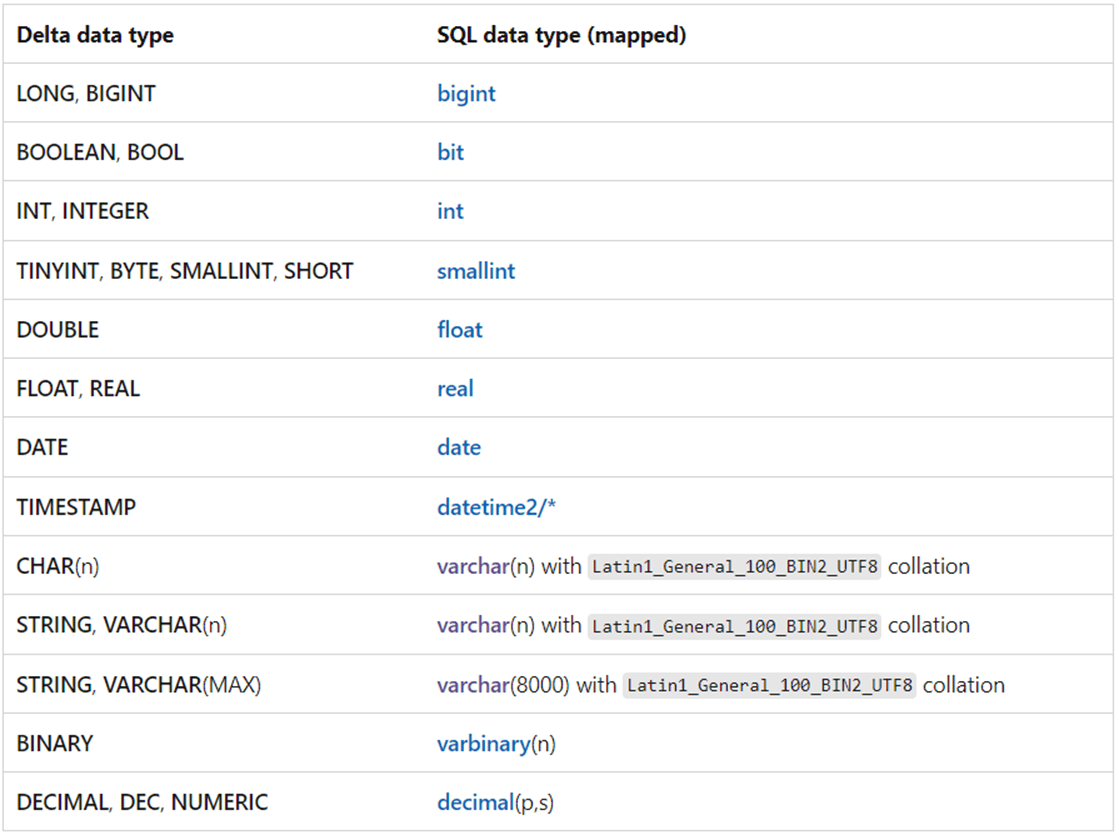
Create a Data Warehouse
Everything in Microsoft Fabric is centered around the workspace concept. If we click the new button, we can add a Warehouse object. I am going to add the dw_pubs_2024 Warehouse to the ws-ssc-article workspace.

If we look at the workspace, we can see a deployment of both the new Warehouse and old Lakehouse.
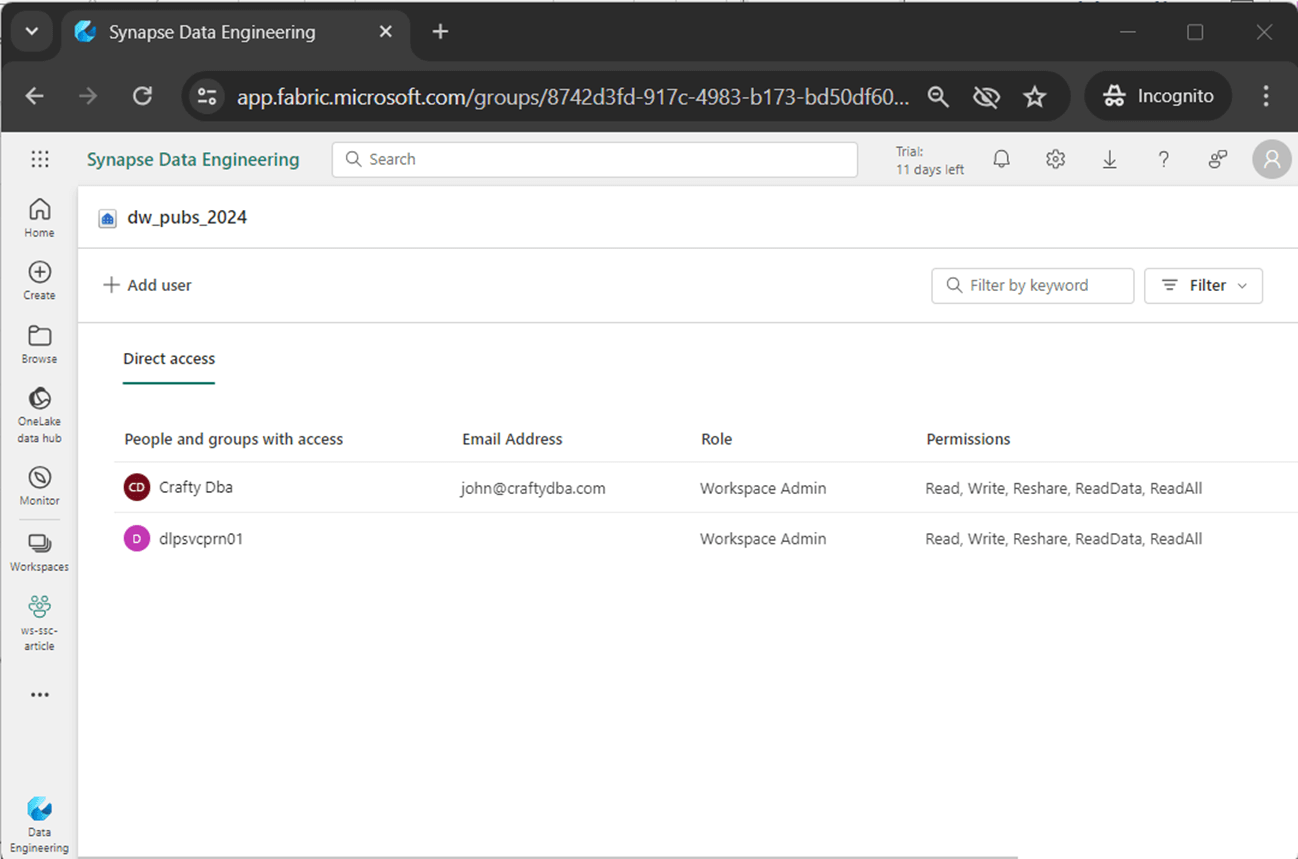
Right click the Warehouse name to grant permissions to AD users in your tenant. The following MS Learn documentation gives more details. The image below shows my user account – john@craftydba.com and the service principle dlpsvcprn01 have workspace admin rights.
To apply permissions at the database (schema) level, we can add the user dilbert@craftydba.com as just a reader. Then use the GRANT, REVOKE, and DENY statements to modify permissions.
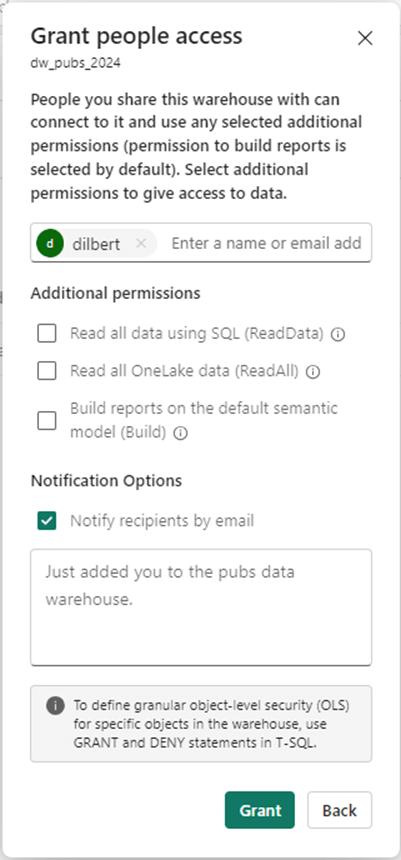
Creating Tables and Inserting Rows
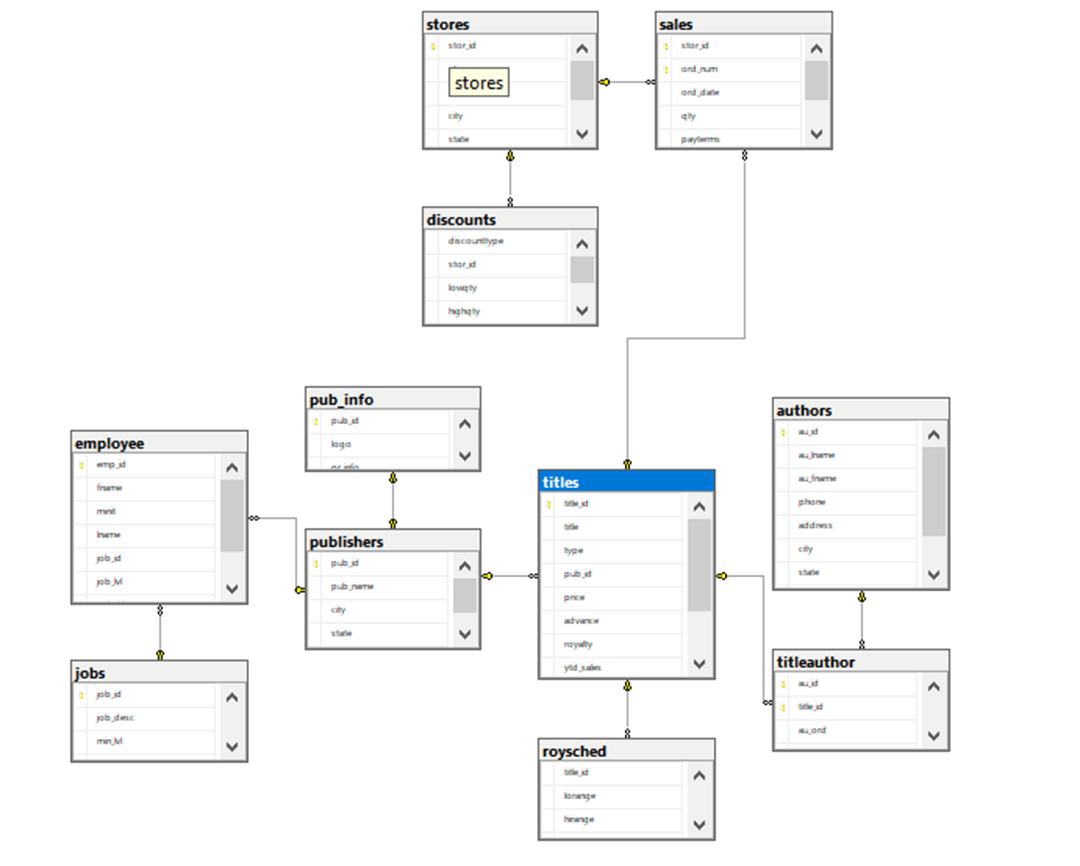
The first time I worked with the PUBS database was with the release of SQL Server 7.0. Here is the GitHub site with a copy right of 1994 to 2000 within the SQL Script. I want to thank Ronen Ariely for providing an Entity Relationship Diagram. The first rule of the warehouse is “relational constraints are not enforced”!
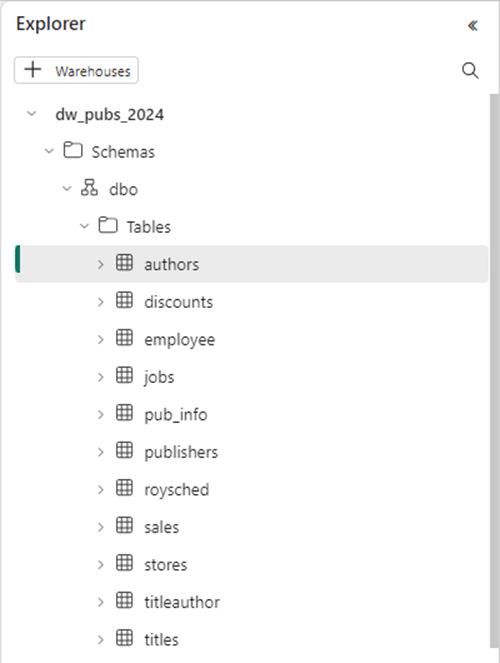
The image below shows the eleven tables in the dbo schema. Please see the T-SQL script at the end of the article for the complete code to create the database objects and insert data into the tables.
The T-SQL code below creates the [authors] table. Most of the syntax from SQL Server is supported. However, the primary key is not enforced.
--
-- create table - authors
--
DROP TABLE IF EXISTS authors;
GO
CREATE TABLE authors
(
au_id varchar(11) NOT NULL,
au_lname varchar(40) NOT NULL,
au_fname varchar(20) NOT NULL,
phone char(12) NOT NULL,
address varchar(40) NULL,
city varchar(20) NULL,
[state] char(2) NULL,
zip char(5) NULL,
contract bit NOT NULL
)
GO
ALTER TABLE authors ADD CONSTRAINT UPKCL_auidind PRIMARY KEY NONCLUSTERED (au_id) NOT ENFORCED;
GO
RAISERROR('... created authors table', 0, 1)
GO
The T-SQL code below creates the [titleauthor] table. This table has one primary key and two foreign key constraints. All three constraints are not enforced. The RAISERROR statement writes a message to the output window in Fabric.
--
-- create table - titleauthor
--
DROP TABLE IF EXISTS titleauthor;
GO
CREATE TABLE titleauthor
(
au_id varchar(11) NOT NULL,
title_id varchar(6) NOT NULL,
au_ord smallint NULL,
royaltyper int NULL
)
GO
ALTER TABLE titleauthor ADD CONSTRAINT UPKCL_taind PRIMARY KEY NONCLUSTERED (au_id, title_id) NOT ENFORCED;
GO
ALTER TABLE titleauthor ADD CONSTRAINT FK_titleauthor_2_authors FOREIGN KEY (au_id) REFERENCES authors (au_id) NOT ENFORCED;
GO
ALTER TABLE titleauthor ADD CONSTRAINT FK_titleauthor_2_titles FOREIGN KEY (title_id) REFERENCES titles (title_id) NOT ENFORCED;
GO
RAISERROR('... created titleauthor table',0,1)
GO
The second rule of the warehouse is “singleton data manipulation statements are not optimal”. On the other hand, large batches of inserts that fail must be rolled back. Just remember that the underlying storage mechanism is a delta file. If we do 1000 inserts one at a time, we create a bunch of parquet and logs files. If we execute a batch of 1000 inserts, we create one parquet and one log file.
In a future article, we will talk about different ways to load data into the Fabric Warehouse. Today, I am going to show a couple insert statements that might be of interest.
--
-- insert rows - authors
--
delete from authors;
GO
insert authors
values('409-56-7008', 'Bennet', 'Abraham', '415 658-9932',
'6223 Bateman St.', 'Berkeley', 'CA', '94705', 1);
insert authors
values('213-46-8915', 'Green', 'Marjorie', '415 986-7020',
'309 63rd St. #411', 'Oakland', 'CA', '94618', 1);
GO
-- msg window
RAISERROR('... authors table now has data.',0,1)
GO
The above code removes any data in the [authors] tables before inserting new rows. This example shows the first two insert statements. Please note, three different batches are being used.
--
-- insert rows - titles
--
delete from titles;
GO
insert titles values ('PC8888', 'Secrets of Silicon Valley', 'popular_comp', '1389',
$20.00, $8000.00, 10, 4095,
'Muckraking reporting on the world''s largest computer hardware and software manufacturers.',
'06/12/94');
insert titles values ('BU1032', 'The Busy Executive''s Database Guide', 'business',
'1389', $19.99, $5000.00, 10, 4095,
'An overview of available database systems with emphasis on common business applications. Illustrated.',
'06/12/91');
GO
-- msg window
RAISERROR('... titles table now has data.', 0, 1)
GO
If you have not looked at the T-SQL language reference lately, the PUBS database script has constants for both MONEY and BINARY types. These are fully supported within the Fabric Warehouse.
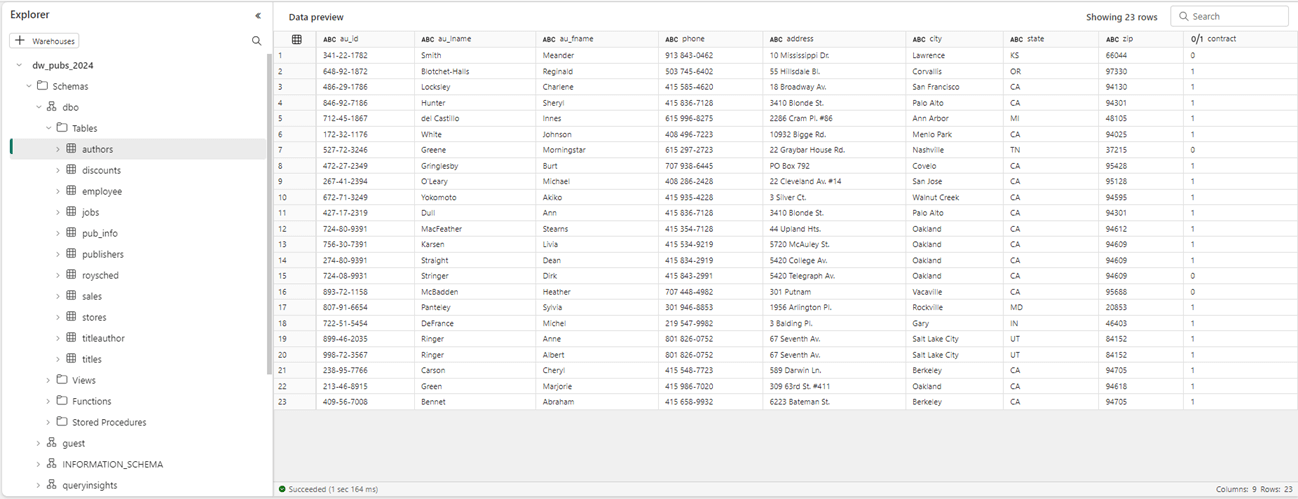
One of the nice features of the Warehouse Explorer is the data previewer. The above image shows the 23 rows in the [authors] table. For performance considerations, only ten thousand rows are returned within the SQL query editor. Use another tool such as SSMS if you need to view more data.
Other Database Objects
The PUBS database contains one view and three stored procedures. This code was migrated to Fabric Data Warehouse with ease. The code below is written with ANSI-89 JOIN syntax. If I was porting this code to Fabric for real, I would re-write with the newer JOIN ON syntax. See bad habits to kick article from Aaron Bertrand for details.
-- -- stored code - title - view -- -- drop existing DROP VIEW IF EXISTS titleview GO -- create new CREATE VIEW titleview AS select title, au_ord, au_lname, price, ytd_sales, pub_id from authors, titles, titleauthor where authors.au_id = titleauthor.au_id AND titles.title_id = titleauthor.title_id GO
The Fabric interface allows the developer to create queries. They are automatically saved to the “My Queries” section of the explorer. This sometimes can be a pain if we are writing a temporary query that is going to be discarded. The query named “qry-test-view” executes a simple select statement against the above view. The results are show below. Two new options are available to the data engineer. We can save the results as a new table or open the results in MS Excel.
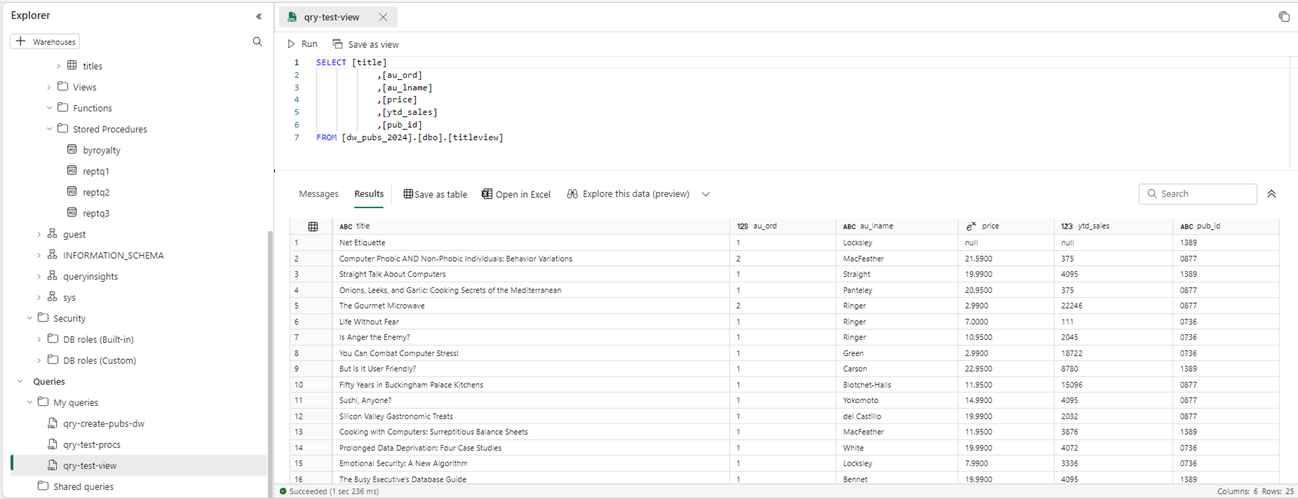
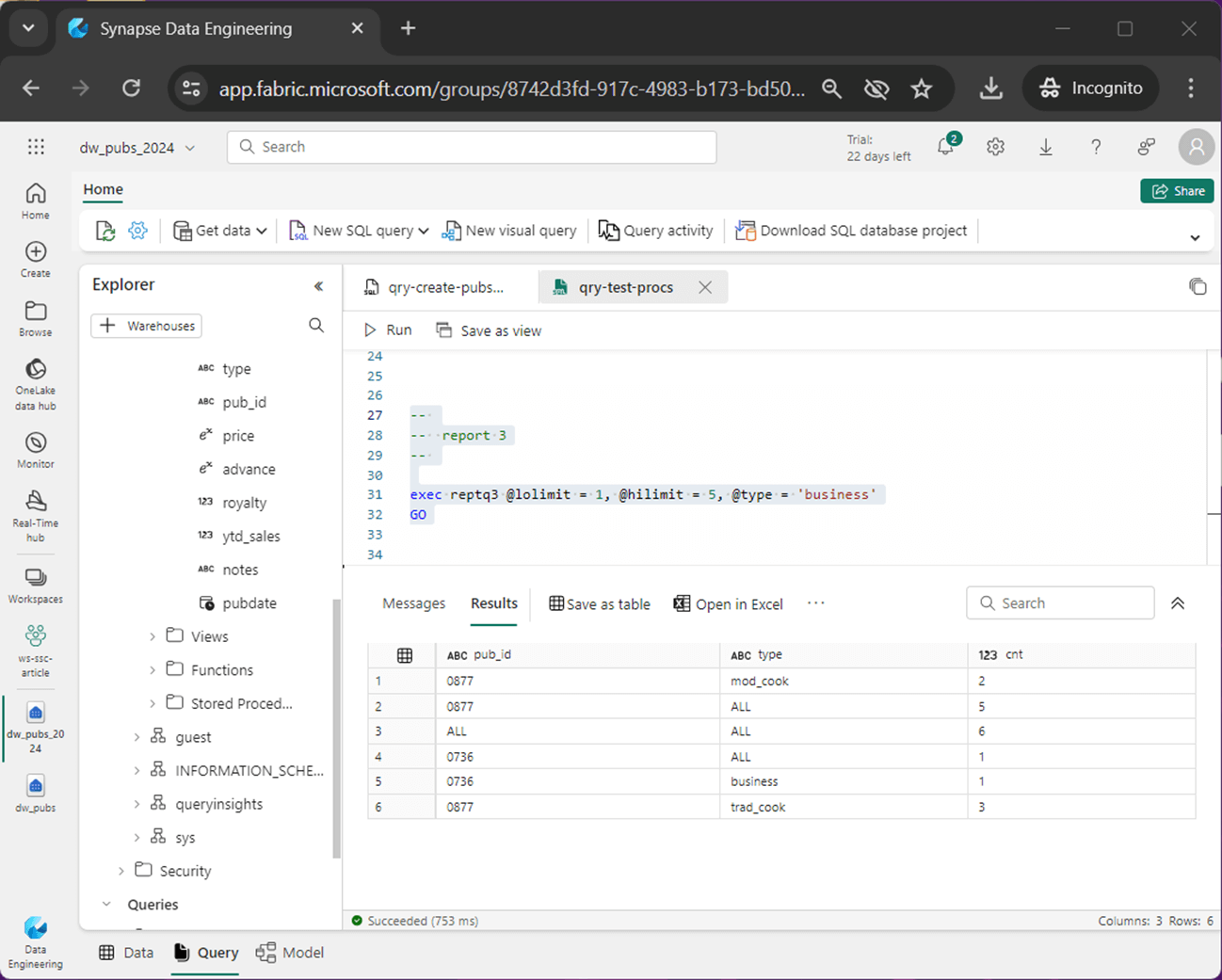
The PUBS database has three stored procedures. The one called reptq3 is the only one that takes input parameters. The low limit, high limit and type are used to filter the data before it is rolled up for reporting.
-- -- stored code - reptq3 - stored procedure -- -- drop existing DROP PROCEDURE IF EXISTS reptq3 GO -- create new CREATE PROCEDURE reptq3 @lolimit money, @hilimit money, @type char(12) AS select case when grouping(pub_id) = 1 then 'ALL' else pub_id end as pub_id, case when grouping(type) = 1 then 'ALL' else type end as type, count(title_id) as cnt from titles where price >@lolimit AND price <@hilimit AND type = @type OR type LIKE '%cook%' group by pub_id, type with rollup GO
The output below shows a sample execution of the stored procedure. What interests me is the output window. It kind of looks like Power BI in which the data types are displayed before the column names. For instance, the “ABC” refers to a string format and the “123” represents a numeric format.
To complete the object coverage, you will probably want to use SCHEMAS to group related tables and apply security at this level. Fabric only supports in-line FUNCTIONS that return a table data type. What you will not find is an INDEX statement. However, STATISTICS are still important and should be updated.
Summary
I am truly excited about the release of Microsoft Fabric Data Warehouse. The T-SQL coverage is adequate to allow a data engineer to port the PUBS database created a quarter of a century ago into Microsoft’s newest Warehouse offering. The best part is not worrying about how to distribute and index the data into N files. The lack of support for constraints and autoincrement columns can easily be overcome.
You should spend some time reviewing the T-SQL coverage since it is used in both the SQL Analytic endpoint of the Lakehouse as well as the Warehouse. In the future, I will talk more about the following topics: how to get data into the Warehouse; what T-SQL language features are supported; and what are some new features due to the OneLake storage format.