

Most databases designs nowadays seem to have at least a few if not many lookup or reference tables (I'll use these two terms interchangeably). These tables are those small tables that you maintain your list of States, or CustomerTypes or JobStatus or any number of valid domain values used to maintain data integrity within your application. These reference tables usually have simple 2 -4 columns with the naming convention usually following along the lines of ID, Value, and Description, and maybe Active. (e.g. CustomerTypeID, CustomerTypeValue, CustomerTypeDesc, CustomerTypeActive) I have seen database designs that have hundreds of these reference tables.
There is nothing wrong with the mere existence of these tables, but they do bring some baggage along with them. One of the considerations that happens when you have these tables is that someone has to design and approve them. Someone then has to design, code, and approve any necessary views, and stored procedures around them. And most of these tables, views, and stored procedures are fairly simple. There's usually very little insert, update, or delete (IUD) activity happening. They're mostly used for lookups and for joins in views to represent the entire picture of a record. In a large application you can also clutter up your list of tables with so many of these that you begin to think that you need to have a special naming convention for objects that are lookup related. (e.g. lkpCustomerType, lkpStates, slkp_GetCustomerType, etc).
All of the previous issues that I presented were from the DBA or database developer's perspective, but there's another perspective to take into consideration. The application developer's perspective. Whether it's a traditional client server or internet application, the application developer has to usually create separate functions to access & modify the data within each table, often creating separate classes to represent each table. Then the developer needs to create an interface for the user to maintain the values within these tables. This naturally makes more work for the developer.
I've created a lookup architecture that simplifies things a bit. This is not necessarily a brand new concept, but it is something I've rarely seen. What I've done is to create two tables. I call them Look and LookType. The structure is shown in Figure 1
Figure 1.
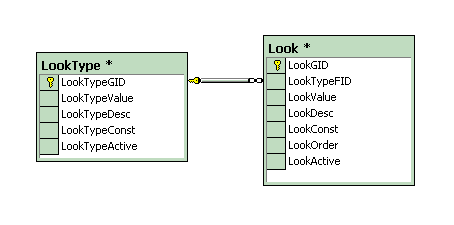
Before I go any further, let me first explain another design and naming convention that I have. All tables that I design have a field that is unique and is named after the table with the suffix of GID (Generated ID). This value is usually an IDENTITY integer although can sometimes be a uniqueidentifier. This field is not necessarily the Primary Key, although in this instance it is. My other convention is that all Foreign Key fields have the suffix FID (Foreign ID). This field doesn't necessarily have to have the same name as the Primary Key it references, but usually ends up that way. So that explains the LookTypeGID, LookGID, and LookTypeFID fields. Each of the GID fields are IDENTITY integer fields and are also the Primary Key. The LookTypeFID field is the foreign key to the LookTypeGID field. The other convention that I have is that all foreign key values in the tables that point to the Look table have the LID (Lookup ID) suffix. This makes it easier for me to at a glance realize where things are related to. The main fields are the Value fields. These are normally where the reference value is stored. There is also a description field which can be used for longer and more descriptive descriptions of the value. On both tables there is also an Active field which can be used to either inactivate a single value in the list or an entire list. The
LookOrder field is used solely for display or sorting purposes. In lookup lists, there isn't a standard way of sorting things. Usually somebody wants things sorted a particular way besides alphabetical, numerical, etc. This field is for that and is of integer data type. The other important field is the Constant field. This is a place where you can put an easier to remember value to reference that row from your application. You don't want to go hard coding distinct values into your application code such as SELECT * FROM Customers WHERE CustomerTypeLID = 2. The reason that this is bad is 1) it has no meaning without doing a little more work, 2) moving development data to production or any number of events can reset your IDENTITY values and screw your code up, and 3) The client usually doesn't have any control over the ID's, so if he wants to change what the code is pointing to, he has to edit either the code of go into the database at the table level.
Now you're either a tad bit confused or you're possibly saying “so what”? Well, first let's put a couple of values in the tables so that you can see an example of what I'm talking about.
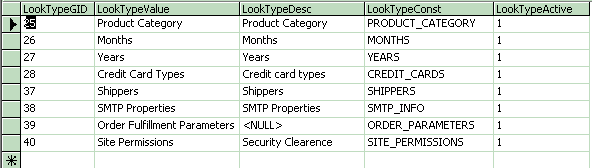
Sample LookType data.
Sample Look data
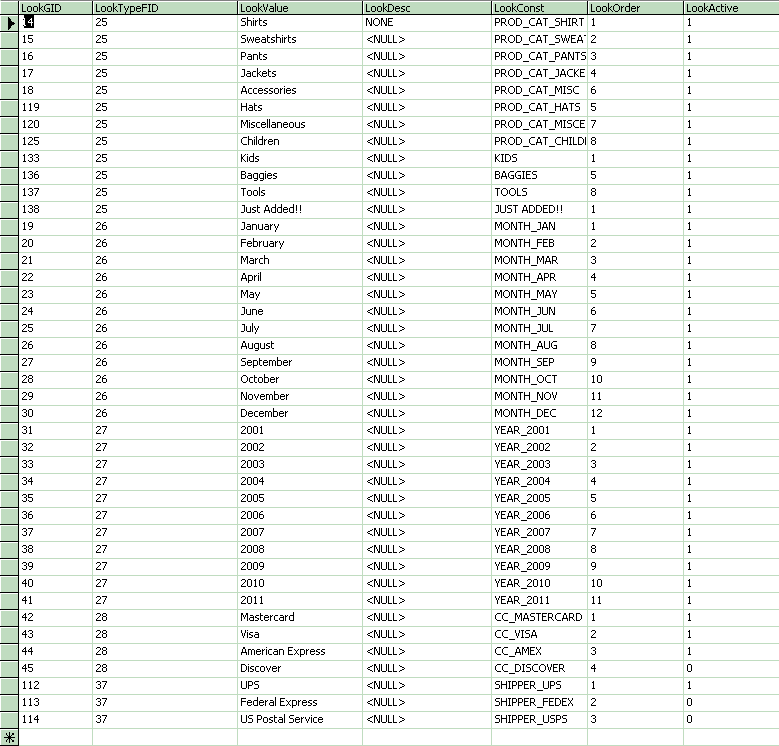
Now, from a lookup perspective, all of the values will come from the Look table. The only table within the database that would reference the LookType table would be the Look table. Its sole purpose is to create a grouping identifier for the Look table values. So we can see that our List of Shippers has a LookTypeGID of 37 and has 3 shippers in it. We use the constant value of SHIPPER_UPS etc to identify within the application which row we're referencing. A sample Order table would then have an integer field called ShipperLID with a possible value of 112 for UPS. If I wanted to get the list of shippers I'd call one of my stored procedures like “EXEC s_LookListByTypeConst ‘SHIPPERS', NULL” (NULL representing my Active field. I can either get all of the active records, or all the records no matter whether active or not. It defaults to Null which here means only Active)
Now, I know that there are probably a number of you who immediately see that this design breaks the 1st form of normalization. I contend that there are always exceptions to the rule based upon applicability of the situation.
With this design, you never need to create new lookup or reference tables. You just need to add data to preexisting tables. That then leads us to the next and most valuable aspect of this design. We can make generic procedures that allow us to do anything and everything with these tables with a small list of stored procedures or functions. These stored procedures or functions can then be used for all application development. This is where it now gets interesting. I do mostly web front end applications for my data marts. I've created a single asp page that has access to a VBScript class which access the stored procedures. This page then allows the application users or managers to manage their own lookup lists. Gone are the days when the application manager asked me to add the new CustomerType of Wholesale or add an entire lookup table and the corresponding stored procedures, or to sort the ProjectStatus of Open to the top of the list and Closed at the bottom.
Here's a list of the stored procedures that I use. You'll get the gist of their meanings since I'm fairly verbose with my object names. I've also included a couple samples.
- s_LookAddEdit
- s_LookTypeAddEdit
- s_LookDelete
- s_LookTypeDelete
- s_LookListByGID
- s_LookListByConst
- s_LookListByTypeGID
- s_LookListByTypeConst
- s_LookTypeList
- s_LookGIDByConst
- s_LookTypeGIDByConst
- s_LookValueByConst
CREATE PROCEDURE s_LookValueByConst
(
@const varchar(100),
@active int = NULL,
@value varchar(1000) OUT
)
AS
SET NOCOUNT ON
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
BEGIN TRAN
SELECT @value = LookValue
FROM Look
WHERE LookConst = @const
AND (@active IS NULL OR LookActive = @active)
COMMIT TRAN
GO
CREATE PROCEDURE s_LookListByTypeConst
(
@const varchar(100),
@active int = NULL
)
AS
SET NOCOUNT ON
DECLARE @id int
EXEC s_LookTypeGIDByConst @const, NULL, @id OUT
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
BEGIN TRAN
SELECT *
FROM Look
WHERE LookTypeFID = @id
AND (@active IS NULL OR LookActive = @active)
ORDER BY LookOrder
COMMIT TRAN
GOI also have one view called v_Look which combines the two tables and all of the values.
You'll notice that I set the transaction isolation levels to read uncommitted. I do this since these are fairly popular tables used in many different views and sometimes used in the same view more than once. These tables are also fairly static and so speed is my main concern here.
Now realize that there are considerations and some requirements in order to implement this design.
- All of your value and description fields need to be the same data type, most normally varchar. You can obviously store numbers or dates in the value fields, but they'll need to be cast correctly on the application for input and output.
- You need to have unique LookConst values.
- You should have check constraints on tables that reference the Look table so that you can validate that only allowable values are put into that field. (e.g. there would be nothing invalid about putting the value of 30 into the ShipperLID field in the Order table. Unfortunately, that would then mean that the Shipper was “December”.
- All data access code should come through the stored procedures.
- This design currently does not take into consideration of different security rights for different reference domains. (e.g If Mary can change CustomerType values, but not Shipper values.) This has to currently be done at the application level.
- This design is limited in that if you have a domain of values that require more than the designed fields, it doesn't work very well and you'll be better off making an individual table for it.
- In some of my applications I have added CreatedDate and CreatedBy and ModifiedDate and ModifiedBy fields for auditing purposes.
- I found this design to work very well for those application level setting tables or application / DTS global variable tables.
I have slowly over the years refined this module of functionality to include such things as reordering the display order if a user changes, inserts, or deletes a Look record, creating stored procedures to return not only the value but also the description (sometimes a user may want to see a drop down list of State abbreviations, other times the entire State name), and am now working on the addition of functions to replicate a lot of the stored procedures so that a developer could use the function in a SELECT query simply.
I hope this gets you to thinking on how to reduce the number of reference tables in your databases and if you have any feedback, please let me know. I'm always interested in hearing other developers' thoughts.
David Sumlin
