

I was working on trying to improve performance of an update statement at work. It was taking three minutes to run. I noticed an interesting sub query going on in the SQL. The purpose of the code was to net out inventory against demand quantity. I spent a lot of time looking at the code trying to figure out a way I could speed it up.
Finally, I started to look at the over( partition by function in SQL. I found something new in SQL Server 2012. You can now add an order by to the over( partition by and it will do a cumulative sum of the previous rows. I had used the over( partition by with a row_number before, but not to do a cumulative sum over previous rows. When I implemented this new code my three minute update changed to a six second update.
Here is an example. First we create three tables.
CREATE TABLE Inventory
(
inventoryID INT IDENTITY(1, 1)
PRIMARY KEY
NOT NULL
, itemID INT NOT NULL
, inventoryQty NUMERIC(18, 6) NOT NULL
)
CREATE TABLE Items
(
itemID INT IDENTITY(1, 1)
PRIMARY KEY
NOT NULL
, itemName VARCHAR(50) NOT NULL
)
CREATE TABLE Demand
(
demandID INT IDENTITY(1, 1)
PRIMARY KEY
NOT NULL
, itemID INT NOT NULL
, orderNbr VARCHAR(50) NOT NULL
, orderQty NUMERIC(18, 6) NOT NULL
, netInventoryQty NUMERIC(18, 6) NULL
)Now we will insert some data:
INSERT INTO Items
VALUES ( 'Blue Chair' )
INSERT INTO Items
VALUES ( 'Red Chair' )
INSERT INTO Items
VALUES ( 'White Chair' )
INSERT INTO Inventory
VALUES ( 1, 5 )
--5 Blue Chairs in Inventory
INSERT INTO Inventory
VALUES ( 2, 3 )
--3 Red Chairs
INSERT INTO Inventory
VALUES ( 3, 9 )
--9 White Chairs
INSERT INTO Demand
VALUES ( 1, '1001', 1, NULL )
--order for 1 blue chair
INSERT INTO Demand
VALUES ( 2, '1002', 1, NULL )
--order for 1 red Chair
INSERT INTO Demand
VALUES ( 1, '1003', 2, NULL )
--order for 2 blue chairs
INSERT INTO Demand
VALUES ( 3, '1004', 1, NULL )
--order for 1 white chair
INSERT INTO Demand
VALUES ( 2, '1005', 3, NULL )
--order for 3 red chairs
INSERT INTO Demand
VALUES ( 1, '1006', 4, NULL )
--order for 4 blue chairs
INSERT INTO Demand
VALUES ( 2, '1007', 2, NULL )
--order for 2 red chairs
INSERT INTO Demand
VALUES ( 3, '1008', 2, NULL )
--order for 2 white chairs
INSERT INTO Demand
VALUES ( 1, '1009', 1, NULL )
--order for 1 blue chairLet’s see what we have for results so far:
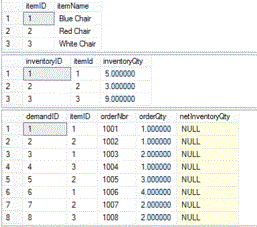
Next let’s take a look at the update:
UPDATE d
SET netInventoryQty = i.inventoryQty
- ( SELECT SUM(orderQty)
FROM demand d2
WHERE d2.itemid = d.itemID
AND d2.demandid <= d.demandid
)
FROM demand d
JOIN inventory i
ON d.itemID = i.itemidNotice that the sub query is summing up previous demand order quantity that have a demandID <= the current demandID. This sub query is trying to do a cumulative sum of the orderQty. When we subtract the cumulative orderQty from the current InventoryQty we can figure out when we will run out of Inventory.
Here are the results of the update:
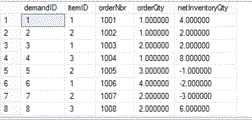
When the netInventoryQty goes negative that tells us on what demand order we are going to run out of inventory.
Now here is the query that does the cumulative sum over previous rows using the over( partition by order by function.
SELECT demandID
, itemID
, orderQty
, SUM(orderQty) OVER ( PARTITION BY itemID ORDER BY demandid ) AS 'cumQty'
FROM demandThis gives these results:
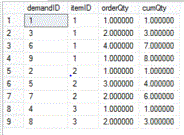
You can see how the cumQty column is a cumulative sum of the orderQty for the previous demand orders of the same itemID.
So now I changed my update to use this new query in a join instead of a sub query.
UPDATE d
SET netInventoryQty = i.inventoryQty - t.cumqty
--(select sum(orderQty from demand d2 where d2.itemid = d.itemID and d2.demandid <= d.demandid)
FROM demand d
JOIN inventory i
ON d.itemID = i.itemid
JOIN ( SELECT demandID
, itemID
, SUM(orderQty) OVER ( PARTITION BY itemID ORDER BY demandid ) AS 'cumQty'
FROM demand
) t
ON t.demandID = d.demandIDWe get the same results:
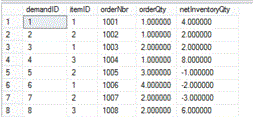
I hope this example might help you if you run across a need to sum up cumulative values. It was the solution I needed to fix some poor performing code and get it to run a lot faster.

