

This is the second article in a series that examines the output of the Brent Ozar Unlimited sp_Blitz™ script run against the SQLServerCentral database servers.
Managing a SQL Server is an ongoing job. While the SQL Server platform will run itself for a long time, as your workload evolves, your applications are patched, and your staff experiences changes, it's easy for configuration and security issues to creep into your environment. The best way to prevent issues and problems is with regular monitoring and auditing of your instances.
The SQLServerCentral servers are regularly monitored, using SQL Monitor from Red Gate Software, and you can see the data at monitor.red-gate.com. We expose that as a demonstration of what the monitoring software can do. This covers alerts and problems that occur in real time, but it doesn't catch some changes which may occur over time.
This is where some type of auditing becomes very important. One of the ways in which you might think about auditing your instances is with a standard script that examines various potential places where your configuration isn't optimal.
sp_Blitz™

Brent Ozar Unlimited has released a fantastic script for examining the configuration, health, and performance of your SQL Server instances. This script is known as sp_Blitz™ and is currently at v16. You can download it and it builds a stored procedure that you can run on any of your instances.
There is a tremendous amount of information returned, and if you are interested, you can read about the script on the Brent Ozar Unlimited site.
We used this script to perform a quick audit of our database server instances and learned a few things. This series of articles examines the results and mitigation strategies we've taken. The other articles are:
- Security
- Reliability
- Performance - Part 1
- Performance - Part 2
- Query Plans
- Informational and other lower priority items
This article examines items related reliability.
Reliability
The second Findings Group output by the sp_Blitz™ script is the reliability section. These are items that can affect the availability or stability of the database instance for various reasons. We received the following sections in our result set:
- Collation mismatches
- Last good DBCC CHECKDB over two weeks old
- No alerts
- No failsafe operator
- Not all alerts configured
- Transaction log larger than data file
Each of these items is discussed below with regard to our database servers.
Collation Mismatches
We received two sets alerts in this area. One set was for a collation in a user database different than tempdb and the other was the same user databases not matching the instance level collation. Neither of these is overly concerning to me, but I will discuss them below.
The first alert was for two databases' collations not matching that of tempdb. Since any temporary objects in SQL Server (outside of contained databases) will use the collation of tempdb, and not the database, this can lead to a collation error. The error is easy to fix with a COLLATE clause, but that requires code changes. The two databases are the CommunityServer and SQLServerCentralForums. You can view the collation of these databases at monitor.red-gate.com, and I've reproduced the relavant portion of the properties for the SQLServerCentralForums database below.
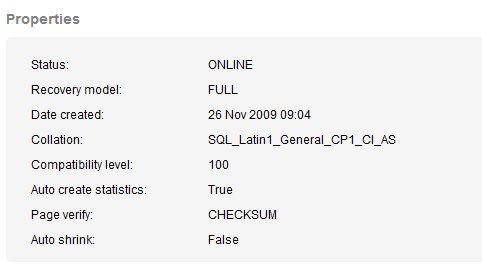
We can see this is the SQL_Latin1_General_CP1_CI_AS collation. Tempdb has the collation of the instance by default, and that's true in this case. I've reproduced those properties below
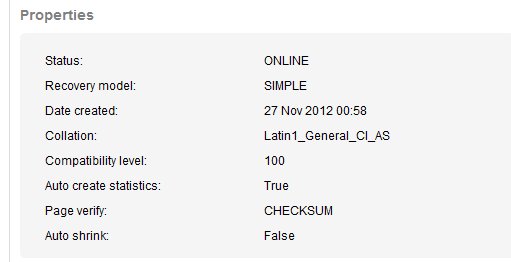
The Community Server database used to power our blogs, and still handles a few legacy blogs, so I am reluctant to change anything there. The SQLServerCentralForums database handles all the forums, and is an intregral part of our forum system. This is a third party forum we purchased, and again, I am reluctant to change things.
In any case, the Latin1_General_CI_AS and SQL_Latin1_General_CI_AS are essentially the same, but not quite. As noted in a blog on SQLServerCentral, you can have issues. Mixing collations is never a good idea. I also found a thread on MSDN that seems to indicate one may be faster or slower, but you don't want to mix.
This issue is related to the second set of alerts, which are the same two databases' collation not matching the instance level collation. The instance level collation can be seen at monitor.red-gate.com. I've copied the relevant portion of the page in the image below. We can see the instance level collation is set to Latin1_General_CI_AS.
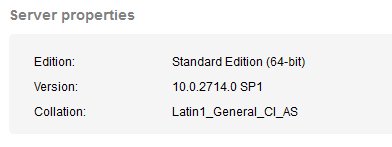
This is less concerning than the tempdb alert, though neither is ideal. I will add this to the list of things to change in the future, but since these haven't caused issues for the 3+ years this set of servers have been running for us, and we are aware of the issues, I think we are fine. Since both of these databases are third party products, and we rarely write code against them, this isn't a priority item.
I have let the developer know that these two items could potentially cause is an issue if we start to perform development on the forum database and include temporary objects.
You can read more about this alert at BrentOzar.com.
Last good DBCC CHECKDB over two weeks old
When I first saw the alert that DBCC CHECKDB was overdue on a database, I was concerned. I think this is one of the more important things a DBA should be doing on their production databases. You cannot prevent corruption, but you can detect it early, so you need to run DBCC CHECKDB regularly. I was concerned since I hadn't seen an Integrity Check Overdue alert from SQL Monitor.
In this case, the alert is on tempdb.
That seems a little strange to me. As a matter of habit, I haven't typically run DBCC CHECKDB against tempdb. The alert actually notes that tempdb has never had a DBCC CHECKDB run against it. That makes sense, as I'm sure this was never set up. SQL Monitor doesn't check tempdb for this particular alert.
In checking the maintenance on the server, I found that we are running CHECKDBs on system (master, model, msdb) databases and user databases, but not tempdb. I'm not sure I want to add tempdb to our list.
I emailed Brent, and his response was he's started adding tempdb since finding lots of people moving tempdb to SSDs, he thinks this is a good idea. That makes me change my mind. We don't have tempdb on SSD, but this also isn't likely to cause an issue. I am tempted to schedule this for a week or two and see if there are any issues.
You can read more about this alert at BrentOzar.com.
No alerts
This section had two alerts in it.
- No alerts for corruption
- No alerts for Sev 19-25
Both of these are items that should be enabled on all server instances. Just like the DBCC CHECKDB, the corruption alerts are important for detecting issues ASAP and correcting them or replacing hardware.
The severity alerts are good to have since they indicate that something bad has happened. It might not affect your server, but it might, depending on what caused the error. In the event of any high severity error, you need to investigate the issue and determine if it is something that might be causing you problems.
As a resolution, I've added alerts for these severities and specific errors. I used scripts similar to those found at these links:
- http://www.sqlskills.com/blogs/paul/easy-monitoring-of-high-severity-errors-create-agent-alerts/
- http://www.sqlservercentral.com/blogs/sqltact/2012/08/20/sql-agent-alerts-severity-condition-is-not-greater-than-or-equal-to/
This won't prevent corruption or serious issues, but this should alert someone when any event occurs.
In SQL Monitor, we can include custom alerts that read the error log if we want. I could write a query like this, which would scan the error log for any errors with a severity of 20:
CREATE TABLE #Errors ( logdate DATETIME , ProcessInfo NVARCHAR(100) , MsgText NVARCHAR(200) ) INSERT #Errors exec xp_readerrorlog 0, 1, 'Severity: 19' SELECT errorcount = COUNT(*) FROM #Errors DROP TABLE #Errors
However there's no need to do this. In SQLMonitor, we have a built in alert that scans for error log entries. If I go to monitor.red-gate.com and look at the Configuration tab, I'll have all the built in alerts. These are broken down by host and SQL Server specific alerts:
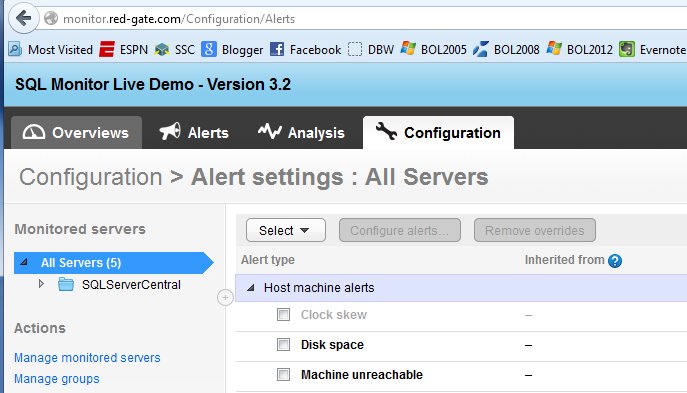
If I scroll down, I can see there is an alert for the error log, and if I click it, I get this:
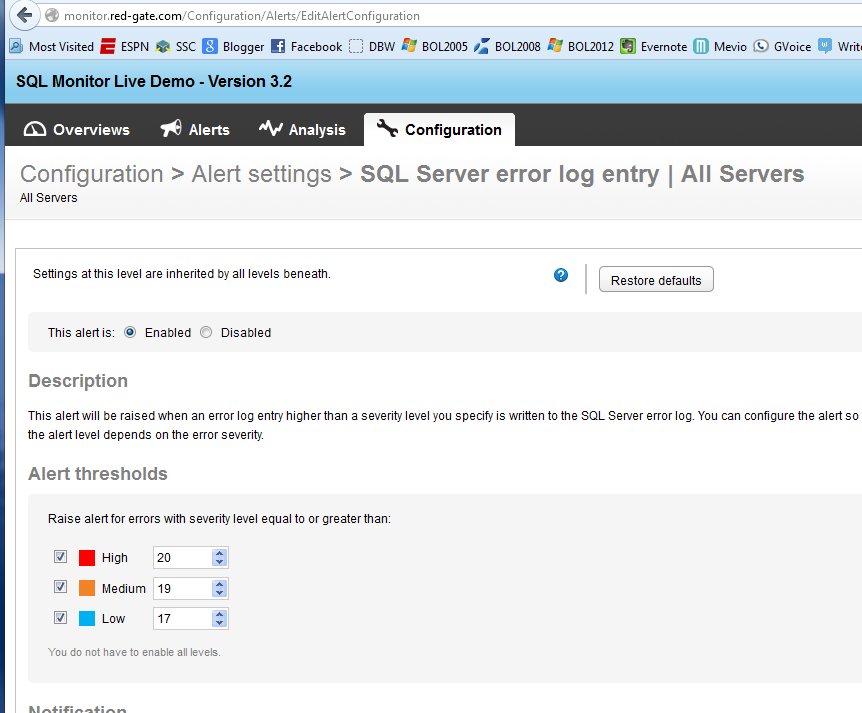
As you can see, without you having specific alerts on your instance, or your DBA understanding how to set up these alerts. If any error is raised with a level of 17 or higher, a SQL Monitor alert is raised. You can change these to suit your needs, but these are valid starting points for us.
Note that the corruption alerts (823, 824, 825) will record in the error log, though with different severities. The 823/824 errors, which are corruption issues, record with severity 24. The 825, which can be a sign of problems coming, is an informational only severity 10.
You can read more about this alert at BrentOzar.com.
No failsafe operator
The Failsafe operator in SQL Server is the operator that receives an alert if no other operator can be reached. I'm not sure where/when SQL Server will fail to reach an operator, but this is set if the pager option doesn't work correctly or the Agent cannot access the msdb database. I'd hope the failsafe would then work, but you never know.
Books Online explains how to designate one if you want.
We haven't configured one, but I do think there should be one here. I sent a note asking who we should designate in the event of problems reaching someone with an alert and received a reply. This has been mitigated.
You can read more about this alert at BrentOzar.com.
Not all alerts configured
All the alerts recommended by BrentOzar are listed on his page. As noted above, we don't have most of these configured, and I think it's a good idea that we do. I've requested they be enabled on the server, but I don't want to make the change without our IT group being aware of the change.
The code to enable these alerts is found on the alert page where you can read more about this alert at BrentOzar.com.
Transaction log larger than data file
This item is disconcerting. Whenever I see this, my first thought is that no one is managing file sizes, and backups are not occurring. In our case, this is what happened at some point.
If I look at one of the databases in question, the Community Server database, I see this at the bottom left.
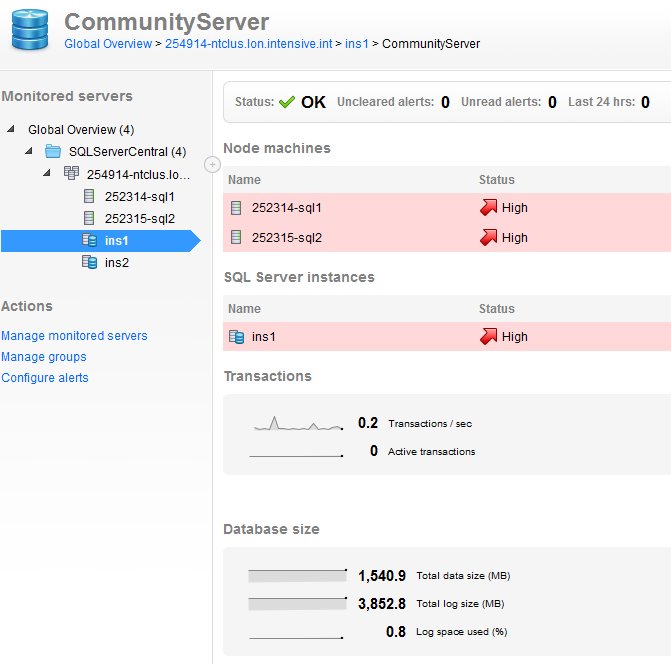
The database is 1.5GB, but the log is 3.8GB. There's almost no activity on this database, especially now with our syndication keeping relatively little data on our site. I suspect when this database was first set up, either the log backup job was disabled or not configured. To understand this better, we have a great article on Managing Transaction Logs.
If I check the recent backups of this database, I find that the log backups are:
- 6.85MB
- 6.85MB
- 6.98MB
- 7.28MB
- 6.91MB
If I check over the last few weeks, the largest log I can find is around 100MB.
There is very little load on this database and probably no reason for there to be a 3.8GB log file. At SQLSkills, Kimberly Tripp has a great article on transaction log throughput, and one of the steps is to properly size your log file, and the number of VLFs. I did check on the VLF count and found it to be 427.
The same is true for a couple other databases, a few with VLF counts in the 1000s. As a result, I decided to request the following:
- a log backup
- DBCC SHRINKFILE( log file name, TRUNCATEONLY)
- ALTER DATABASE MODIFY FILE (setting the file size to an appropriate size. For the 1.5GB Community Server database, a 1GB transaction log file is probably overkill, but that clears this item and sets a reasonable size for the log that should handle the load. The difference between a 512MB log and a 1GB log isn't worth worrying about.
- The autogrowth size is also being left at 128MB, which is a little over 10%.
For the other databases, similar actions are being requested. We'll see what happens here.
You can read more about this alert at BrentOzar.com.
Moving Forward
This is the second article looking at the very helpful and popular sp_Blitz™ script, and it examined the reliability section of the output. The next article will examine the Performance section of the script as run against the SQLServerCentral database servers.
The other articles in this series are:
- Security
- Reliability
- Performance - Part 1
- Performance - Part 2
- Query Plans
- Informational and other lower priority items
This is a great script to run on your instances, but you need to run it periodically to catch changes, some of which might potentially be causing you problems, or will cause you problems in the future. Saving your output from previous runs and comparing the results and looking for changes is a good idea to save during future analysis.