
Welcome to Level 6 of the Stairway, by now you should understand the differences between a standalone instance of SQL Server and a clustered instance of SQL Server. You should understand how to install a Failover Cluster Instance of SQL Server and the resources required to achieve this.
In this level we're going to be looking deeper at Always On Availability Groups, we'll actually walk through a wizard based deployment and discuss each of the steps and how they affect our installation. We'll also look into how we actually enable ReadOnly routing and the use of the Always On Group listener. Near the end of the article we'll look at testing failure scenarios.
From the previous levels you should now have a valuable insight into the basic platform required to implement both a Failover Cluster Instance of SQL Server and an Always On Availability group. To review, you need the following core infrastructure components
- A Windows Server Active Directory domain
- A DNS infrastructure
- A DHCP scope (if you plan to use DHCP)
- A Windows Server Failover Cluster
- A set of nodes that are members of the same WSFC
Now that we have this in mind, let's take a closer look at Always On Availability groups and then we'll get deeper into the deployment and configuration practical.
Why Always On Availability Groups?
Traditionally, one would have used SQL Server failover clusters to attain SQL Server High Availability, this would have used either Microsoft Cluster Services (Windows 2003) or Windows Server Failover Clusters (Windows 2008\2012). With a clustered environment we are able to fully mitigate server hardware failures by utilising
- Multiple network cards and TCP\IP networks for network redundancy
- New majority node set quorum models (available in Windows server 2003 SP1 onwards) to remove the disk dependency and increase support for multi site clusters.
- Multiple computer nodes to negate core node hardware failure (i.e. motherboard, etc)
The only real weak link in the chain is the shared storage required to service a Failover Cluster Instance. There are many ways to achieve redundancy here, but it usually comes at a significant cost and it is often difficult to setup and maintain. Of course, as previously mentioned, a failover cluster only mitigates the server hardware, it does not provide a single or even multiple secondary databases.
When utilising the first option, Failover Cluster Instances (FCI), the Windows Server Failover Cluster (WSFC) works at the SQL Server instance level to provide high availability for all objects. All cluster nodes joined in the FCI essentially act as a tag team for the clustered resources, when one partner drops the baton, another steps in. During a failover, a restart of the SQL Server service is performed.
The next option for High Availability would have been database mirroring. The problem is, mirroring only provides scope for a single nonreadable (with the exception of database snapshots) secondary database. You can combine other SQL Server availability technologies with fail over clusters and mirroring, but think of the increased complexity. Database mirroring provides failover at a database level. The two systems involved in the mirror session are typically two completely separate SQL Server systems with no shared storage. The problem here is the mirror database is not readily available.
This brings us to a third option, Log Shipping with Standby/ReadOnly. This is a great way of replicating a database for read access. The two issues with log shipping are the fact that the secondary can lag behind the primary, and users are disconnected from the database during the log restore process. It can, however, provide a one to many relationship from the Primary to multiple Secondary's.
What are Always On Availability Groups
An Always On Availability Group provides the ability to replicate a database in its entirety to a pre-defined set of partner SQL Server instances, known as Replicas, for standby or read access. This is achieved by creating an Always On Availability Group, which consists of at least two replicas and at least one database. A single database may only belong to one Always On Availability group, although you may have multiple Availability Groups across your replicas. When creating a new group and adding databases, a series of prerequisites are checked. The image below shows an example of the prerequisite check for a new Always On group database.
Diagram 6.1
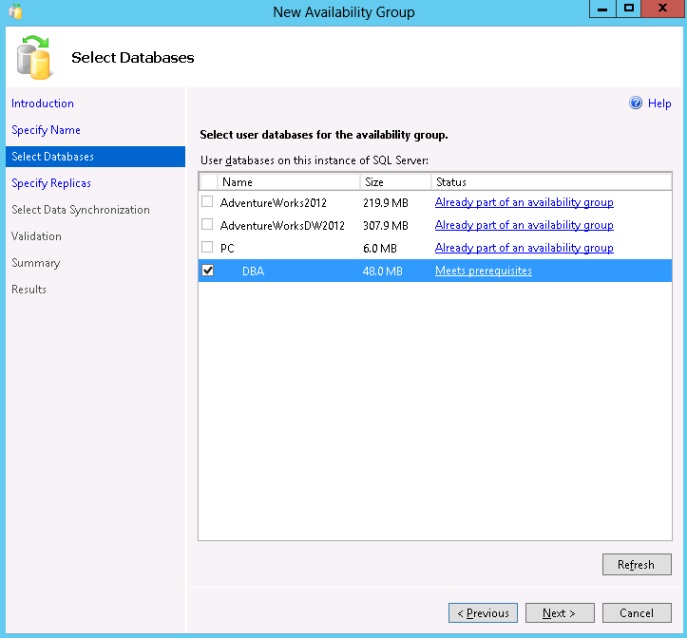
The pre requisites that must be satisfied before a database may participate in an Availability Group. These are fully detailed at the following Microsoft KB link: http://msdn.microsoft.com/en-us/library/ff878487
So, we are able to replicate a database for read connectivity to a set of pre defined partner SQL Server instances. However, Always On groups have a limitation on the number of replicas that may be;
- Joined to the Availability Group (maximum of 5, 1 Primary and 4 Secondary. The Secondary count has increased in SQL Server 2014 to 8).
- Configured for synchronous replication (maximum of 3).
- Configured for automatic failover (maximum of 2 replicas, both must be in synchronous mode).
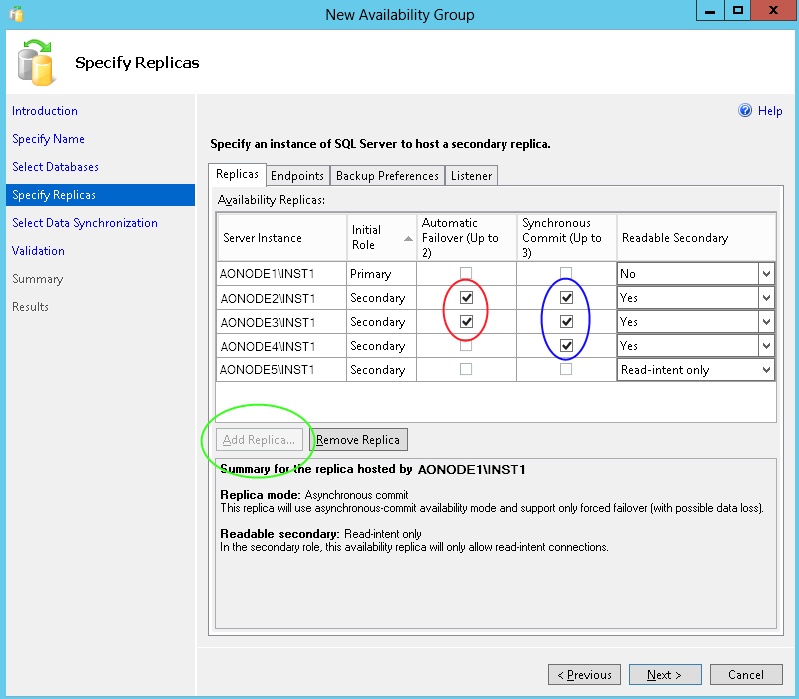
The Availability Group restrictions can be seen in the following example section of the "New Availability Group" wizard, as shown in diagram 6.2. The green ellipse shows the "Add Replica" option greyed out in this SQL Server 2012 example. This happens once there are five replicas defined in the list. The blue ellipse shows the maximum number of synchronous replicas. Notice the checkbox for AONODE5\INST1 is greyed out. The red ellipse shows the maximum number of automatic failover replicas. Notice the checkbox AONODE4\INST1 is greyed out. AONODE5\INST1 is also greyed out automatically as it's not configured for synchronous replication.
Diagram 6.2
Impact of Row Versioning
When you enable a database as a readable Secondary in an Always On Availability group, row versioning is automatically implemented and applies a 14 byte overhead on each row that is modified. In fact all isolation levels are transparently mapped to the snapshot isolation level to avoid redo thread blocking. Without this, report workloads could possibly interfere with the redo thread process.
The addition of the row version data on the Primary depends on the snapshot isolation or read-committed snapshot isolation (RCSI) level setting on the primary database. If row versioning is also explicitly implemented on the Primary database in the group there will be an overhead on the Primary replica too.
This row overhead can be viewed by querying the "max_record_size_in_bytes" column in the DMV "sys.dm_db_index_physical_stats". The table below describes the behaviour of versioning on a readable secondary database under different settings for disk based tables.
| Readable Sondary? | Snapshot isolation or RCSI Level Enabled? | Primary Database | Secondary Database |
|---|---|---|---|
| No | No | No row versions or 14-byte overhead | No row versions or 14-byte overhead |
| No | Yes | Row versions and 14-byte overhead | No row versions or 14-byte overhead |
| Yes | No | No row versions or 14-byte overhead | Row versions and 14-byte overhead |
| Yes | Yes | Row versions and 14-byte overhead | Row versions and 14-byte overhead |
From the Books Online link: http://msdn.microsoft.com/en-GB/library/ff878253.aspx
Impact of Missing Statistics
Any readable secondary database will likely encounter missing statistics related to the readonly workloads that are being processed. Any statistics that are created or updated on the Primary database will be persisted to the secondary(s).
Any Readonly workloads running on the secondary databases will have temporary statistics generated and these are stored in TempDB. This could potentially increase TempDB usage even further, this is another reason to carefully size the TempDB based on the usage it will incur. More can be found at the following link: http://msdn.microsoft.com/en-GB/library/ff878253.aspx#ReadOnlyStats
Advantages
Despite these limitations, Always On offers us a new level of HA with the following features
- No shared storage, each server\instance has localised storage and removes the storage Single Point Of Failure.
- Always On listener service to accept centralised requests to HA database groups.
- Multiple availability databases instead of the traditional Principal\Mirror scenario.
- Better failover functionality leveraging Microsoft Windows Server Failover Clustering.
- The ability to suspend data movements at the primary level or individual secondary level.
- Support for multiple IP subnets.
- Ability to offload backup operations to secondary databases.
By offloading backup operations to read only replicas, you can reduce the I\O requirements on your Primary production systems. Multiple secondary's can also provide DR and reporting replicas, of course this does affect licensing costs as the secondarys are now active.
One item immediately noticeable is the fact that Always On still uses the familiar SQL Server database mirroring endpoints for instance-to-instance communication. Just as in database mirroring, you may either use Windows authentication for the Endpoints or certificates. You may only create one database mirroring endpoint per instance of SQL Server, so, if you're planning to use multiple Always On Availability groups, you'll need to remember they will all share the same mirroring endpoint.
You now have the option to create a highly available listener service, which you will use to accept incoming connections to the Availability Group. The listener consists of a unique virtual IP address and a unique virtual Networkname. This is by far one of the most significant changes in making the groups databases highly available.
By providing a centralised access point into the Availability Group, clients are removed from the issues surrounding connection string configurations that are generated during the failover of a database. Availability Group replicas may also be configured for read-only routing. This allows online readable secondarys to handle read only requests, removing concurrency issues from the primary replica.
With Always On you still also have the traditional synchronous and asynchronous modes that were used in database mirroring, too. Synchronous commit partners harden the primary databases transactions to all secondary's before the transaction is confirmed as complete. With asynchronous commit, the secondary has the possibility of missing transactions if the sessions between the primary and secondary are broken. Asynchronous replicas support manual failover only, while synchronous replicas support automatic or manual failover.
There are a range of options for troubleshooting any errors, you have the Always On dashboard and also the SQL Server and Windows logs. The wizard driven deployment offers the easiest deployment route, whereas manual deployment requires a fair amount of manual interaction. Despite this, a basic AO group configuration is still extremely easy to deploy and configure and offers a level of HA that was previously not available without resorting to complicated levels of feature integration.
Before you may implement an Always On Availability group you must enable the feature on each SQL Server instance that is to participate as a replica in the Always On group. This feature may only be enabled when the node has been successfully joined to a Windows Server Failover Cluster. The option is enabled by opening SQL Server configuration manager on the node (the active node for a Failover Cluster Instance) and editing the properties of the SQL Server service. An example is shown below in diagram 6.3.
Diagram 6.3
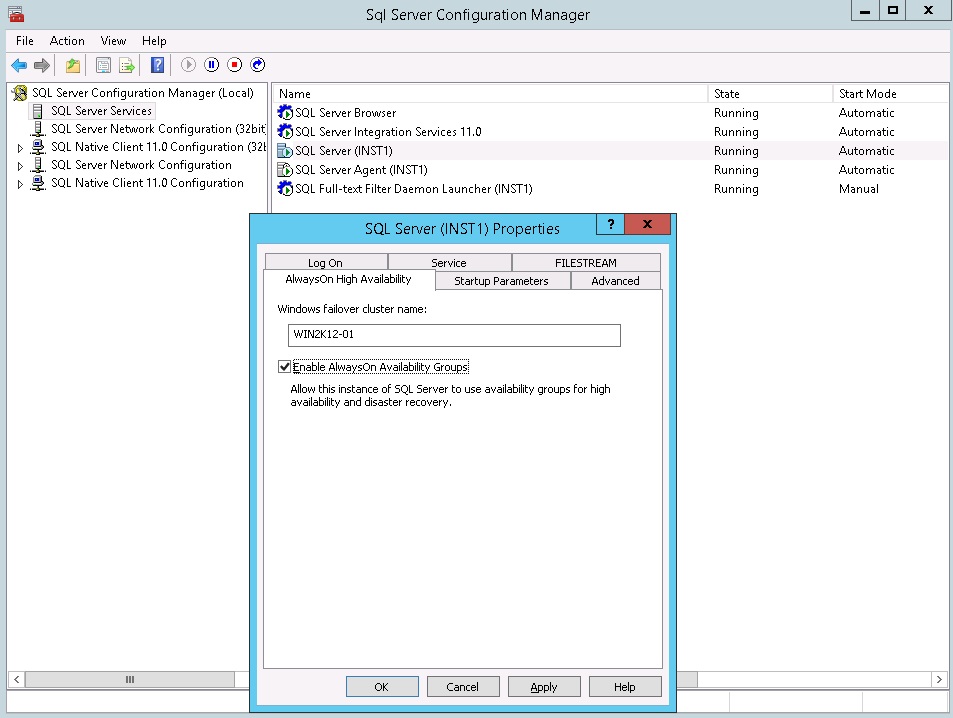
A restart of each SQL Server instance's service will be required to complete the configuration.
Availability Group Deployment
With the Always On option enabled, let's deploy an Always On group now. We're going to require some SQL Server instances, so if you don't have any installed yet, deploy a standalone instance of SQL Server to each of the cluster nodes. Using the guidance above, enable each instance for Always On High Availability.
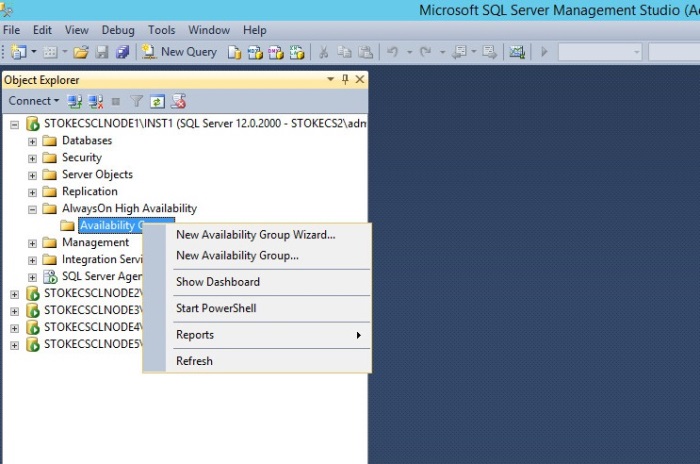
To invoke the Always On availability group wizard, locate your preferred SQL Server instance and expand the "Always On High Availability" option in SSMS. Right click "Availability Groups", then select "New Availability Group Wizard" as shown below in diagram 6.4.
Diagram 6.4
The first dialog specifies the objects required to successfully complete the wizard. Ensure you have the required information to hand before continuing. See diagram 6.5.
Note: This may involve speaking to your system administrators and obtaining account information, virtual Networknames and virtual IP addresses.
Diagram 6.5
Firstly, specify an Always On Availability group name. The name you use here will be the name of the clustered role that is created within the Windows Server Failover Cluster and should be unique within that cluster. Click "Next" to continue, as shown in diagram 6.6.
Diagram 6.6.
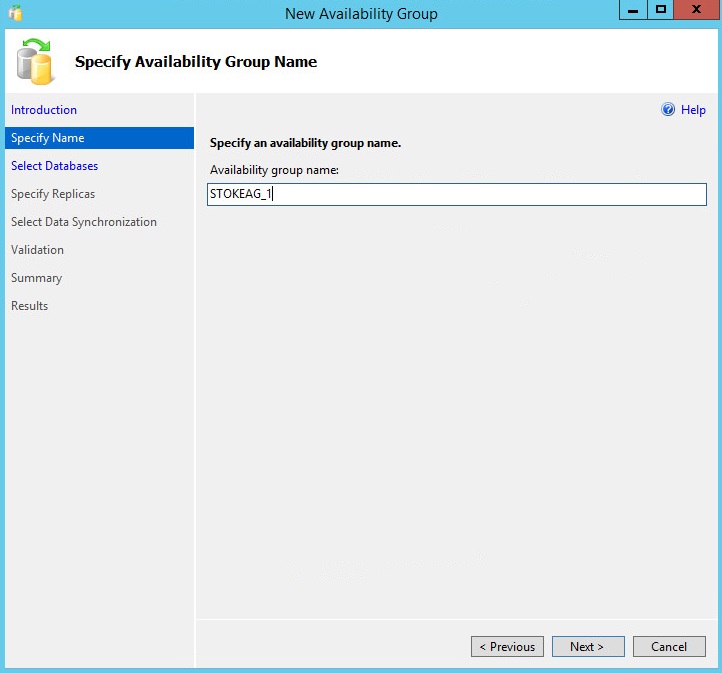
If you have no databases available on the SQL Server instance where you have initiated the wizard, you will see something along the lines of the dialog below, shown in diagram 6.7.
Note: To continue I simply ran a full backup of my AdventureWorks2012 database and clicked the "Refresh" button.
Diagram 6.7
The pre requisites have now been met. To continue click "Next".
Diagram 6.8
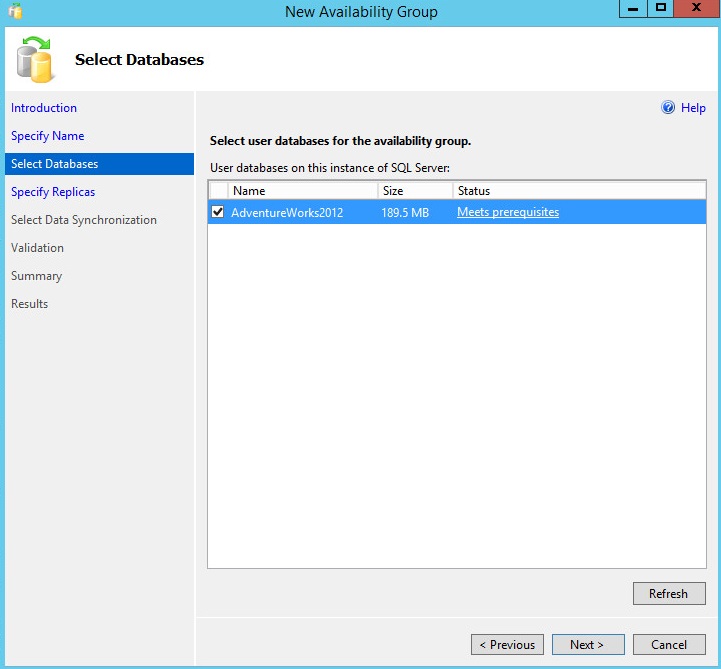
On the "Specify Replicas" dialog you will primarily see the instance of SQL Server where the wizard was initiated. You can add in further replicas, and you must add at least one secondary up to a maximum of 4 (SQL Server 2012) or 8 (SQL Server 2014).
My current configuration provides no automatic failover, we will revisit this later in the article during the Failover test scenarios. After setting the replica options move to the "Endpoints" tab. See diagram 6.9.
Diagram 6.9
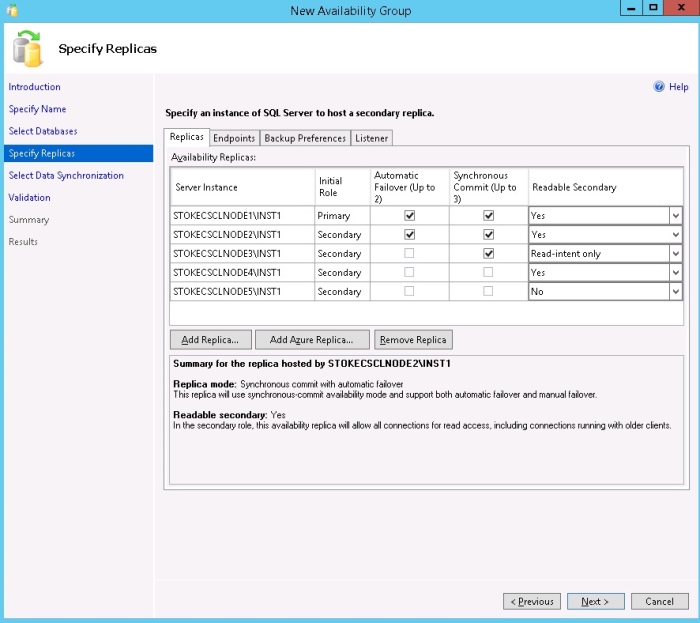
Now we come to the Endpoint configuration. Before we move on I want to digress a little and cover endpoint configuration and how they affect the wizard. If you installed your SQL Server instances using the default account configuration for the SQL Server services, you should see the following endpoint configuration detail (or something similar) as shown in digram 6.10.
Notice the security descriptors in use
- NT SERVICE\MSSQL$INST1
- NT SERVICE\SQLAgent$INST1
These are local accounts and unless you have configured certificate authentication you will receive an authentication failure when attempting to move to the next step in the wizard.
Diagram 6.10
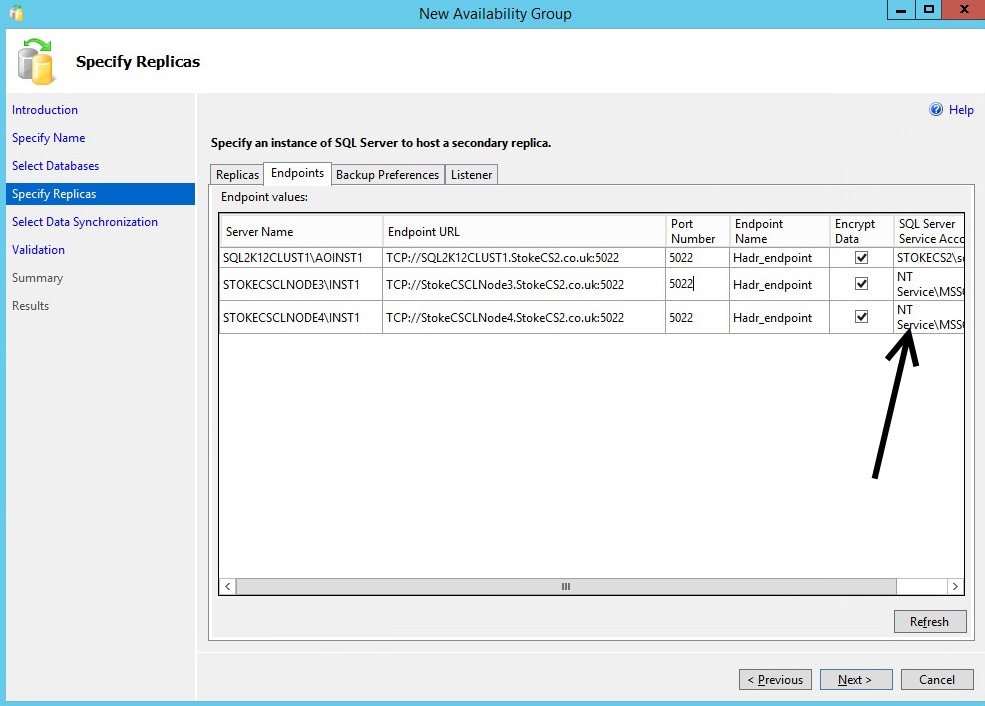
Clicking "Next" and moving to the next step throws the following error, seen in diagram 6.11. To resolve this, ensure that your SQL Server instances use a low privilege domain user account. If you need to, stop at this point and reconfigure your instances to use a domain account, then restart the wizard.
Diagram 6.11
The use of domain accounts itself has ramifications on the Always On group configuration, and this is based around the Always On group listener. For Kerberos authentication to work, the SPN that is generated against the listener Networkname should be bound to a domain user account. This domain user account must be used for the service logon on each replica that will participate in the Always On group, otherwise the SPN registration may fail. The following Microsoft article defines the requirements shown below.
From: http://msdn.microsoft.com/en-us/library/hh213417.aspx#SPNs
A Server Principal Name (SPN) must be configured in Active Directory by a domain administrator for each availability group listener name in order to enable Kerberos for the client connection to the availability group listener. When registering the SPN, you must use the service account of the server instance that hosts the availability replica . For the SPN to work across all replicas, the same service account must be used for all instances in the WSFC cluster that hosts the availability group.
Use the setspn Windows command line tool to configure the SPN. For example to configure an SPN for an availability group named AG1listener.Adventure-Works.com hosted on a set of instances of SQL Server all configured to run under the domain account corp/svclogin2:
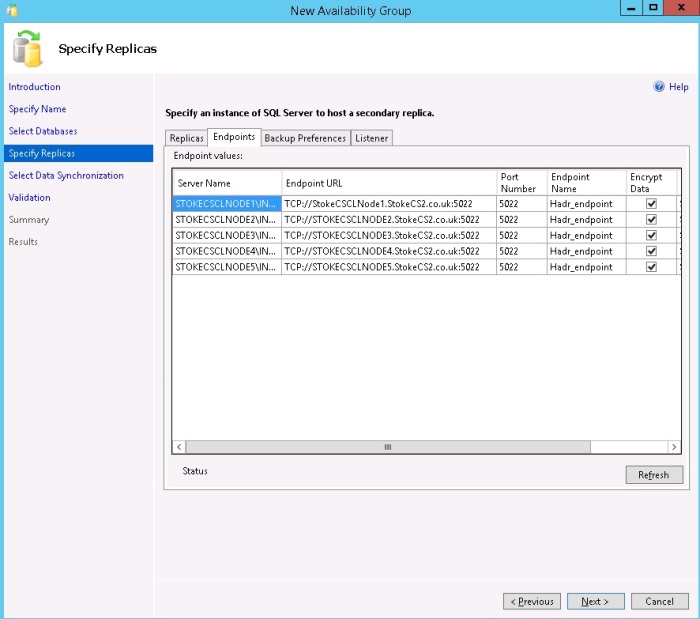
If you used domain user accounts, On the "Endpoints" tab, check and adjust the port numbers to be used. You may of course accept the defaults offered, see diagram 6.12. Once complete, move to the "Backup Preferences" tab.
Diagram 6.12
On the "Backup Preferences" tab, specify your preferred backup options. Here I have chosen to exclude the replica "STOKECSCLNODE4\INST1", preferring the secondary when either of the remaining instances are in the secondary role. Once completed, move to the "Listener" tab. See diagram 6.13
Diagram 6.13
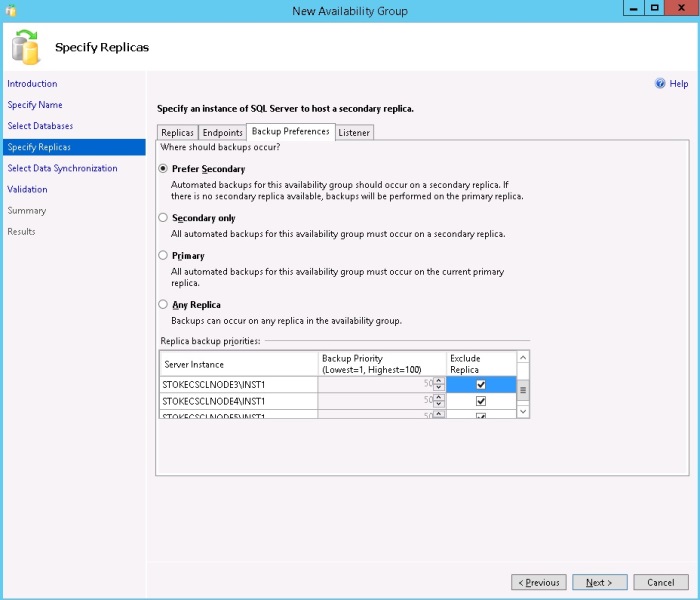
On the "Listener" tab, select your preferred listener configuration. To create a listener you must supply a valid and unique Virtual Networkname, TCP port and Virtual IP Address (if you're not using DHCP). To add a static IP address, select the network mode to "Static" and click the "Add..." button. On the popup dialog you merely need to select the appropriate network and enter the chosen IP address. Once the configuration has been completed click "Next" to continue. See diagram 6.14.
Diagram 6.14
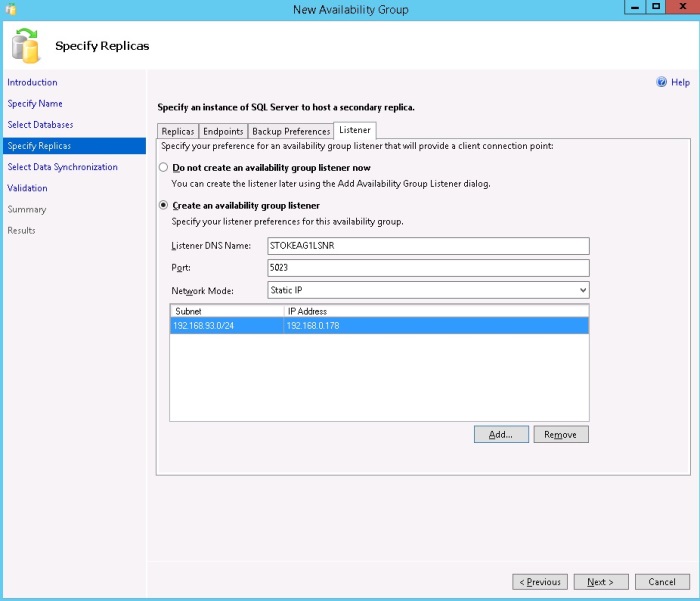
On the "Data Synchronisation" dialog, select the synchronisation type preference. As I have already initiated my secondary databases from a full backup and a transaction log backup, I selected the "Join Only" option. You may, of course, allow the wizard to synchronise the databases for you. Let's just review what each of these options mean.
- Full - this option will take the required full and log backups required to synchronise the secondary databases and then restore them, joining each secondary database to the availability group.
- Join only - You have already restored the secondary databases with NORECOVERY, the wizard will join the secondary databases to the availability group.
- Skip initial data synchronisation - This enables you to restore and join the secondary databases after the wizard has completed. As each secondary database is restored it must be manually joined to the availability group
When you have selected your choice, Click "Next" to continue, as shown in diagram 6.16.
Diagram 6.16
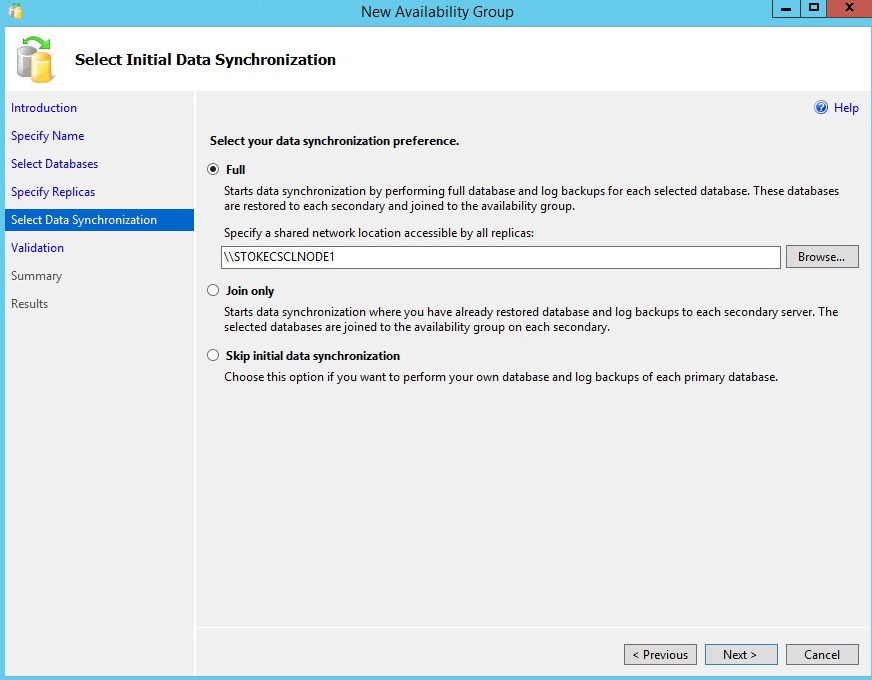
At the "Validation" dialog, review the results and click "Next" to continue. See diagram 6.17.
Diagram 6.17
Click "Finish" to create the Always On Availability group. Shown in diagram 6.18
Diagram 6.18
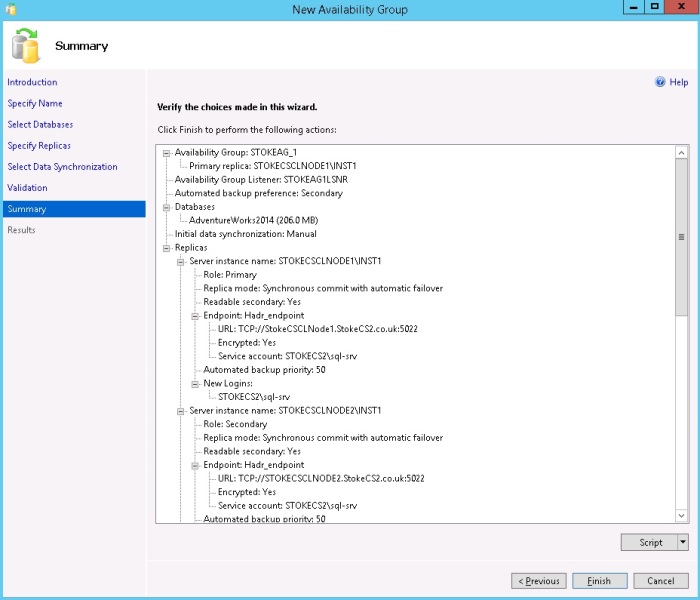
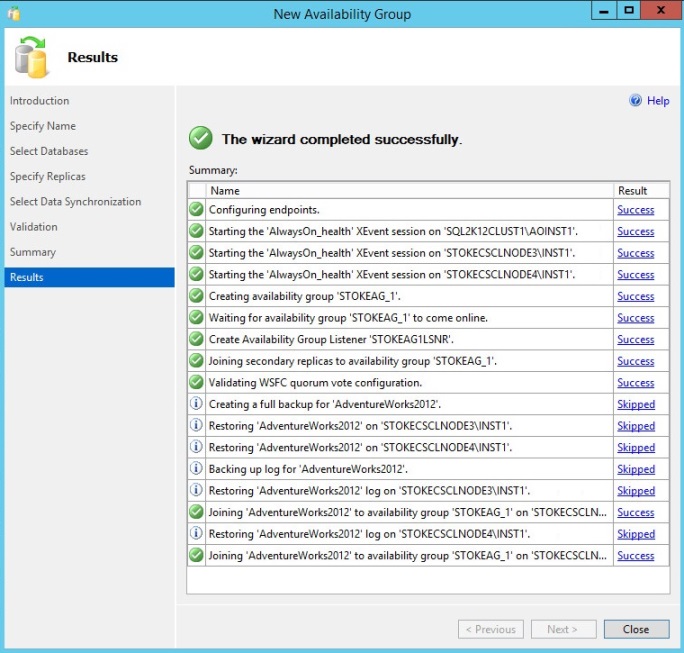
Review the results and click "Close". shown in diagram 6.19
Diagram 6.19.
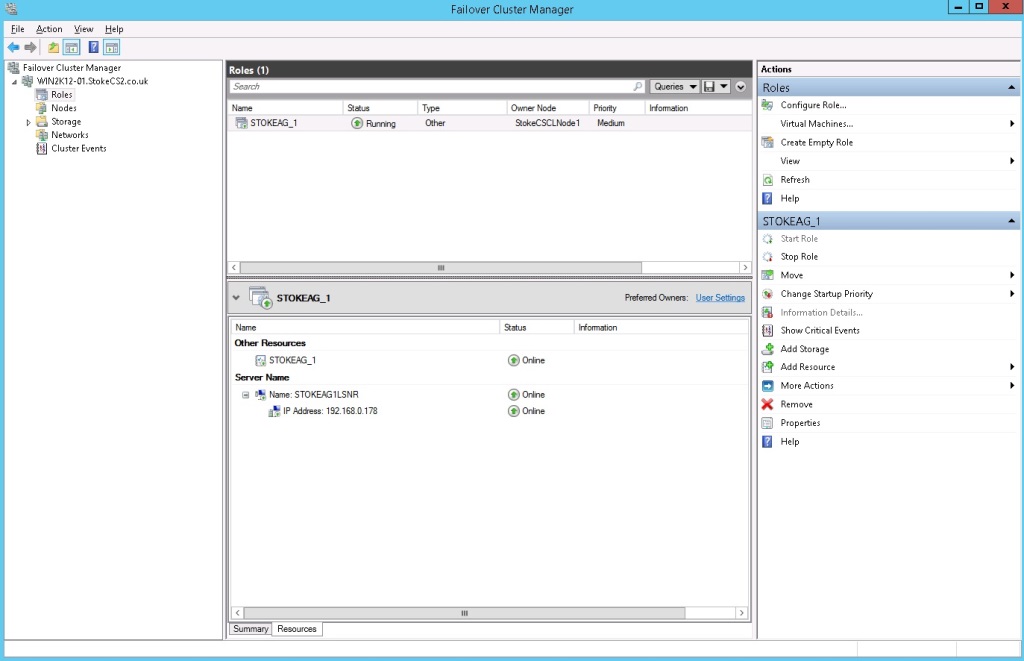
Now that the Always On group has been successfully created, looking at our Windows Server Failover Cluster configuration, we can see below the new clustered role and also the resources assigned to it (in diagram 6.20). We have an Always On cluster role for the Always On group and a clustered Always On resource, both using the Group name we supplied at the start of the deployment wizard. For the listener, we have a clustered Virtual Networkname and Virtual IP address resource.
One of the queries that continually arise on the forums surrounding Always On groups is the necessity for all nodes to be in the same cluster. Well, here's the proof, if you had an Always On group that spanned nodes on 2 separate clusters, how would you be able to failover the clustered resource(s)? The clustered resources are native to the Windows Server Failover Cluster where they have been created; they do not move across clusters.
Note: Do not attempt to manually modify the group preferred owner or resource possible owners lists. Any such attempt is a futile exercise, as these are dynamically configured by the cluster for the Always On group during a failover and depending on the replica configurations. We'll see an example of this later in the article.
Diagram 6.20
TIP: To find the current Always On group Primary's for any Always On groups within the cluster, you may use the following PowerShell command
get-clusterresource -cluster "WindowsClusterName" | where-object{$_.ResourceType -ilike "SQL Server Availability Group"} | ft
Practice manual failovers between the replicas, in SSMS expand the Always On group and right click then select "Failover". You may also use the following T-SQL from the synchronous Secondary for which you wish to assume the Primary role.
ALTER AVAILABILITY GROUP [YourAG] FAILOVER
Observe what happens to the group during these failovers. When you're happy, continue with the rest of the article.
Configure ReadOnly Routing
After creating your highly available Always On Availability Group with a Listener, you'll likely want to configure ReadOnly routing to better manage ReadOnly requests. Before we can redirect clients to a readonly intent replica, we must first create a listener. Then we must configure the read only routing lists for the Always On replicas. We've already created the listener during the group deployment, so now it's time to configure the read only routing lists required to allow connections to the Always On group read intent replicas. Below is the T-SQL code used to configure my instances.
This first code block sets up the secondary role preference for each replica that will be used for Read Only routing. Substitute the items in red, these being the SQL instance Servername and also the routing URL for the database engine itself (not the mirror endpoint URL or the listener URL). From the Primary replica use the following;
ALTER AVAILABILITY GROUP [STOKEAG_1] MODIFY REPLICA ON N'STOKECSCLNODE1\INST1' WITH (SECONDARY_ROLE (ALLOW_CONNECTIONS = READ_ONLY)); ALTER AVAILABILITY GROUP [STOKEAG_1] MODIFY REPLICA ON N'STOKECSCLNODE1\INST1' WITH (SECONDARY_ROLE (READ_ONLY_ROUTING_URL = N'TCP://stokecsclnode1.stokecs2.co.uk:58001')); ALTER AVAILABILITY GROUP [STOKEAG_1] MODIFY REPLICA ON N'STOKECSCLNODE2\INST1' WITH (SECONDARY_ROLE (ALLOW_CONNECTIONS = READ_ONLY)); ALTER AVAILABILITY GROUP [STOKEAG_1] MODIFY REPLICA ON N'STOKECSCLNODE2\INST1' WITH (SECONDARY_ROLE (READ_ONLY_ROUTING_URL = N'TCP://stokecsclnode2.stokecs2.co.uk:58001')); ALTER AVAILABILITY GROUP [STOKEAG_1] MODIFY REPLICA ON N'STOKECSCLNODE3\INST1' WITH (SECONDARY_ROLE (ALLOW_CONNECTIONS = READ_ONLY)); ALTER AVAILABILITY GROUP [STOKEAG_1] MODIFY REPLICA ON N'STOKECSCLNODE3\INST1' WITH (SECONDARY_ROLE (READ_ONLY_ROUTING_URL = N'TCP://stokecsclnode3.stokecs2.co.uk:58001'));
The next step is to specify the routing preferences for each replica while in the primary role,
ALTER AVAILABILITY GROUP [STOKEAG_1] MODIFY REPLICA ON N'STOKECSCLNODE1\INST1' WITH (PRIMARY_ROLE (READ_ONLY_ROUTING_LIST = ('STOKECSCLNODE3\INST1', 'STOKECSCLNODE2\INST1', 'STOKECSCLNODE1\INST1'))); ALTER AVAILABILITY GROUP [STOKEAG_1] MODIFY REPLICA ON N'STOKECSCLNODE2\INST1' WITH (PRIMARY_ROLE (READ_ONLY_ROUTING_LIST = ('STOKECSCLNODE3\INST1', 'STOKECSCLNODE1\INST1', 'STOKECSCLNODE2\INST1'))); ALTER AVAILABILITY GROUP [STOKEAG_1] MODIFY REPLICA ON N'STOKECSCLNODE3\INST1' WITH (PRIMARY_ROLE (READ_ONLY_ROUTING_LIST = ('STOKECSCLNODE2\INST1', 'STOKECSCLNODE1\INST1', 'STOKECSCLNODE3\INST1')));This last section of code configures each of the specified replicas Primary role to include only the Secondary replicas you wish to offload to ReadIntent connections to. Typically you may specify all replicas, but that may not always be the case. If specifying all replicas, you should ideally specify each Primary as the last connection in its routing list. The item "READ_ONLY_ROUTING_LIST" is enumerated from left to right, most preferred to least preferred.
Now that the ReadOnly routing lists have been configured we can test a ReadOnly intent connection via the listener. With the primary set to STOKECSCLNODE1\INST1, a SQLCMD query specifying ReadOnly intent is directed to an alternative node as specified in the scripts above, in this case STOKECSCLNODE3\INST1. See diagram 6.21.
Diagram 6.21
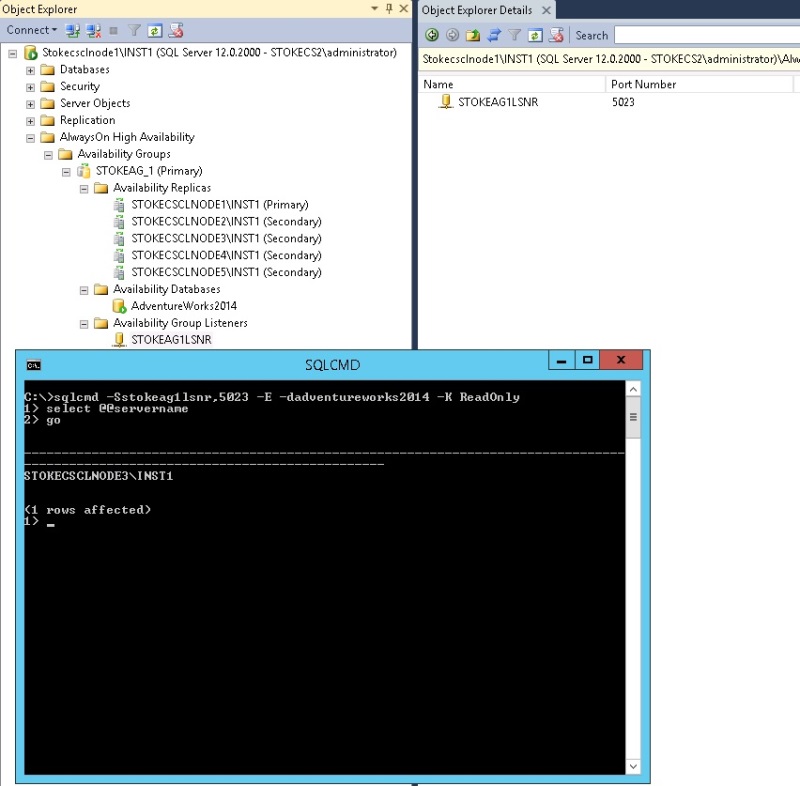
The ReadOnly routing setup seems to have been a source of some confusion previously. In reality, once you are sure of the replicas you require, the scripts are easy to configure. The most important thing to remember is that the ReadOnly URL you specify is the URL of the database engine itself. It is not the database mirror endpoint URL or the listener URL. Practice a little with the ReadOnly intent scenarios, see if you are able to get a ReadOnly intent connection via a SQL Server Management Studio new query window. When you're happy, proceed with the article.
Suspend Data Movement
This is a fairly simple feature. The Always On group offers the ability to suspend data movement between the Always On databases at the Primary or Secondary levels. In some cases this suspension occurs automatically. Let's see quickly now, how this is so.
As we know, if you have an Always On group Primary failure and have no automatic failover replicas, the group secondary replicas will enter the "Resolving" state. This requires either a manual failover to a synchronous replica or a forced failover to an asynchronous replica. It is when performing a forced failover to an asynchronous replica and the data movement is suspended automatically, you are required to actually reconnect the replica databases to the new asynchronous Primary. A typical scenario for this is detailed in the testing Failover Scenarios section.
Note: When an asynchronous replica is forced as a Primary, transactions are sent to all new Secondarys asynchronously regardless of their setting.
Suspending data movement on a primary stops the synchronisation between the Primary and the Secondary's. The Primary database is still online and available. Transaction log growth can be an issue on a busy database, so care should be taken here to ensure that the suspension does not cause the transaction log to grow wildly or even fill completely.
Suspending data movement on a secondary database sets the database status to "Not Synchronising", and the secondary database becomes unavailable. Again unsent log records can build at the primary. Resuming data movement synchronises the database and makes the secondary database available again.
Be aware that another reason for suspended data movement occurs when the group fails over from a replica which is at version SQL Server 2012 to a replica that is at a higher version, SQL Server 2014 for example. Just like all of the other SQL Server HA techniques, once you move forward in database version you cannot revert, it is a one-time move. It follows then that just like all of the other HA techniques you may also use an Always On Availability group to move a database up to later SQL Server versions.
Testing Failover Scenarios and Observing the Results
We will look at automatic and forced failover below. We will also look at the loss of a quorum and its effect on your Availability Group.
Automatic Failover
For automatic failover to be active you must have two synchronous partners that are configured for automatic failover, otherwise failover will be a manual process. In the first scenario, I have the Primary role on replica STOKECSCLNODE3\INST1. I have the group configured so that STOKECSCLNODE1\INST1 is also a synchronous, automatic replica. I'm going to drop the Public NIC for the machine STOKECSCLNODE3, which will simulate a hardware failure, with the node dropping off the client network. An automatic failover will occur to STOKECSCLNODE1\INST1.
I'll logon via terminal services to node 1 and via the Hypervisor console, disconnect the Public vNIC for node 3. Before the failure, here is my Always On cluster role active on Node 3, shown in diagram 6.23.
Diagram 6.23
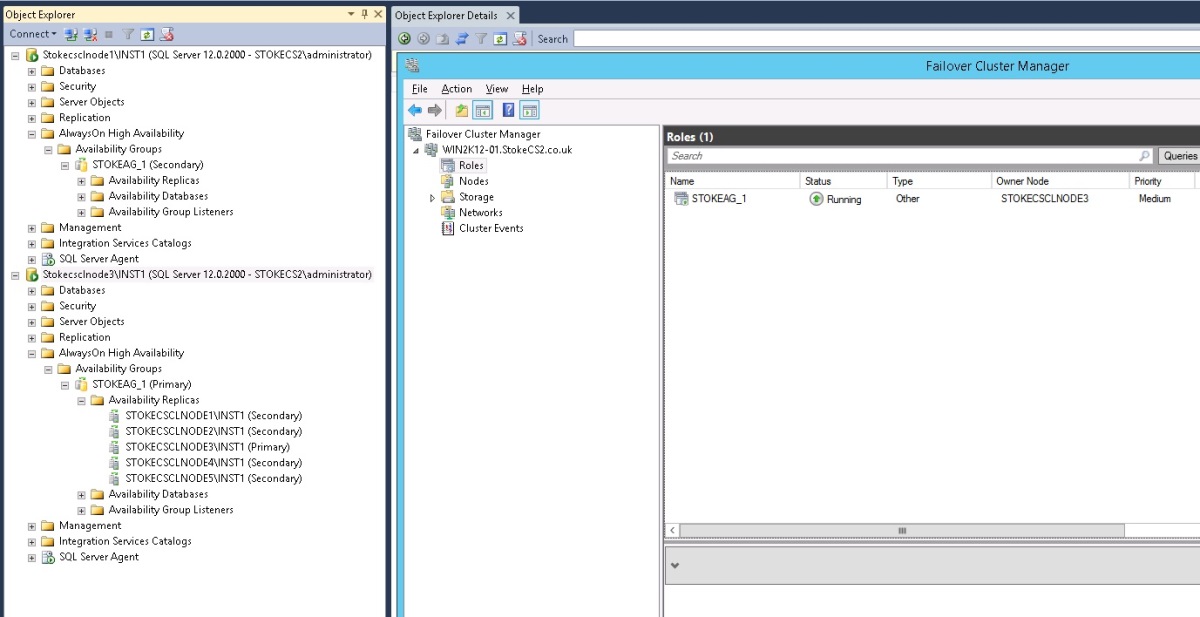
After the failure we can see the Always On cluster role coming online on Node 1 in diagram 6.24. That does pretty much what you'd expect and essentially the same as synchronous database mirroring with a witness.
Diagram 6.24
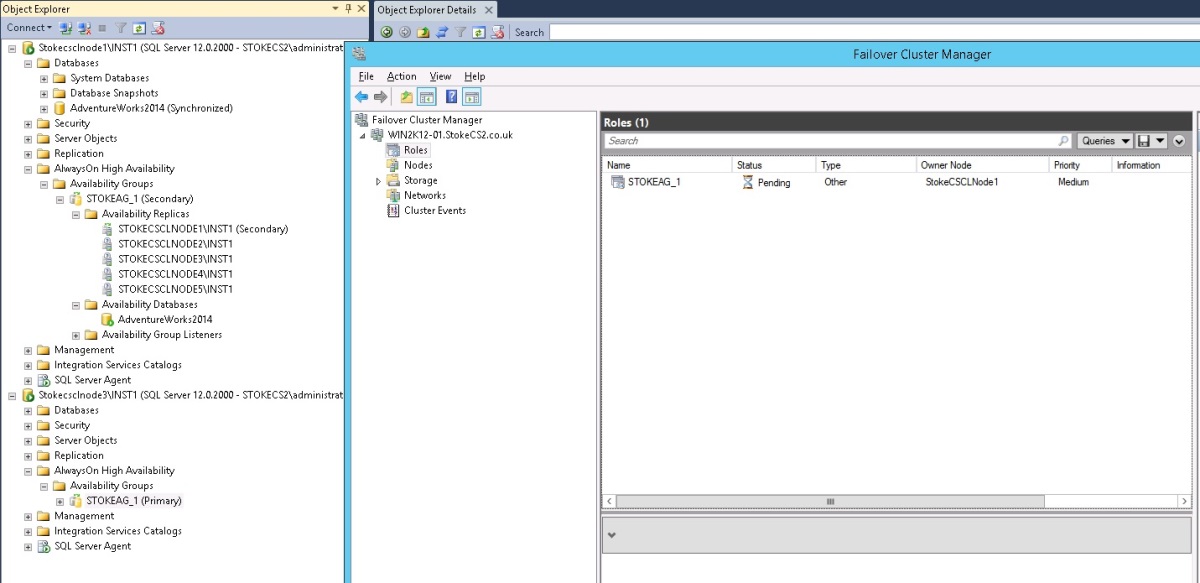
Manual and Forced Failover
Should the need arise to failover to a synchronous or asynchronous partner upon failure of the Primary, you will be asked to confirm during the failover wizard that you wish to accept the potential data loss when failing over to an asynchronous partner. This will then enroll the selected replica as the new group Primary. But what about failing back? how is this achieved?
For this test scenario, I'm going to configure the Always On group so that there are no automatic failover partners. I'm then going to maliciously terminate the SQLSERVR.EXE process on the Primary replica STOKECSCLNODE1\INST1, which is a synchronous replica. This will simulate a software failure, leave the remaining Always On group replicas in the resolving state. The loss of the Primary is catastrophic in this scenario where no automatic failover partners exist.
I will then perform a forced failover to STOKECSCLNODE4\INST1, which has been reconfigured as an asynchronous replica. During the forced failover, the wizard requires confirmation that I wish to accept the potential data loss.
To start, I have terminated the process on node1. This fails the Always On cluster role as shown in diagram 6.25.
Diagran 6.25
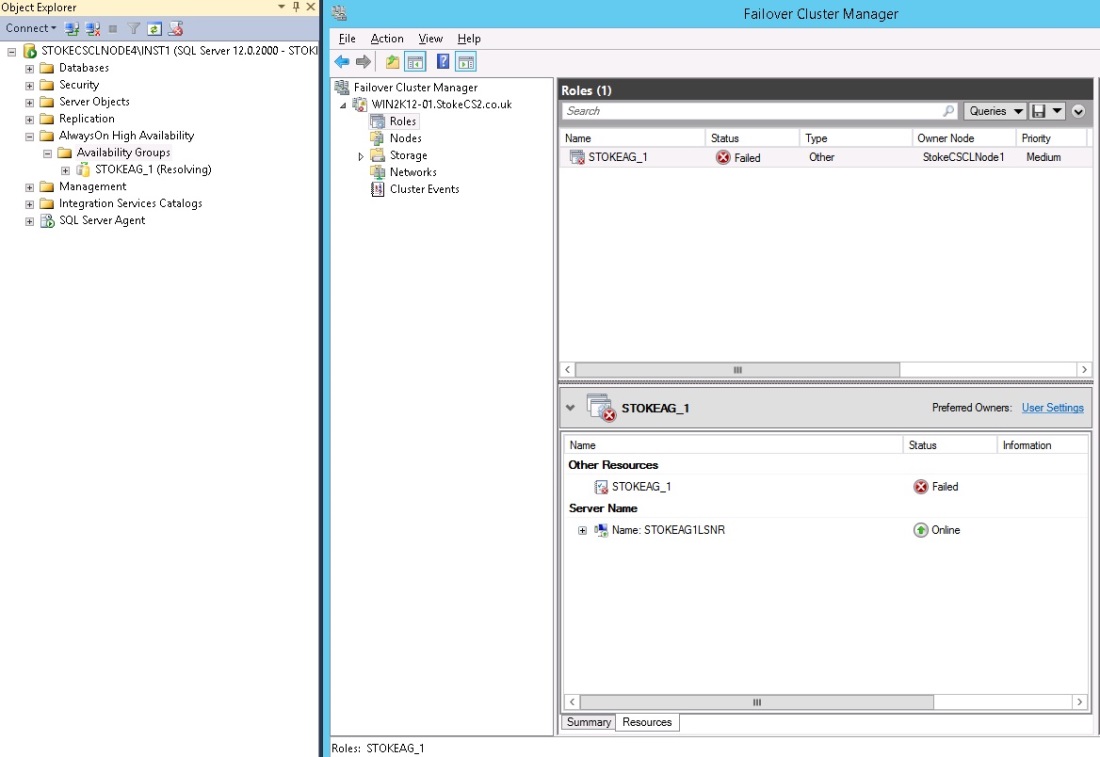
To implement a forced failover, right click the Availability group on Node 4 and select "Failover". This will invoke the failover wizard. Shown below in diagram 6.26 is the selection screen for the asynchronous replica. When launching the failover from a secondary replica or a replica that is in the resolving state, you are offered only that instance as a target. Click "Next" through this screen.
Diagram 6.26
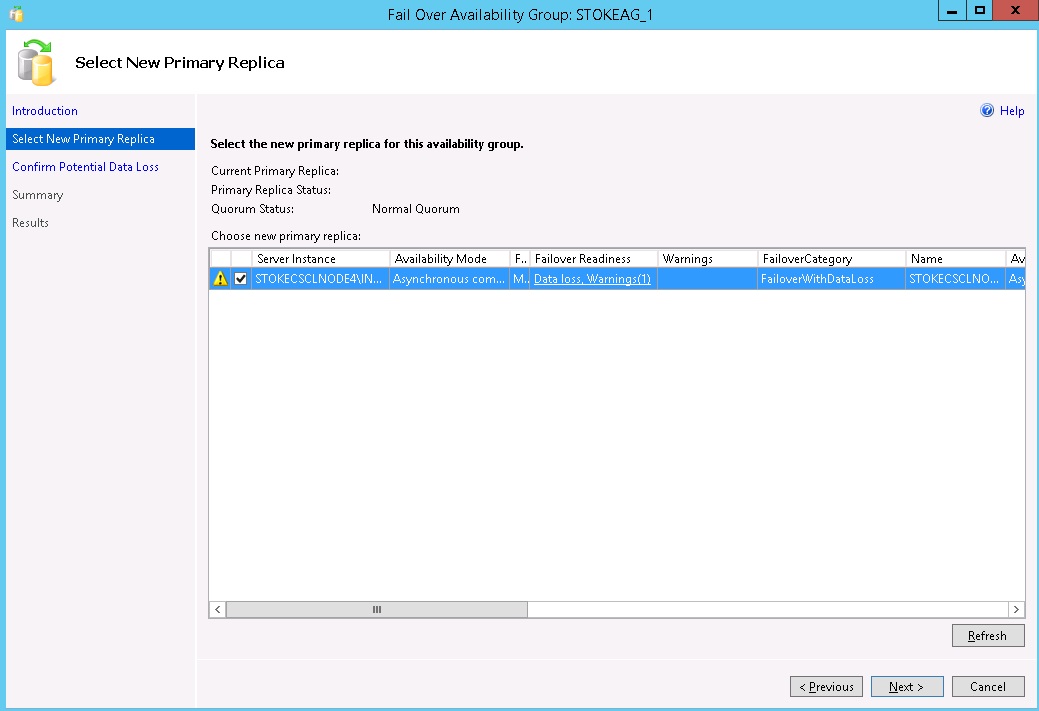
During the forced failover, I need to accept the prospect of data loss on this asynchronous partner. Check the box and click "Next" as shown in diagram 6.27.
Diagram 6.27
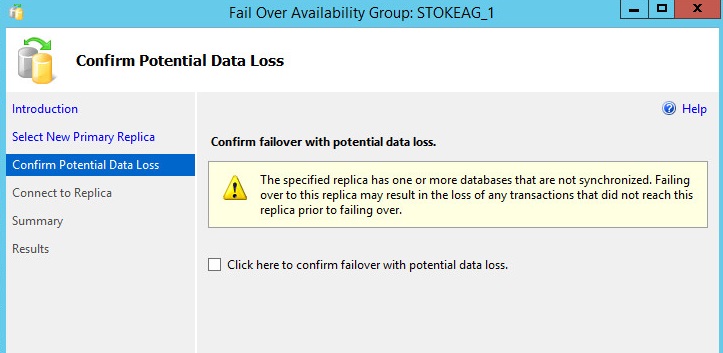
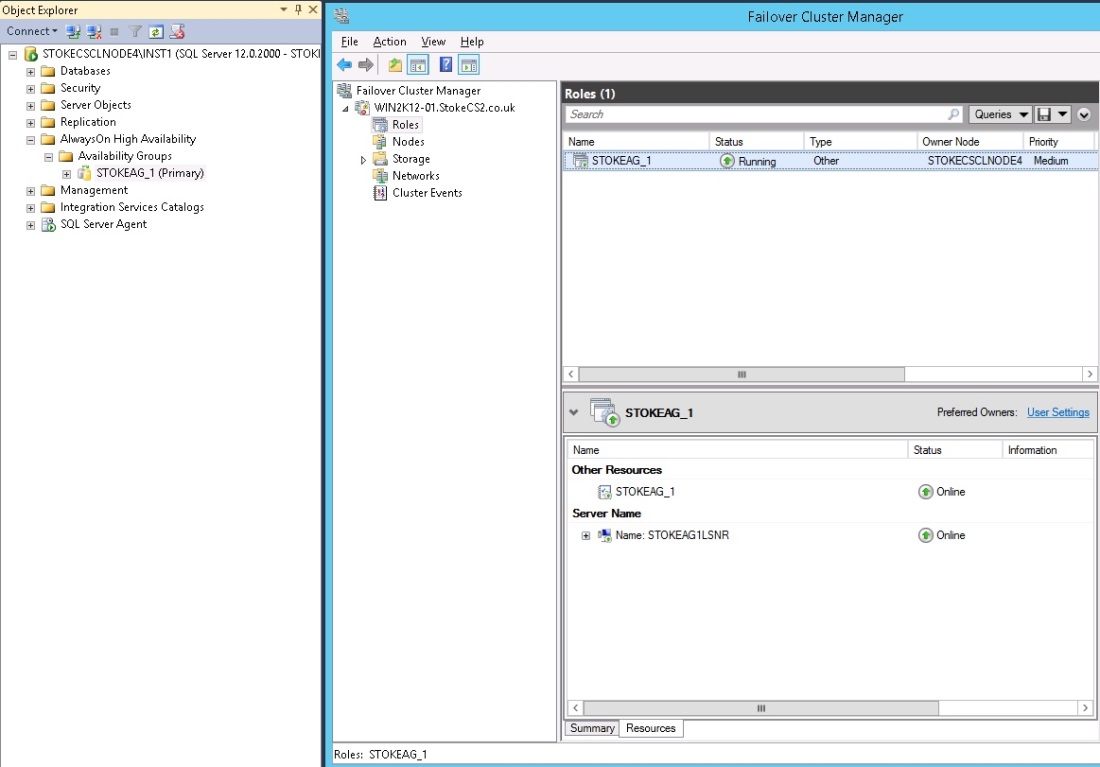
After completing the failover wizard, the Always On cluster role is back online on node 4, shown in diagram 6.28.
Diagram 6.28
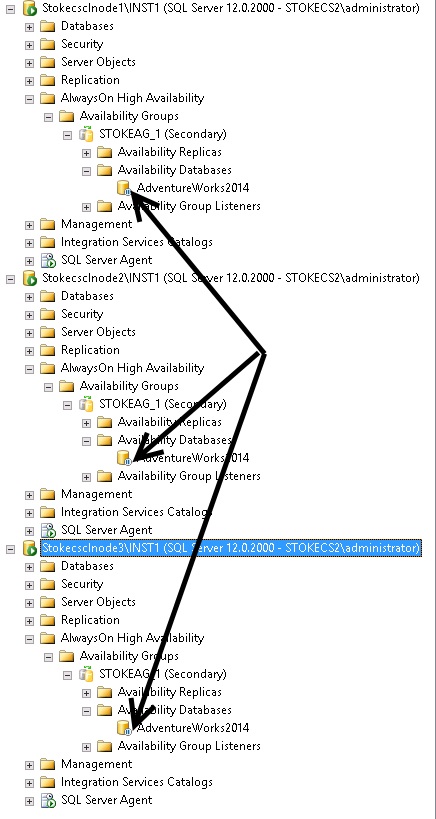
I'll bring the SQL Server instance on STOKECSCLNODE1 back online, and it will join the group with the data movement suspended. Notice below that after the failover to the asynchronous replica, the remaining partner databases have had data movement suspended, indicated by the little pause symbol against each secondary database in diagram 6.29.
Diagram 6.29
At this point I set my replica on STOKECSCLNODE4 to synchronous mode and right clicked each database and selected "Resume data movement" to synchronise the databases. When failing the group back over at a later point there will be no further possibilities of data loss. It should be noted that leaving the replica as an asynchronous partner will have an impact when failing back at a later time and also sends transactions asynchronously regardless, as mentioned previously.
You may also force failover to a synchronous replica. However, in the synchronous mode the data is protected.
When performing a manual failover to a synchronous partner you merely need to select the required partner replica, and the Primary role will be transferred. If you are failing over from a replica configured as a synchronous\automatic partner to a partner that is not configured as automatic, the wizard will show a message URL in the replica status indicating that the failover mode in the group will be changed. Remember you may have only two partners configured for automatic failover. As long as a manual failover is performed between these replicas, automatic failover in the group will be maintained.
Loss of Quorum
This is an extreme case of cluster outage. This time I'll simulate a scenario where the cluster loses quorum. Although half the nodes (votes) will be online, the Always On group will not. As such the Always On databases within this group will be unavailable due to the cluster service going offline on the remaining nodes. When attempting to open the "databases" view in SSMS you will see an error similar to the one below in diagram 6.30.
Diagram 6.30

For this test I forcibly powered off three nodes of my fve node cluster to simulate a sudden loss of votes. The dynamic weight has no chance to recalculate the vote change, and with only two votes online, the Always On group clustered resource goes offline. Any attempt to open the Always On databases on the remaining nodes resulted in the error above. This is why it is important to ensure you configure the quorum witness appropriately for your cluster configuration.
Cluster Role Resource Status During Failover
It's worth taking a look at the cluster resource status' at this point to understand exactly what is happening to the cluster role during these outages.
When failing over the Always On group to a manual synchronous partner, this modifies the clustered role preferred owners to just that node. Also the possible owners list on the Always On resource is set to just that node, too. For example, we have the following scenario. Currently the Always On group Primary is active on node1, the Primary is synchronous with manual failover. Let's look at the owners lists for the cluster role and the Always On resource, shown in diagram 6.31.
Diagram 6.31
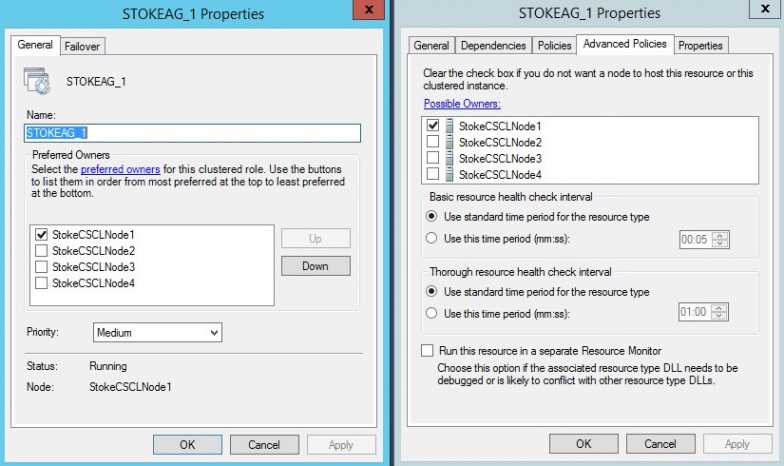
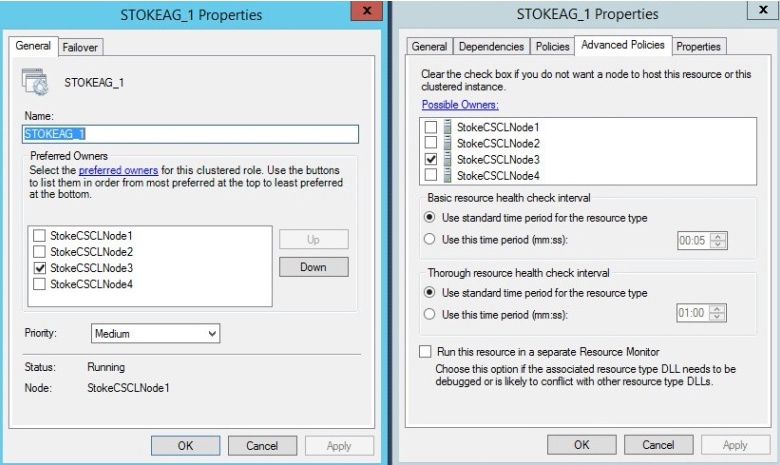
A failover is initiated to a synchronous partner STOKECSCLNODE3\INST1. After a failover to the partner the resource lists have now changed, the role preferred owner and the clustered resource possible owner are now set to STOKECSCLNODE3, as seen in diagram 6.32.
Diagram 6.32
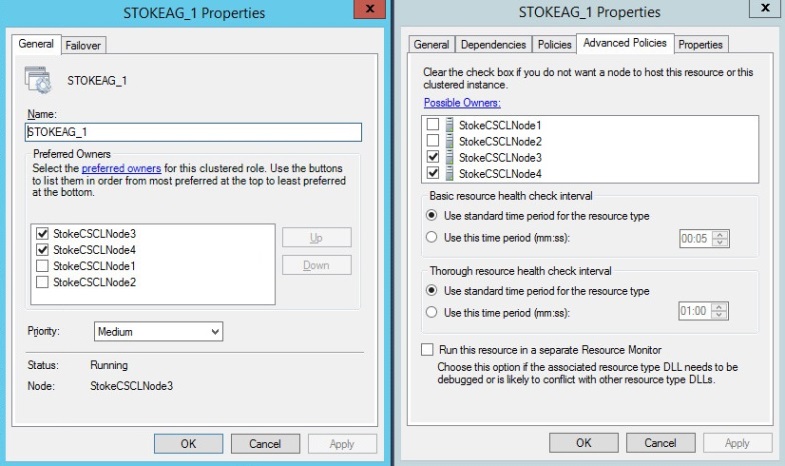
Where the group has two synchronous replicas that are configured for Automatic failover, the resource lists differ. I reconfigured my Always On group to have the replicas
- STOKECSCLNODE3\INST1
- STOKECSCLNODE4\INST1
configured as synchronous replicas with automatic failover. The role preferred owners and resource possible owners lists are now as follows in diagram 6.33:
Diagram 6.33
Important: These properties are dynamically managed, there is no need to intervene.
Summary
So there we have it. This concludes level 6, we've covered the Always On group creation\configuration and also looked at some failover scenarios. We also looked at the quorum configuration and key feature information. Lastly, we looked at failover modes and how they work within the group. I hope you find this series useful, don't forget to tune in for Level 7.
As always, have fun and if you're stuck post in the discussion thread, I'll help all I can.