

At times there is a need to run a large set of data modifications at once. In this article, I will analyze the advantages of grouping the transactions of these modifications. Although these tests are run through SSMS, the results will be similar for any application executing DML statements against SQL Server.
The test set
The test set of this article is a simple table with an ID column and an integer column, which will hold a random integer. The table will be populated with 250,000 rows.
create table TestTable( TestTableID int identity(1,1), col1 int )
One transaction per statement
Now let's populate the table. In our base case, this table is populated with the following loop:
declare @x int select @x = 0 while @x < 250000 begin select @x = @x + 1 insert into TestTable(col1) select @x + rand() * 10 end
This script commits each insert individually. Profiler reports it as using 14487 CPU and returning in 58769 ms
Batched Transactions
Now let's see what happens when we group our inserts and commit them in batches of 10 at a time:
truncate table TestTable begin tran declare @x int select @x = 0 while @x < 250000 begin select @x = @x + 1 if @x % 10 = 0 begin commit begin tran end insert into TestTable(col1) select @x + rand() * 10 end commit
Profiler reports this script as using 6953 CPU and returning in 12228 ms. Already our duration has been reduced from 59 seconds to 12 seconds and our CPU has been reduced by over 53%. Updates show a similar trend.
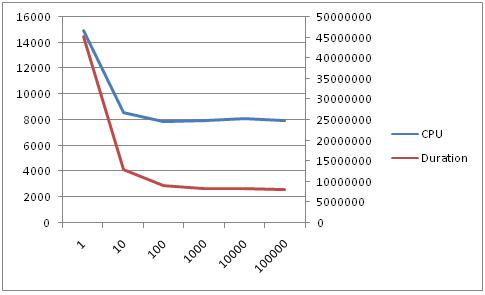
From these results, it is safe to conclude that performance can be optimized by batching transactions. In fact, it turns out that the larger batches will give an even greater performance boost. Using the same script to batch the transactions, below is a chart of resource usage by batch size. Note that the values on the X axis are exponential.
The following is a chart of the script doing updates instead of inserts. It shows a similar trend.
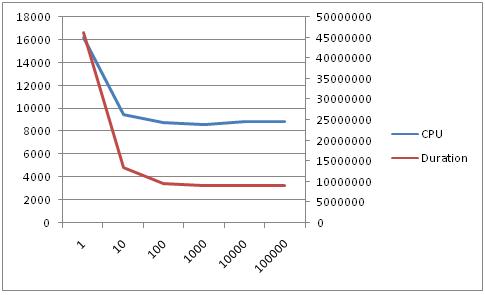
Some testing showed that the improvement for this script on the system it was being tested on tends to level out at round 80 inserts/updates per transaction. Results will vary based on hardware and software settings.
CAUTION: The longer your transaction is open and the more rows it touches, the more likely it is to block other processes. This should always be taken into consideration when running multiple statements within a transaction. This method is recommended only when contention is not a concern.
Implicit Transactions
As an aside, batching transactions may be more easily done using the implicit_transactions mode. Setting implicit_transactions on is the equivalent of having the ODBC setting AutoCommit off. This setting effectively tells SQL Server that at the beginning of the session and following every commit and rollback, to implicitly start a new transaction that has to be explicitly committed or rolled back. For more information on the implicit_transactions setting, see http://msdn.microsoft.com/en-us/library/ms188317.aspx
Below is the script for 10 rows per transaction used in the test above, but written with the implicit_transactions set to on. This is functionally equivalent to the script that was used in the test will produce the same results. The main advantage to using the setting is that the begin transaction statement is implied:
set implicit_transactions on -- Ten rows per transaction truncate table TestTable declare @x int select @x = 0 while @x < 250000 begin select @x = @x + 1 if @x % 10 = 0 commit insert into TestTable(col1) select @x + rand() * 10 end commit

