

This article describes a technique to improve the efficiency of searching on columns using an 'ends with' type of search and the LIKE operator. For example, suppose you have a query like this:
SELECT Name, JobTitle, Telephone FROM People WHERE Name LIKE '%son'
If you have ever run this kind of query you may have noticed that even if you have created an index on the column you are searching, the SQL Server optimiser will at best use an index scan rather than a seek. This is because even though the values in the index will be in order, every value in the table still has to be checked to see if it ends with the search text.
My solution to this is to exploit the T-SQL function REVERSE, which takes a string of characters and returns a string containing those characters in reverse order i.e. REVERSE('ABC') is equal to 'CBA'. We can then put the result of this value in another column in the table (using a computed column) and index that column. Because an "ends with" search on a piece of text is equivalent to a "starts with" search on the reverse of that same text, we will get the same results, but now the SQL optimiser can use an index seek.
To illustrate this I will create a table to do some searches on and compare the execution plan and statistics before and after implementing the enhancement. A script with all the code below accompanies this article.
First we start SQL Server Management Studio and create a table with a textual column. We can do this easily by taking data from the sys.all_parameters catalog view. On my system this view has 6756 rows.
SELECT object_id, name, system_type_id
INTO test_table
FROM master.sys.all_parameters
Next we create an index we would normally expect to have on this sort of table for optimising searches.
CREATE NONCLUSTERED INDEX ix_name ON test_table (name ASC)
Now let's test an "ends with" query and see what happens.
Turn on statistics IO to show us how many logical reads are going on when we search:
SET STATISTICS IO ON
Also, press CTRL+M to include the actual execution plan in the output. I'll search for names in the table which end with "ID". The query looks like this:
SELECT NAME FROM TEST_TABLE WHERE NAME LIKE '%ID'
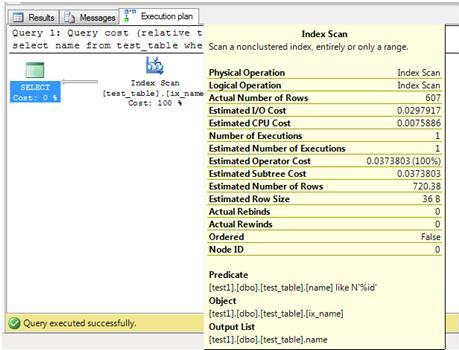
This returns 607 rows and the statistics output shows the following
(607 row(s) affected)
Table 'test_table'. Scan count 1, logical reads 39, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
The execution plan is shown below. You can see that there was an index scan operation to look through every row, testing for names which end with 'ID'.
Now we will implement the reverse index. To do this we create a computed column to stored the reversed values.
ALTER TABLE test_table ADD name_REVERSED AS REVERSE(name)
...and add an index to the new column...
CREATE NONCLUSTERED INDEX IX_REVERSED ON TEST_TABLE (NAME_REVERSED ASC) INCLUDE (NAME)
Note: We have used INCLUDE here to store the actual name value in the index because this is the value we are going to want to return. We could have omitted this and REVERSEd the name_REVERSED column instead. In my tests I found slightly less reads without the INCLUDE but slightly more CPU time used to do the reverse.
We now want execute the same query we ran before and see what happens. Because we are searching reversed values, we also have to reverse the input, so whereas the query was...
SELECT NAME FROM TEST_TABLE WHERE NAME LIKE '%ID'
...we need to change this into...
SELECT NAME FROM TEST_TABLE WHERE NAME_REVERSED LIKE 'DI%'
If we look at the statistics and plan again we find the following:
(607 row(s) affected)
Table 'test_table'. Scan count 1, logical reads 8, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
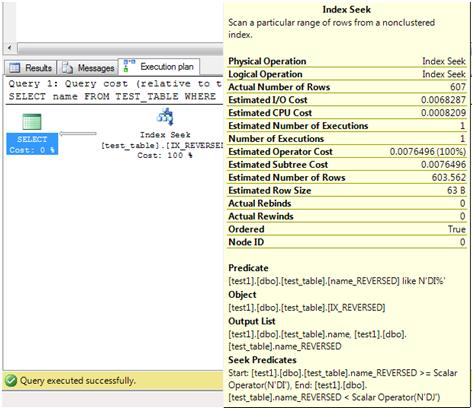
So the logical reads has fallen from 39 to 8, which is quite a lot and would scale up nicely to a lot of IO savings for larger tables, for example a phone book. We can see from the execution plan that this is due to the fact we now have a nice efficient index seek rather than a scan.
Admittedly we do need to add extra columns and indexes for each column we want to search on in this way, which could become cumbersome if there are lots of them. Also we will need to make sure any stored procedures which take in a user search text automatically reverse the search text before executing the query as well as specifying the new column. However if you only have a few columns you need to do this for in your database you might find that this is a relatively simple way to improve search performance.
Ben Seaman
