

The data warehouse in Microsoft Fabric was re-written to use OneLake storage. This means each and every table in the warehouse is based on the Delta file format. Staying away from single transactions will keep the warehouse performing at its best. We already learned in a prior article that T-SQL insert statements can be used to add rows to a table. Are there any other ways to insert or update rows in our warehouse?
Business Problem
Azure Data Factory has been a popular Extract, Load and Translate (ELT) tool. Data pipelines exist in the Azure Data Factory, Azure Synapse, and Microsoft Fabric services. Therefore, we are going to explore how to mesh data from Amazon Web Services (AWS) S3 buckets, Azure Storage Containers, and Google Cloud Platform (GCP) buckets into a final table in our warehouse. The Standard & Poor's 500 is a stock market index tracking the stock performance of 500 or so of the largest companies listed on stock exchanges in the United States. We will be using five years’ worth of data which equates to over 2,500 comma-separated values (CSV) files. The performance of the Data Pipeline will be compared to the new COPY INTO statement. Let the best algorithm win on speed of execution.
Fabric Warehouse
The data model is always the foundation of any analytical solution. Today, we are going to create a warehouse named dw_stock_data. Please open a new query to run the following T-SQL statements. Schemas are a great way to segregate our staging data from our active tables. See the documentation for more information about schemas and tables.
-- -- Make schemas -- -- active CREATE SCHEMA active; GO -- stage CREATE SCHEMA stage; GO
To prevent casting errors in the data pipelines, the staging table is defined using varchar columns. The active table is defined with the correct data types. We will use a view to try to cast the data to the correct data types. See the code below re-creates the tables each time it is executed.
-- -- Stage table -- -- Delete existing table DROP TABLE IF EXISTS [stage].[snp500] GO -- Create new table CREATE TABLE [stage].[snp500] ( ST_SYMBOL VARCHAR(32) NOT NULL, ST_DATE VARCHAR(32) NOT NULL, ST_OPEN VARCHAR(32) NULL, ST_HIGH VARCHAR(32) NULL, ST_LOW VARCHAR(32) NULL, ST_CLOSE VARCHAR(32) NULL, ST_ADJ_CLOSE VARCHAR(32) NULL, ST_VOLUME VARCHAR(32) NULL ); -- -- Active table -- -- Delete existing table DROP TABLE IF EXISTS [active].[snp500] GO -- Create new table CREATE TABLE [active].[snp500] ( ST_SYMBOL VARCHAR(32) NOT NULL, ST_DATE DATE NOT NULL, ST_OPEN REAL NULL, ST_HIGH REAL NULL, ST_LOW REAL NULL, ST_CLOSE REAL NULL, ST_ADJ_CLOSE REAL NULL, ST_VOLUME BIGINT NULL );
The view seen below is called vw_snp500. It uses the TRY_CAST function to format the staging data for the active table.
--
-- Create view
--
-- Delete existing s.p.
DROP VIEW IF EXISTS stage.vw_snp500
GO
-- Create new s.p.
CREATE OR ALTER VIEW stage.vw_snp500
AS
SELECT
ST_SYMBOL,
TRY_CAST(ST_DATE AS DATE) AS ST_DATE,
TRY_CAST(ST_OPEN AS REAL) AS ST_OPEN,
TRY_CAST(ST_HIGH AS REAL) AS ST_HIGH,
TRY_CAST(ST_LOW AS REAL) AS ST_LOW,
TRY_CAST(ST_CLOSE AS REAL) AS ST_CLOSE,
TRY_CAST(ST_ADJ_CLOSE AS REAL) AS ST_ADJ_CLOSE,
TRY_CAST(ST_VOLUME AS BIGINT) AS ST_VOLUME
FROM
stage.snp500
WHERE
ST_VOLUME <> 0
;
GO
The first stored procedure clears the staging table. Please see the code below.
-- -- Clear staging table -- -- Delete existing s.p. DROP PROCEDURE IF EXISTS stage.sp_clear_staging GO -- Create new s.p. CREATE OR ALTER PROCEDURE stage.sp_clear_staging AS TRUNCATE TABLE stage.snp500 GO
Not all T-SQL statements are supported by the Fabric Warehouse. The MERGE statement is currently not supported. The second stored procedure either INSERTS new records or UPDATES existing records in the active table. This action is commonly known as an UPSERT.
--
-- Upsert stage into active
--
-- Delete existing s.p.
DROP PROCEDURE IF EXISTS stage.sp_upsert_active
GO
-- Create new s.p.
CREATE OR ALTER PROCEDURE stage.sp_upsert_active
AS
BEGIN
-- UPDATE ACTION
UPDATE TRG SET
ST_OPEN = SRC.ST_OPEN,
ST_HIGH = SRC.ST_HIGH,
ST_LOW = SRC.ST_LOW,
ST_CLOSE = SRC.ST_CLOSE,
ST_ADJ_CLOSE = SRC.ST_ADJ_CLOSE,
ST_VOLUME = SRC.ST_VOLUME
FROM stage.vw_snp500 as SRC
LEFT JOIN active.snp500 as TRG
ON (TRG.ST_SYMBOL = SRC.ST_SYMBOL AND TRG.ST_DATE = SRC.ST_DATE)
WHERE TRG.ST_SYMBOL IS NOT NULL;
-- INSERT ACTION
INSERT INTO active.snp500
(
ST_SYMBOL,
ST_DATE,
ST_OPEN,
ST_HIGH,
ST_LOW,
ST_CLOSE,
ST_ADJ_CLOSE,
ST_VOLUME
)
SELECT SRC.*
FROM stage.vw_snp500 as SRC
LEFT JOIN active.snp500 as TRG
ON (TRG.ST_SYMBOL = SRC.ST_SYMBOL AND TRG.ST_DATE = SRC.ST_DATE)
WHERE TRG.ST_SYMBOL IS NULL;
END
GO
Now that we have a data model, we can design the ELT pipeline to fill the tables with S&P 500 stock data from CSV files.
AWS Data Pipeline
The pipeline design for all three cloud vendors is essentially the same. The connection to read both the metadata and files is the only difference between all three data pipelines. The algorithm for the pipeline is as follows:
- Use pipeline parameter for source folder
- Clear staging table that has varchar fields
- Get listing of files for a given folder
- Filter listing for MSFT files
- For each file, copy data from source folder to staging table
- Execute UPSERT stored procedure
The first step of the pipeline is to clear the staging table. This can be done with a call to a stored procedure.
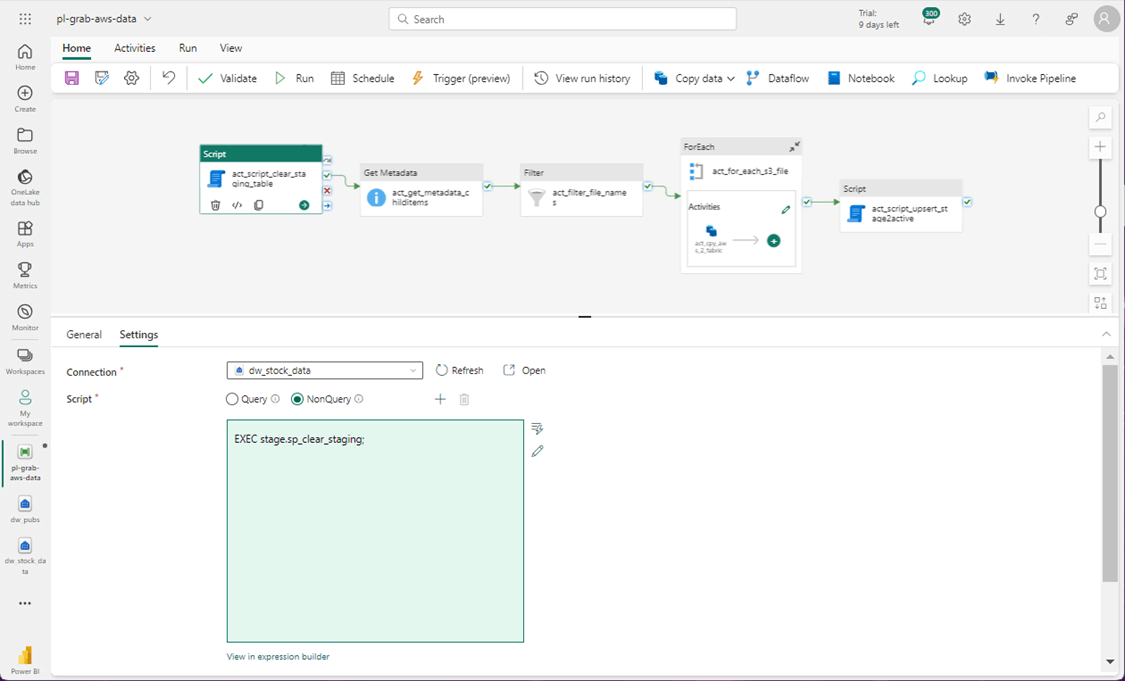
The Amazon S3 connection is used in both the metadata and copy activities. For a given folder, we want to retrieve all the file names. The image below shows the details of the metadata activity.
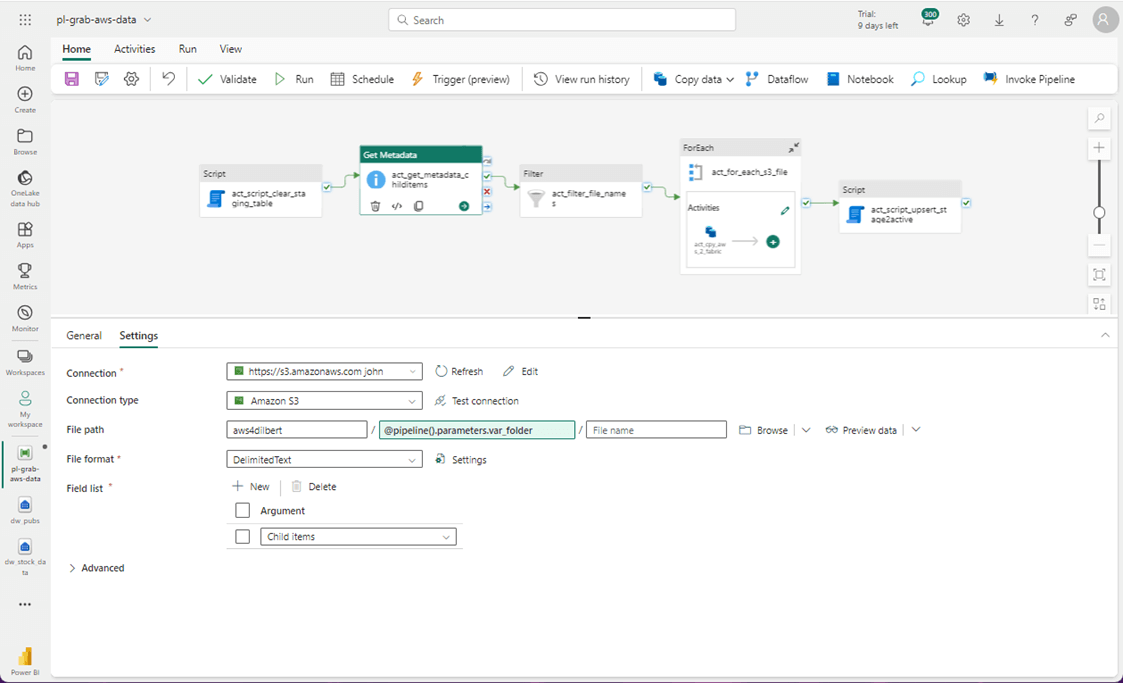
The filter activity is adept at narrowing the resulting file list. We need to pass the output of the metadata activity as well as define a condition. In our proof of concept, we are interested in the Microsoft stock symbol (MSFT) as this time. If you are not familiar with the ADF expression language, you should look take a look at the online documentation.
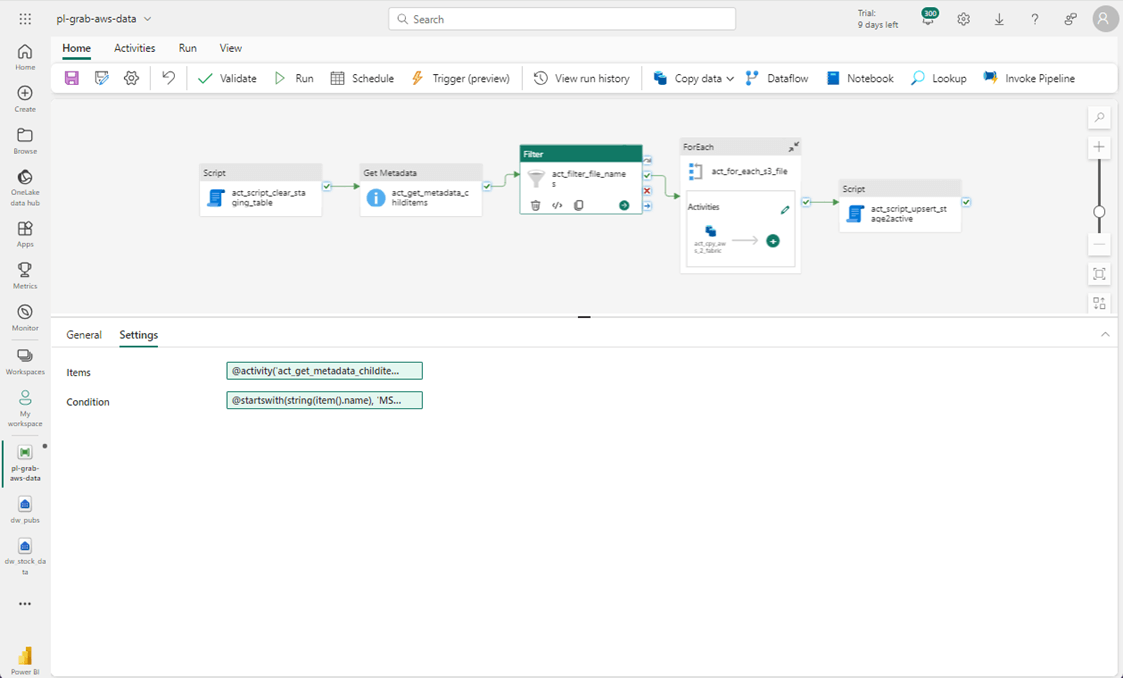
The for-loop activity needs to consume the output of the filter activity.
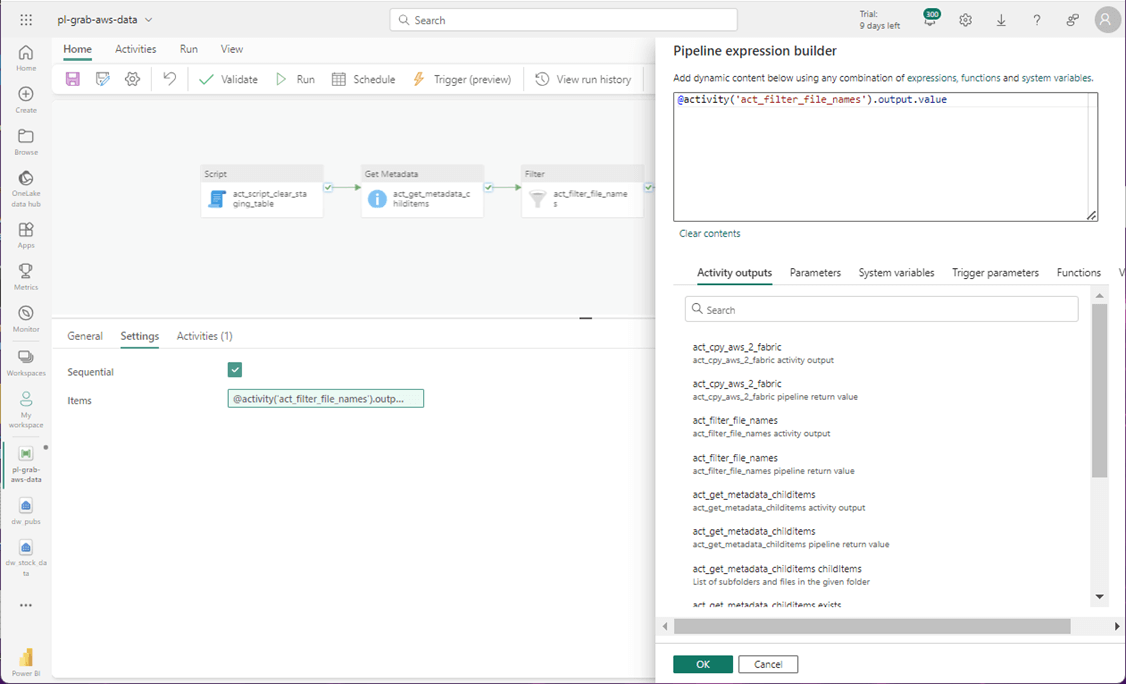
The copy activity is straightforward. The folder name is a pipeline variable, and the file name is the filtered file listing. See the documentation for more information on the item() object. Essentially, the for-loop exposes the JSON document element as an item() object. There are many settings for the Delimited Text file format. The default values seemed to work fine for me.
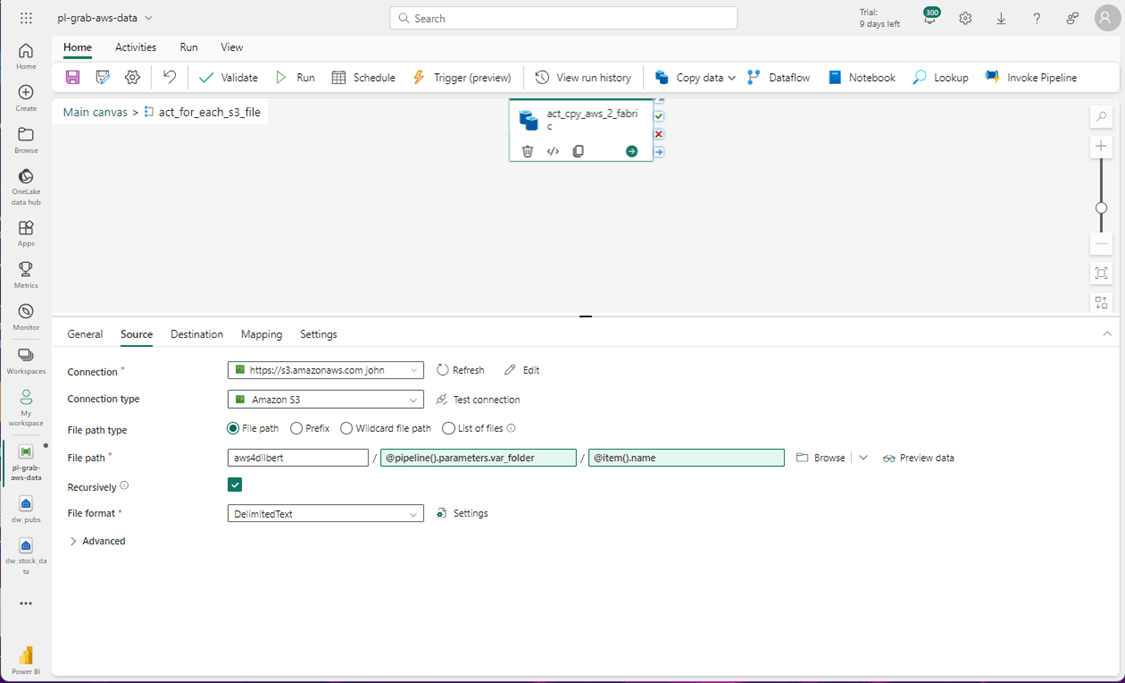
The destination of the copy activity is the staging table.
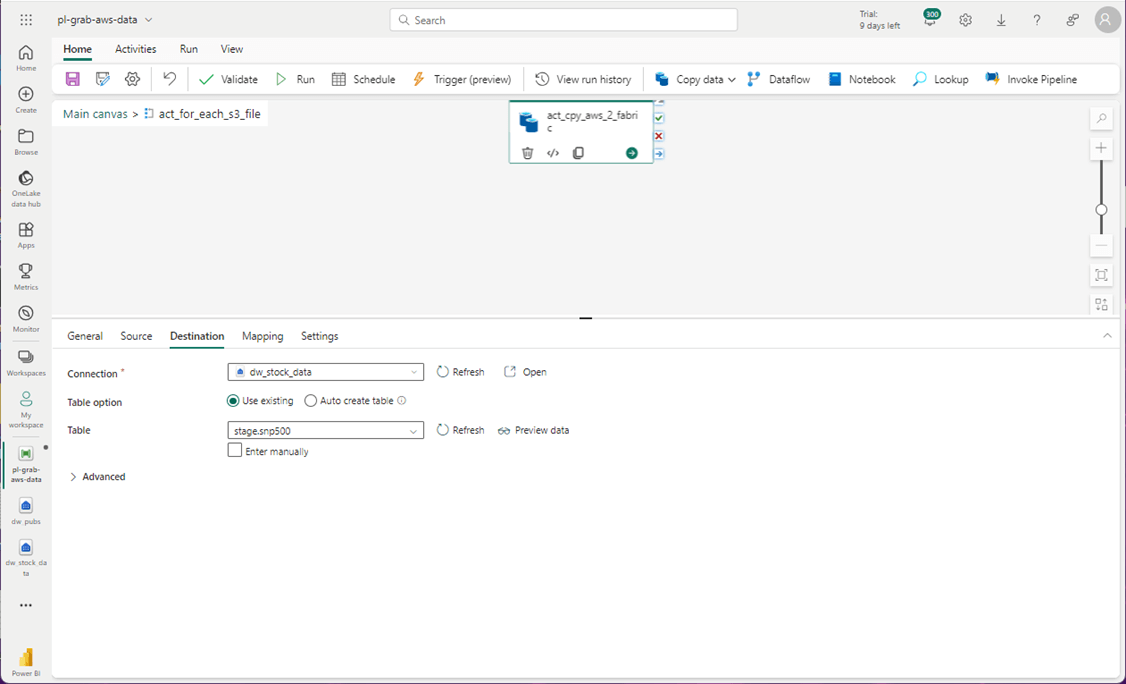
The source and target columns might not be an exact match. Therefore, use the mapping section of the copy pipeline to define the translation. Use the import schemas button to start the exercise.
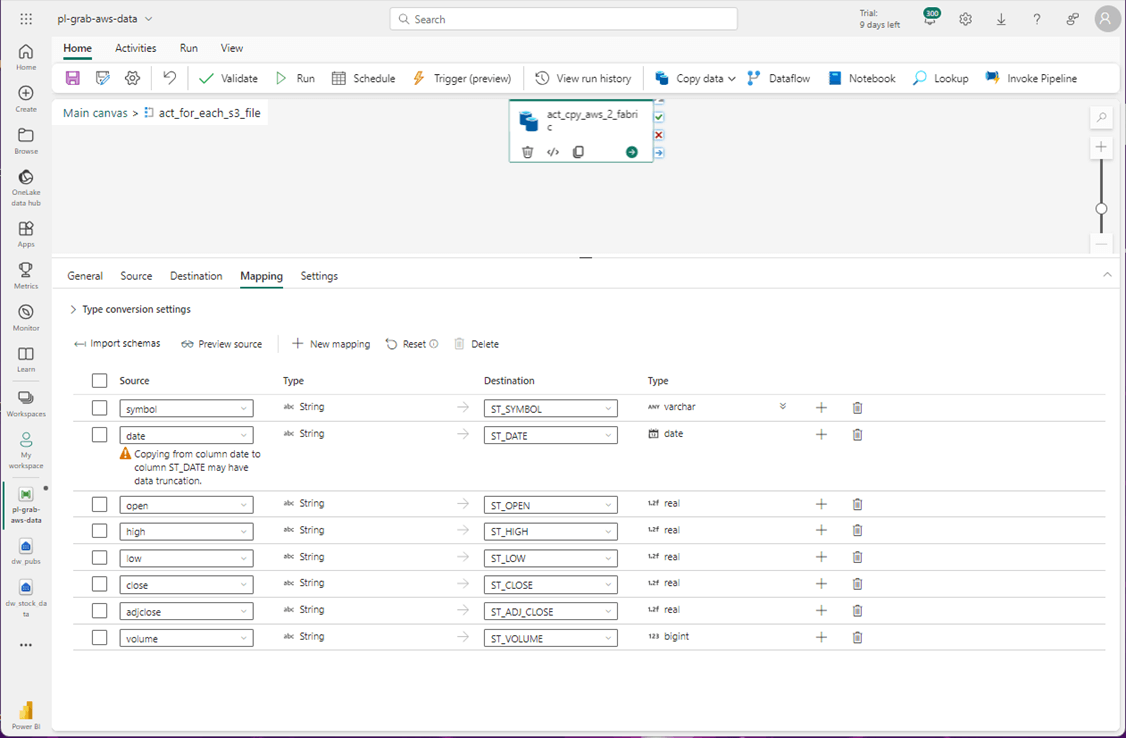
The last step is to merge the data in the staging table with the existing active table.
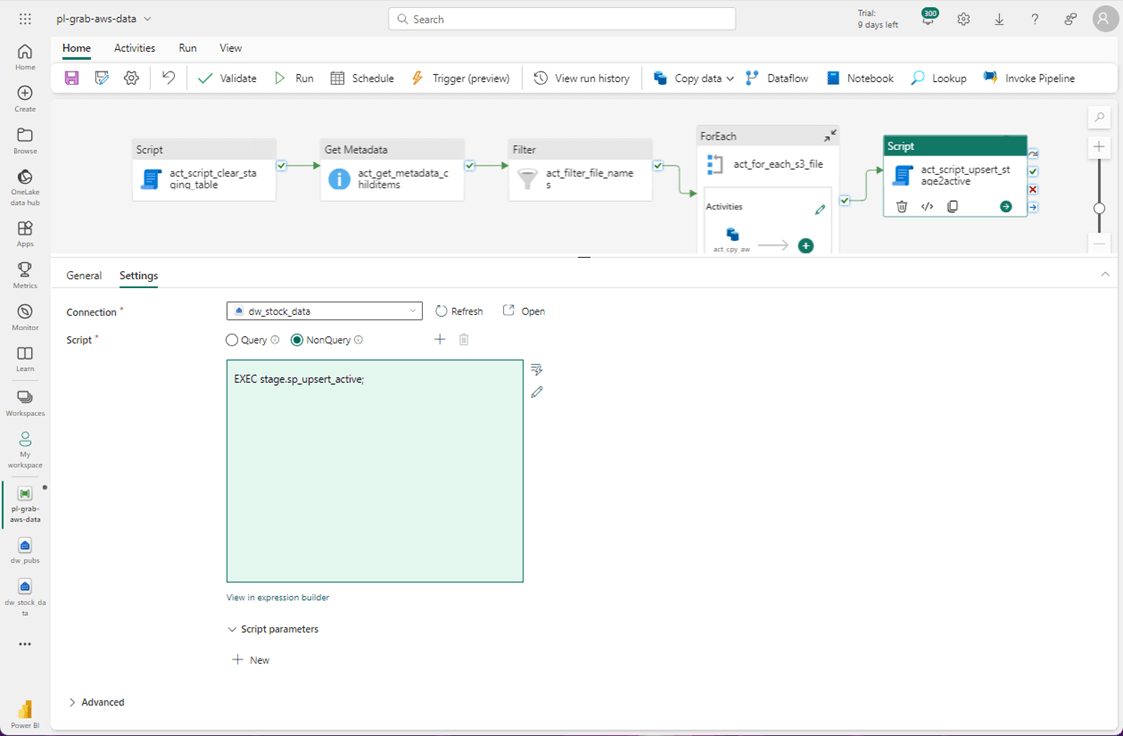
Now that we have completed our design, we can test the data pipeline in the next section.
Testing
For some reason, we have different storage containers/buckets containing our stock data. The AWS S3 bucket contains data for the 2013 and 2014 years. Make sure you set the pipeline parameter to the correct value before executing the pipeline.
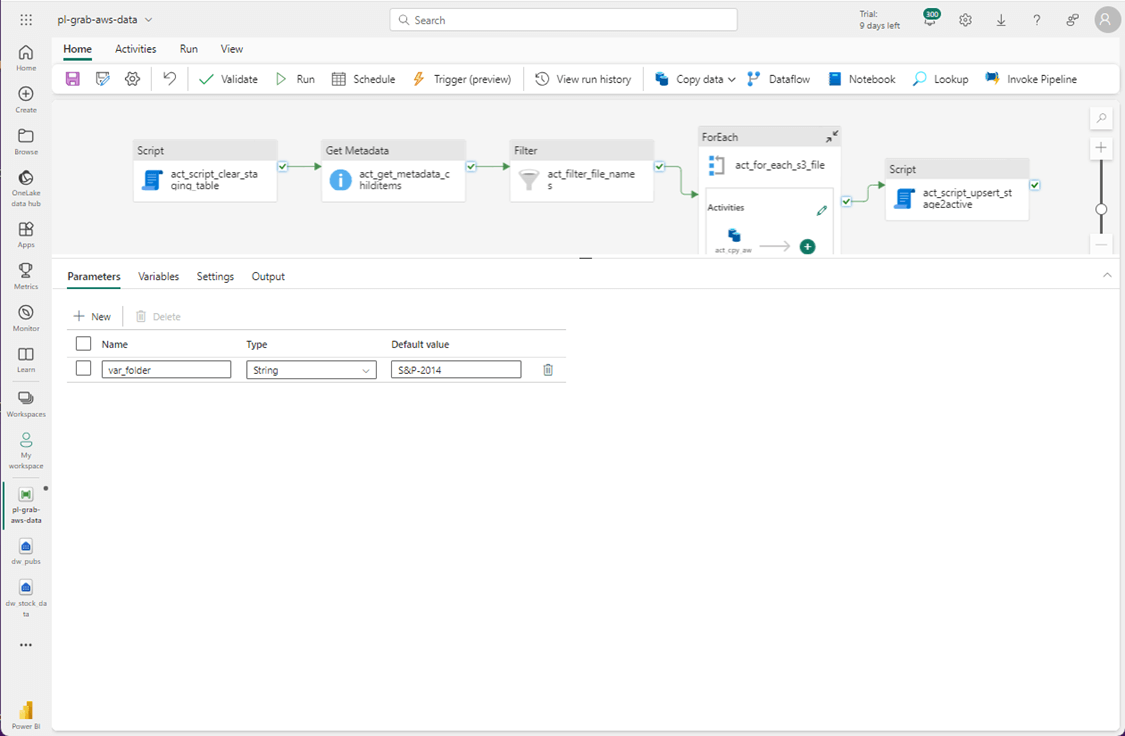
Click the debug option to execute the pipeline now. In the future, a parent pipeline would make five execute pipeline calls. Two to both AWS and GCP. The most recent data files are stored in Azure. The image below shows the metadata activity returns a list of childItems.
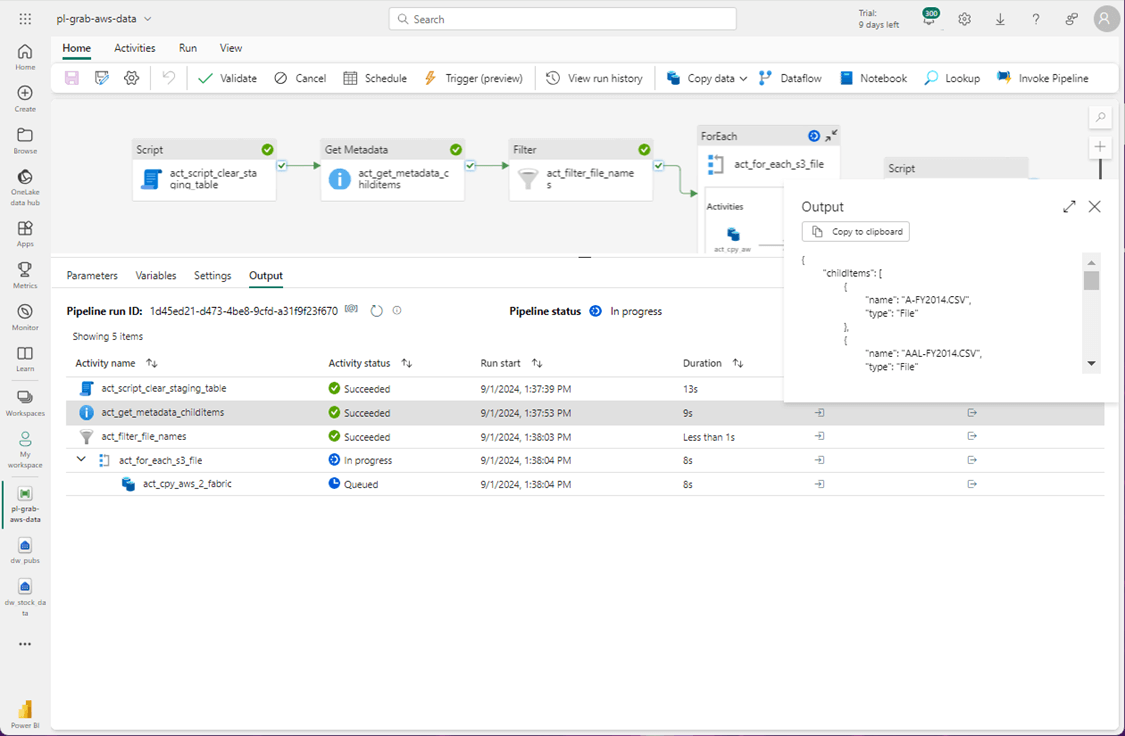
The output from the filter activity is one file named MSFT-FY2014.CSV. Our original list of 506 files has been reduced to 1 file.
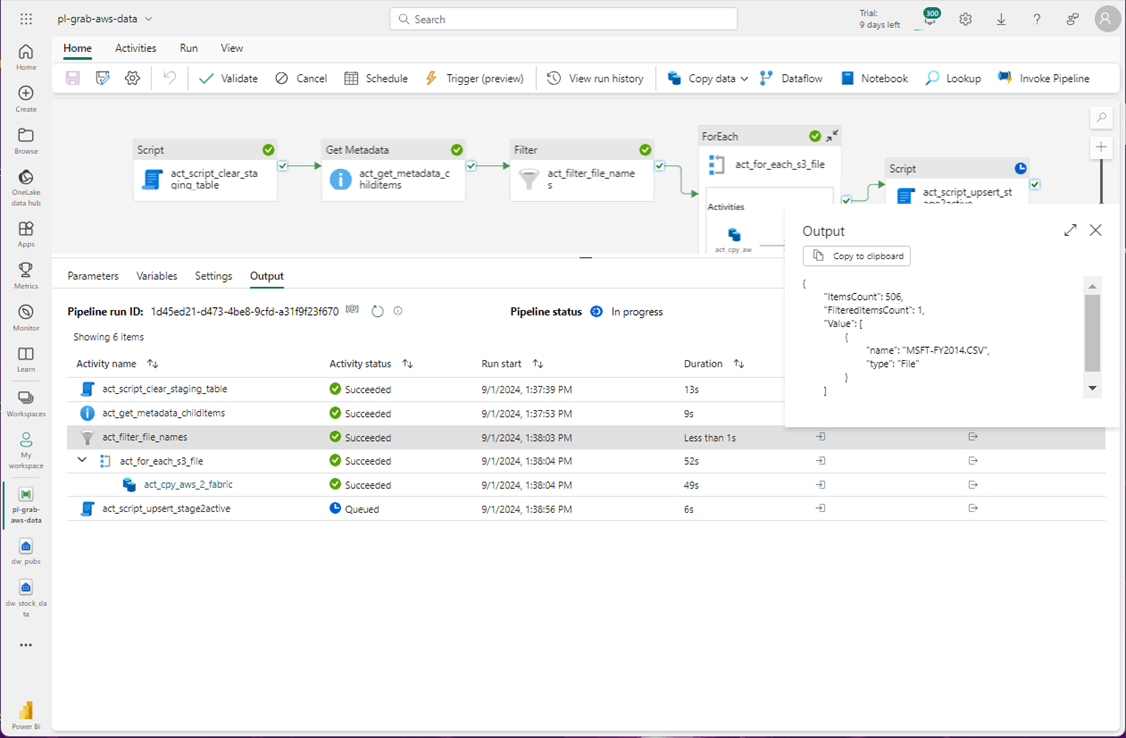
The output of the copy activity shows 256 records were copied from the CSV file in AWS to the staging table in Fabric.
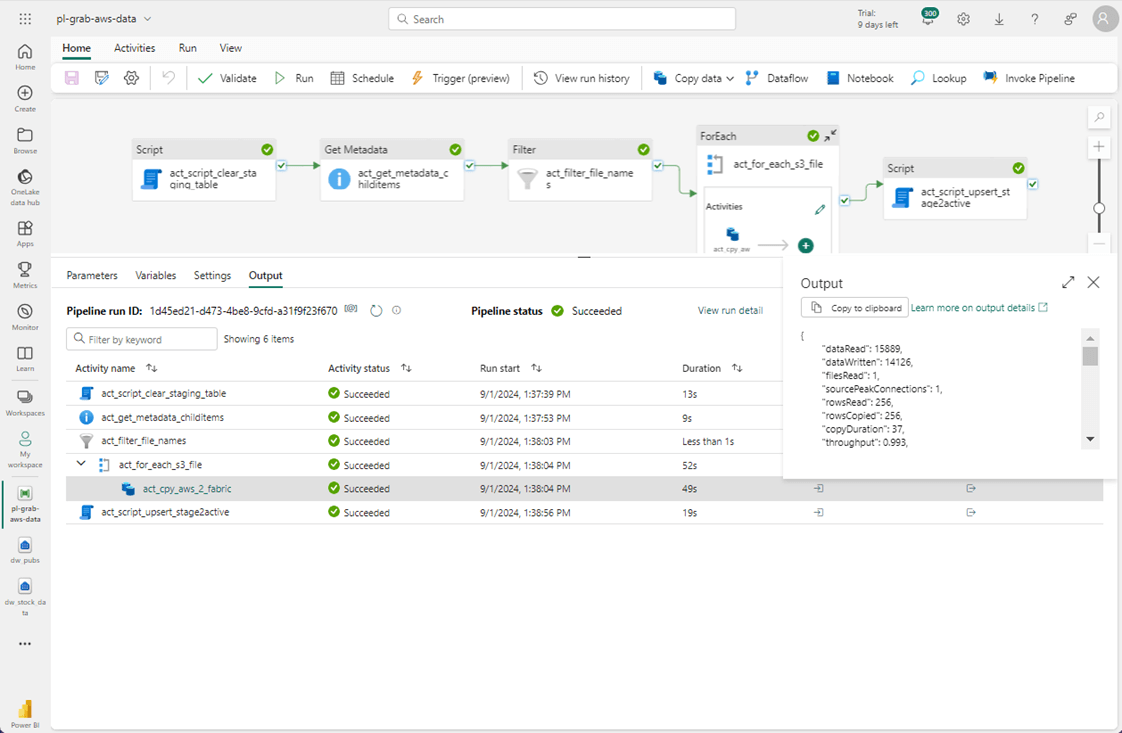
The most important part of the above screen shot is the total execution time. It took 77 seconds to complete the execution of the program. Please re-run the pipeline in debug mode using the 2013 directory as input.
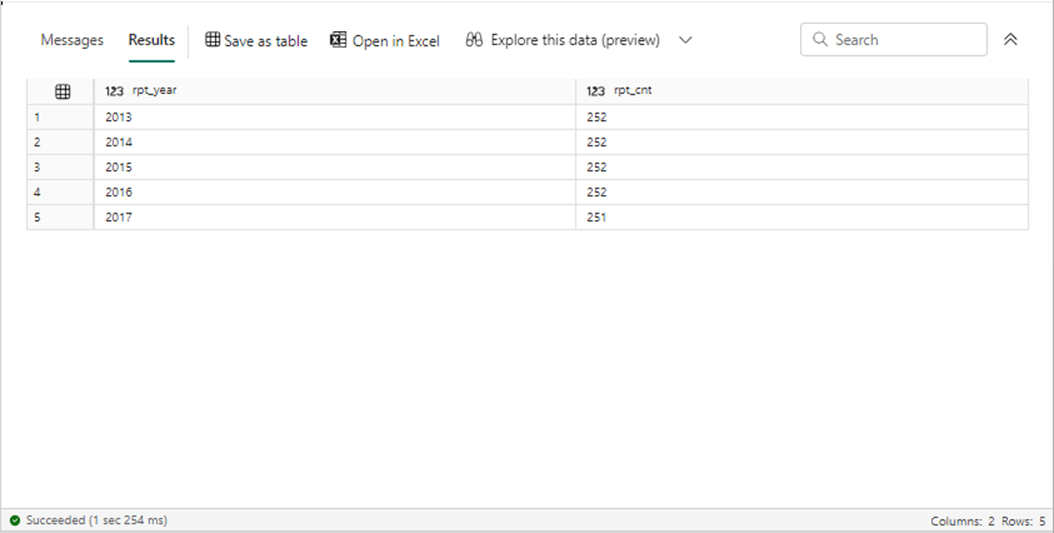
Most data engineering testing starts with comparing record counts between the source and destination. We can run the following T-SQL to look at the counts in the active stock data table.
-- -- Testing -- select year(ST_DATE) as rpt_year, count(*) as rpt_cnt from active.snp500 group by year(ST_DATE) order by year(ST_DATE)
The output from executing the above T-SQL statement is shown below.
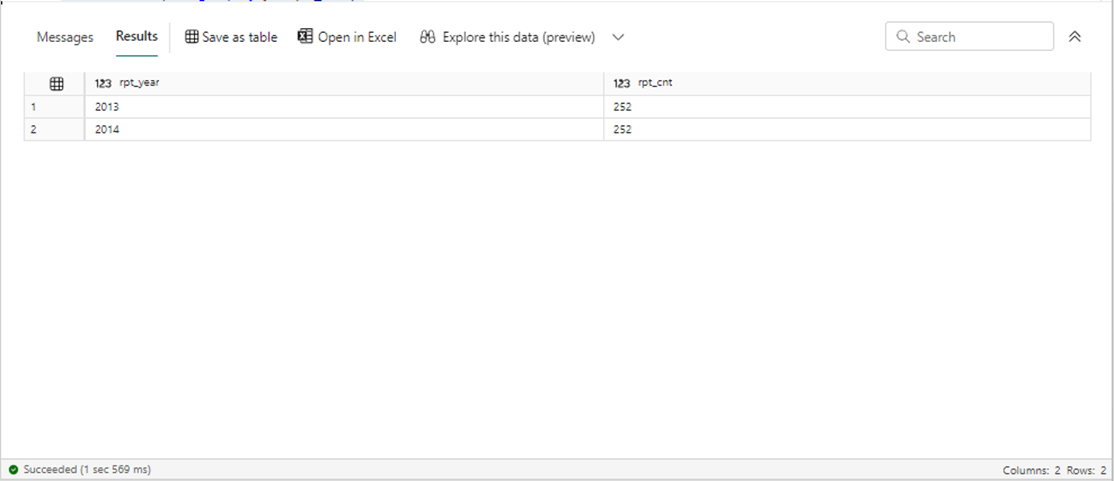
The record counts from the source file and target table are off by records that have zero values for trading volumes. These records were captured by the REST API call and represent dividends that were paid. Since we are not interested in this data, the records are filtered out by the view in the Fabric Warehouse. To recap, we created a design pattern that ingests data from a cloud vendors storage system into our Fabric Warehouse. The next two cloud vendors only require changes to add new connections. Use the save as button to clone the data pipeline for each use case.
Azure Data Pipeline
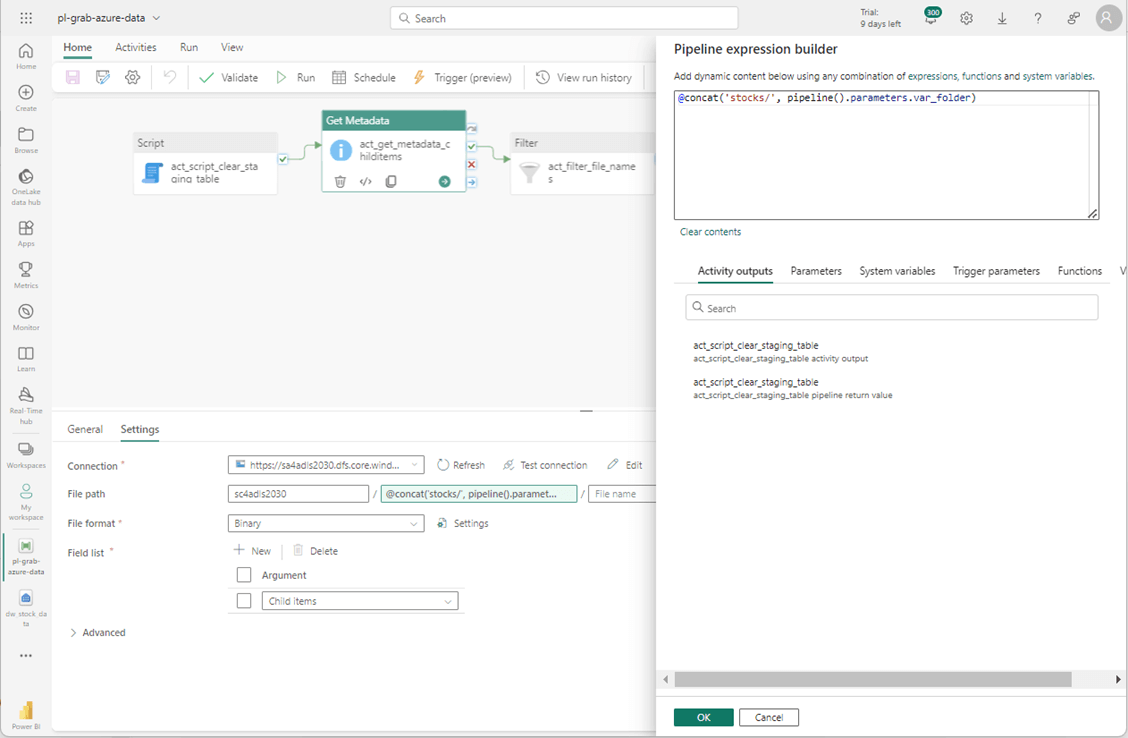
The end point for the Azure Data Lake Storage needs to be updated with a new connection. The account is named sa4adls2030 and the container is called sc4adls2030. The actual folders are located within a parent folder named stocks. The image below shows the metadata activity has been updated with these changes.
The same changes need to be made to the source section of the copy activity. See below image for details.
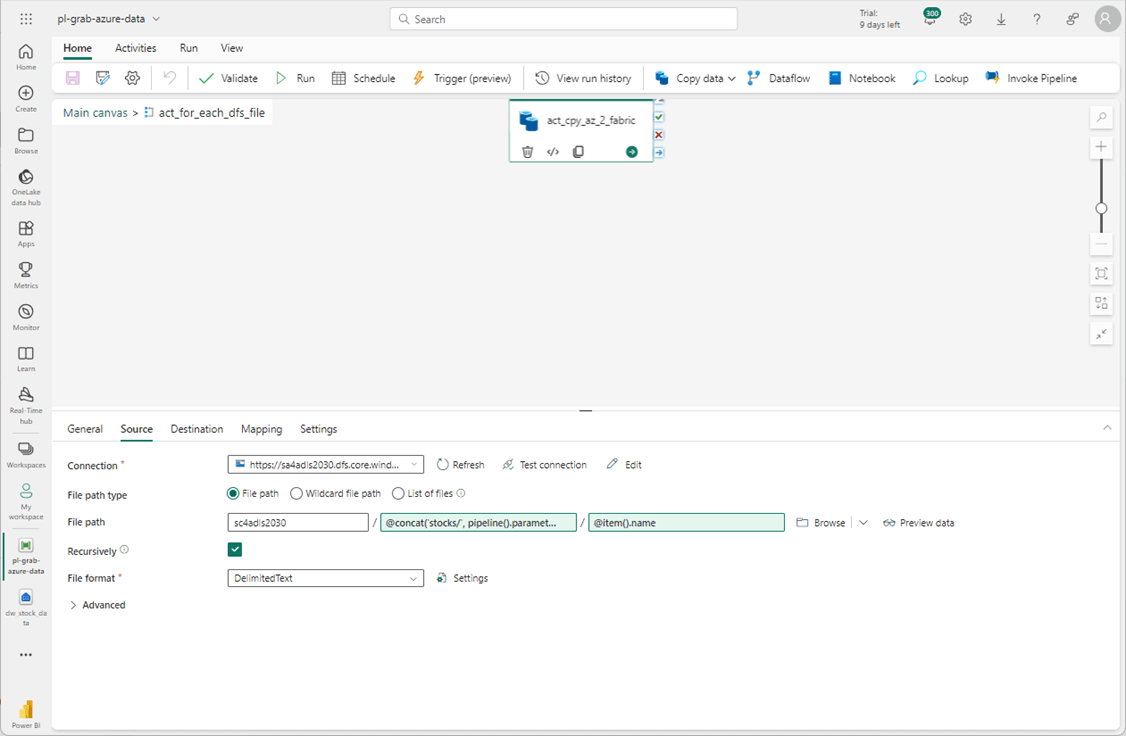
There is only one year of data files in Azure Storage.
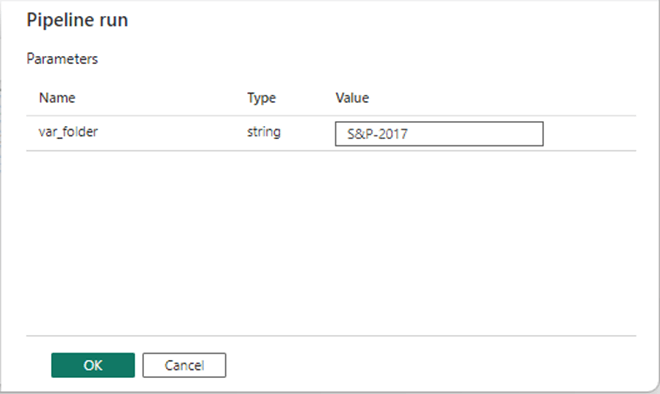
Since both the metadata and copy activities have been updated with the new connection information, we can execute the pipeline right now. The image below shows 255 rows have been copied to the staging table.
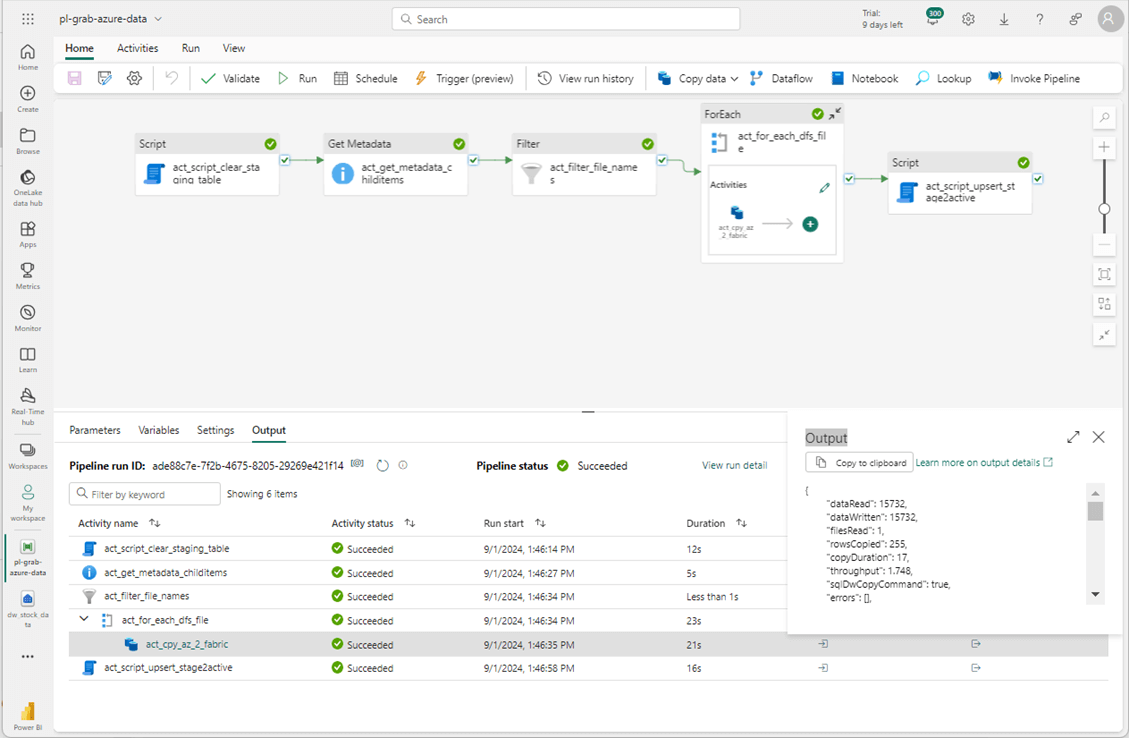
The most important part of the above screenshot is the total execution time. It took 44 seconds to complete the execution of the program. Run the previous testing T-SQL to get a count of records by year. We can see that four records had zero dividends and did not get stored in the snp500 table in the active schema.
The last data pipeline will be written for GCP buckets.
GCP Data Pipeline
The end point for GCP Storage needs to be updated with a new connection. The bucket is called poc-bucket-2024 and contains two folders for stock data from 2015 and 2016. Please update the metadata and copy activities with the new connection information. The screen below shows 256 records being ingested from the 2015 file.
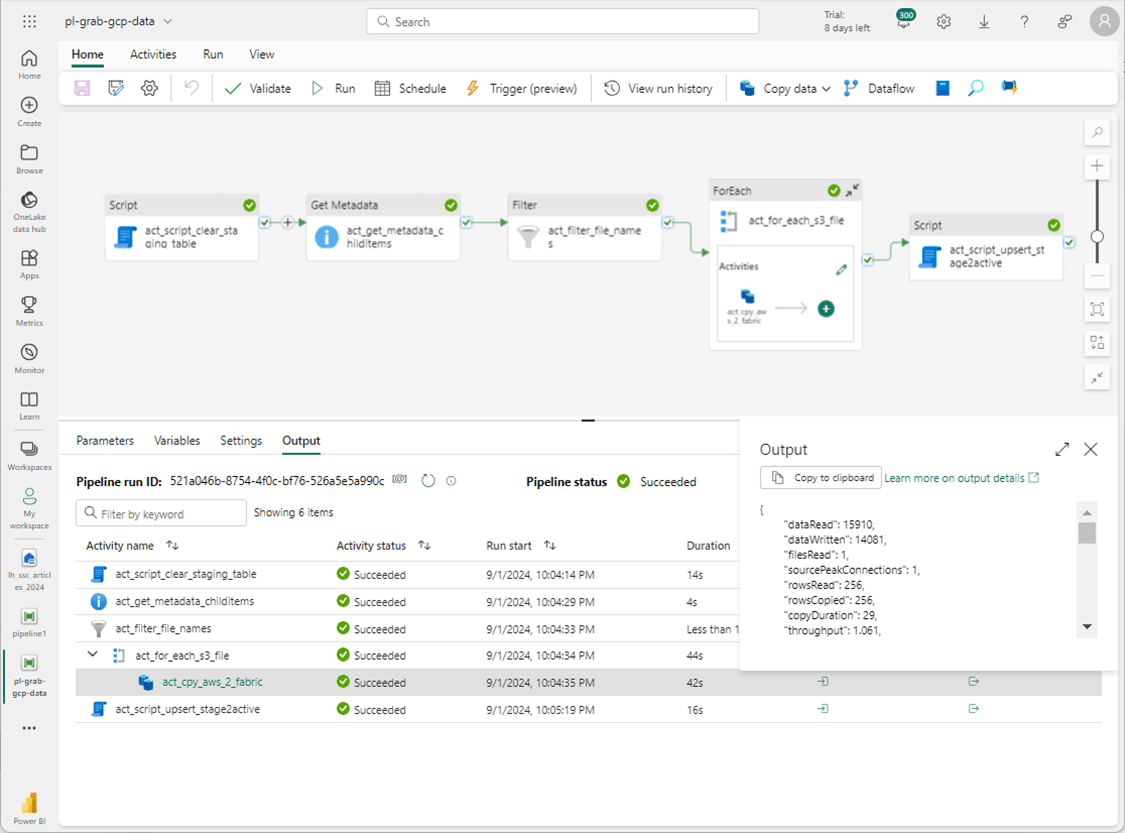
The most important part of the above screenshot is the total execution time. It took 44seconds to complete the execution of the program. Please re-run the data pipeline for the 2016 fiscal year. We can see there are 506 CSV files in the directory but only one file for Microsoft (MSFT) stock is selected.
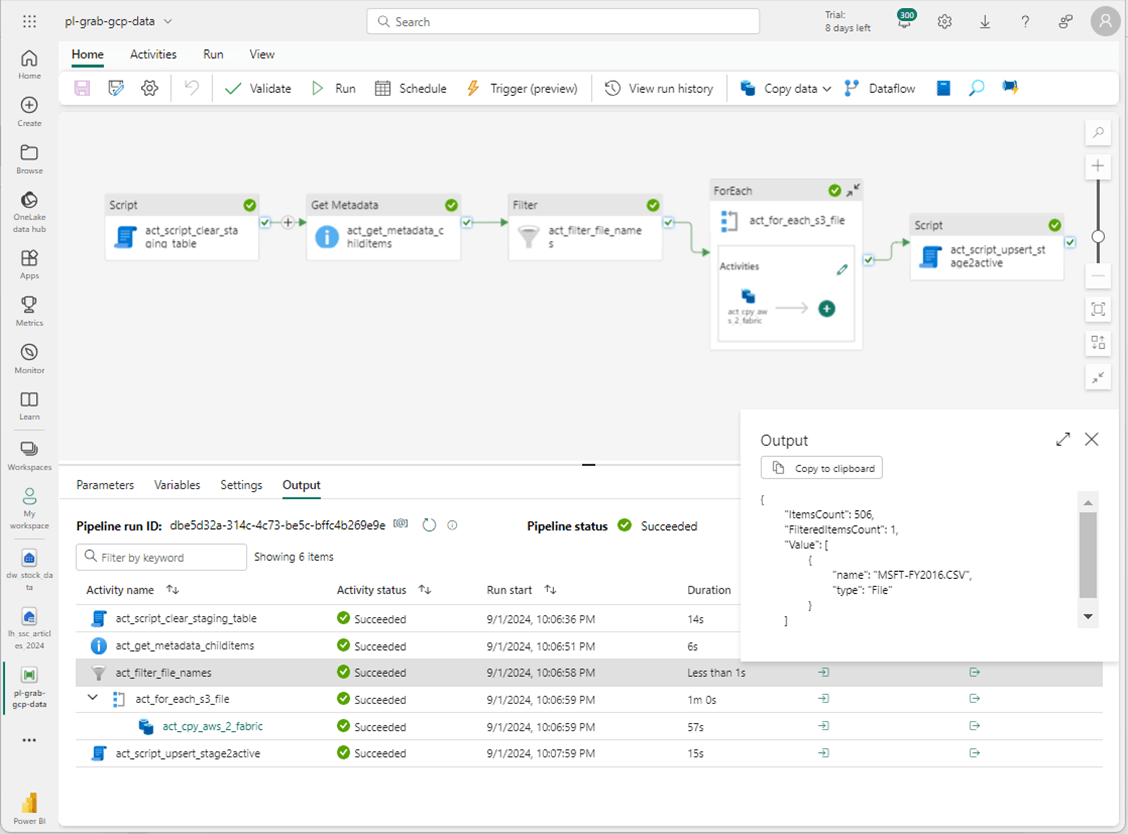
The software development life cycle is not complete without a positive test case. There is a cut and paste error that I left in the screenshots. That is why we do testing. The name of the for-loop and copy activities still refer to AWS instead of GCP. I leave this change for you, the reader, to make. The total execution time of the data pipeline is 83 seconds.
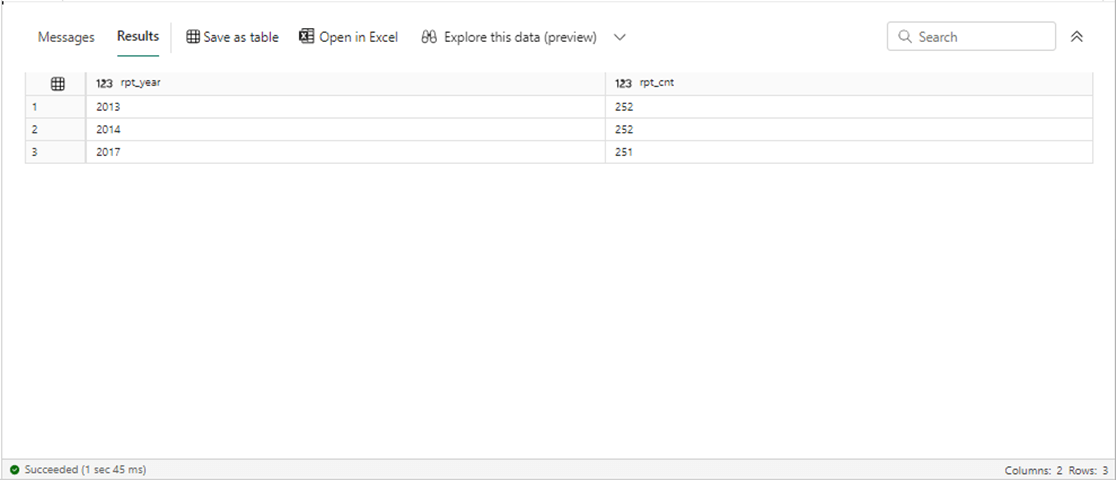
If we run the previous T-SQL statement, we can see all the records by year. Every year except for 2017 has 252 trading days. There is one less day in 2017.
Copy Into Statement
The issue with the previous data pipelines is clearing the staging table, reading the CSV file, writing to the staging table, and insert/updating the active table takes between 44 and 83 seconds. If we estimate the total time for all files, we are looking at 6 to 11 hours depending upon the cloud source. Is there a way to load data faster than this?
The COPY INTO statement assumes the data is stored in either a data lake or Blob storage container. Access to the data can be achieved in many ways. The example below uses a storage account key.
--
-- Load table - all years - fails due to bug
--
-- Clear table
TRUNCATE TABLE [active].[snp500]
GO
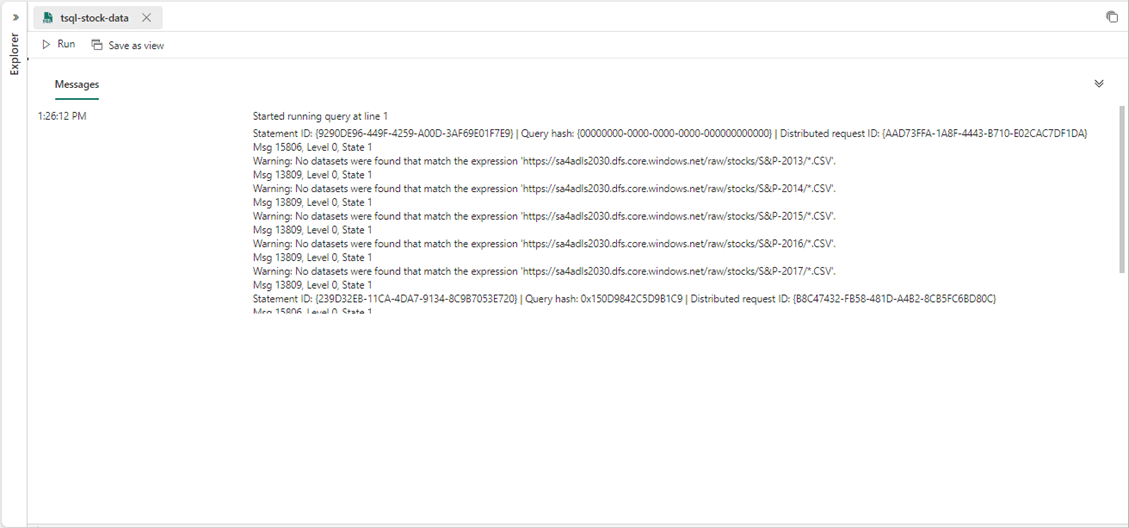
COPY INTO [active].[snp500]
FROM
'https://sa4adls2030.dfs.core.windows.net/raw/stocks/S&P-2013/*.CSV',
'https://sa4adls2030.dfs.core.windows.net/raw/stocks/S&P-2014/*.CSV',
'https://sa4adls2030.dfs.core.windows.net/raw/stocks/S&P-2015/*.CSV',
'https://sa4adls2030.dfs.core.windows.net/raw/stocks/S&P-2016/*.CSV',
'https://sa4adls2030.dfs.core.windows.net/raw/stocks/S&P-2017/*.CSV'
WITH
(
FILE_TYPE = 'CSV',
CREDENTIAL=(IDENTITY= 'Storage Account Key', SECRET='<your storage account key>'),
FIELDQUOTE = '"',
FIELDTERMINATOR=',',
ROWTERMINATOR='0x0A',
ENCODING = 'UTF8',
FIRSTROW = 2
)
GO
There is a known bug for paths that contain special characters. The output below shows the warehouse engine does not find any files even though files do indeed exist.
If we code up the statement to use a Shared Access Signature, the same code works.
--
-- Load table - all years - works file
--
-- Clear table
TRUNCATE TABLE [active].[snp500]
GO
COPY INTO [active].[snp500]
FROM
'https://sa4adls2030.dfs.core.windows.net/raw/stocks/S&P-2013/*.CSV',
'https://sa4adls2030.dfs.core.windows.net/raw/stocks/S&P-2014/*.CSV',
'https://sa4adls2030.dfs.core.windows.net/raw/stocks/S&P-2015/*.CSV',
'https://sa4adls2030.dfs.core.windows.net/raw/stocks/S&P-2016/*.CSV',
'https://sa4adls2030.dfs.core.windows.net/raw/stocks/S&P-2017/*.CSV'
WITH
(
FILE_TYPE = 'CSV',
CREDENTIAL=(IDENTITY= 'Shared Access Signature', SECRET=’<your shared access signature>'),
FIELDQUOTE = '"',
FIELDTERMINATOR=',',
ROWTERMINATOR='0x0A',
ENCODING = 'UTF8',
FIRSTROW = 2
)
GO
The execution time of 12 seconds seems unrealistic! The engine found over 2,500 files in the five directories. A total of 635,817 records were loaded into the active table.
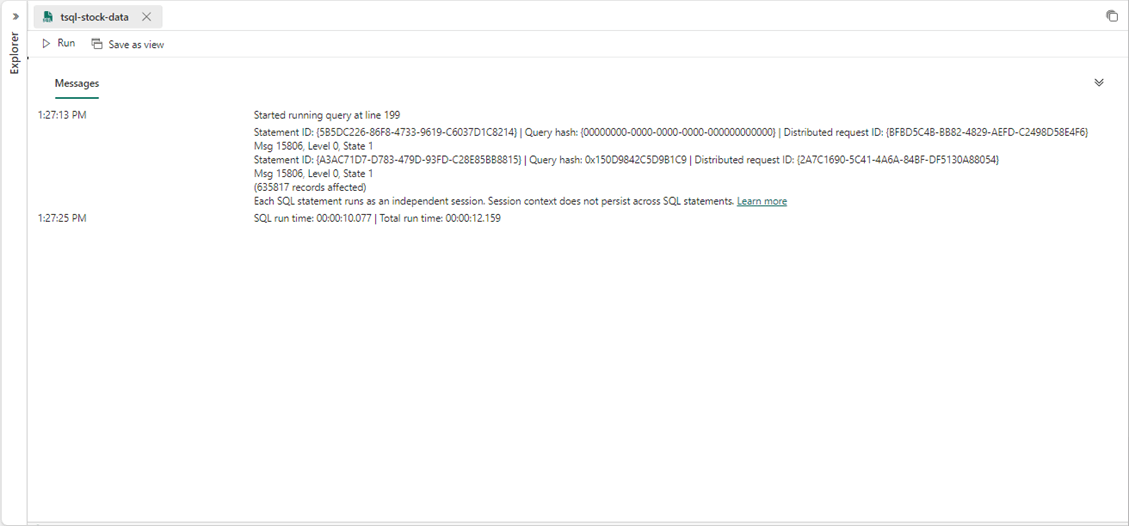
Let us look at the record counts by year. It is always important to test our results. We can see that one of the files has a data integrity issue. A single record from 2012 has been loaded to the table. Because we are working with stock data from 2013 to 2017, the acceptable range of dates is between 2013-01-01 and 2017-12-31. This one record has a date that is out of range. Our data analyst should research and fix the data issue.
In a nutshell, the COPY INTO statement wins hands down for the overall speed to load a data warehouse.
Size Matters
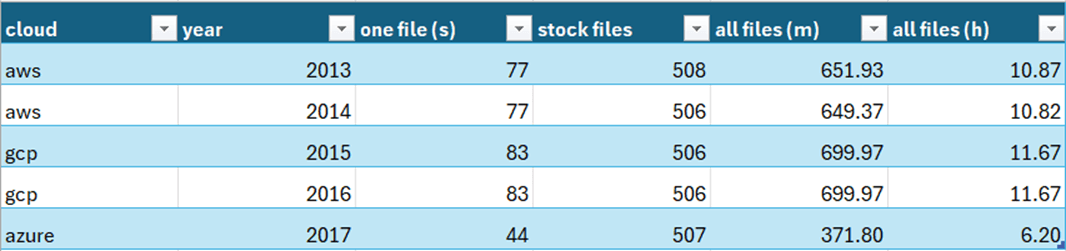
My educated guess is that the copy activity in Azure Data Factory uses REST API calls to retrieve the files from various cloud vendors. This adds latency to each file that needs to be processed. Additionally, a small data load of a few hundred records into a Delta table has the same overhead as loading hundreds of thousands of records. Let’s put my theory to the test by combining the 500 plus stock data files into one file per year.
We are going to use a MS DOS batch file to combine the files. Please see the code below. The next step is to remove each of the duplicate headers. I used notepad++ feature to sort the header lines to the bottom while keeping one at the top. Removing the bottom lines eliminates the duplicate header lines.
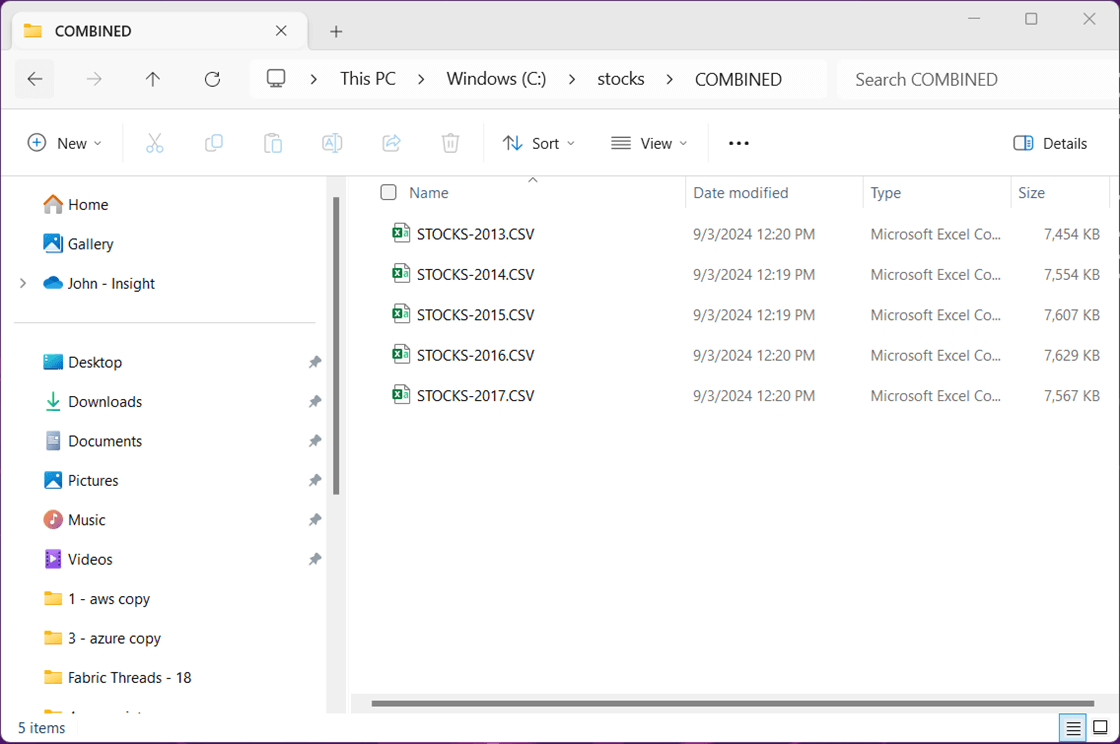
REM REM Combine all stock data for a given year REM COPY /b C:\STOCKS\S&P-2013\*.CSV C:\STOCKS\COMBINED\STOCKS-2013.CSV COPY /b C:\STOCKS\S&P-2014\*.CSV C:\STOCKS\COMBINED\STOCKS-2014.CSV COPY /b C:\STOCKS\S&P-2015\*.CSV C:\STOCKS\COMBINED\STOCKS-2015.CSV COPY /b C:\STOCKS\S&P-2016\*.CSV C:\STOCKS\COMBINED\STOCKS-2016.CSV COPY /b C:\STOCKS\S&P-2017\*.CSV C:\STOCKS\COMBINED\STOCKS-2017.CSV
The image shows the resulting five files in a sub-directory named COMBINED.
We are going to re-run the test with the cloud service that had the longest execution time per one file. Please upload the new folder into the GCP bucket.
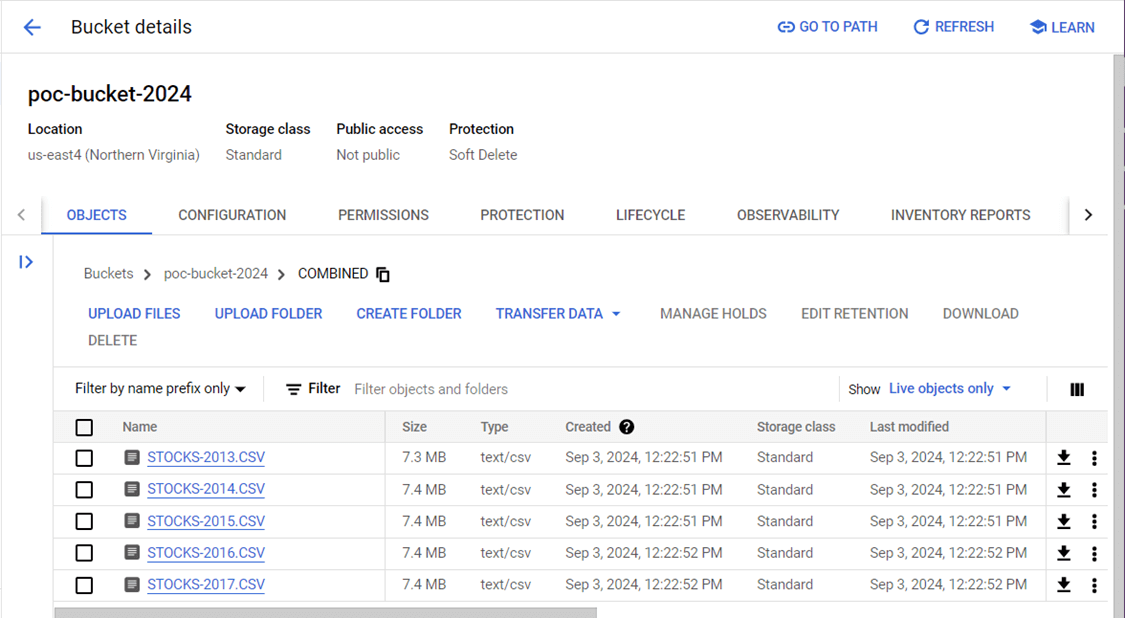
The image below shows the execution time for the updated pipeline. All we had to do was change the source directory and the filter for the file that starts with the word STOCK.
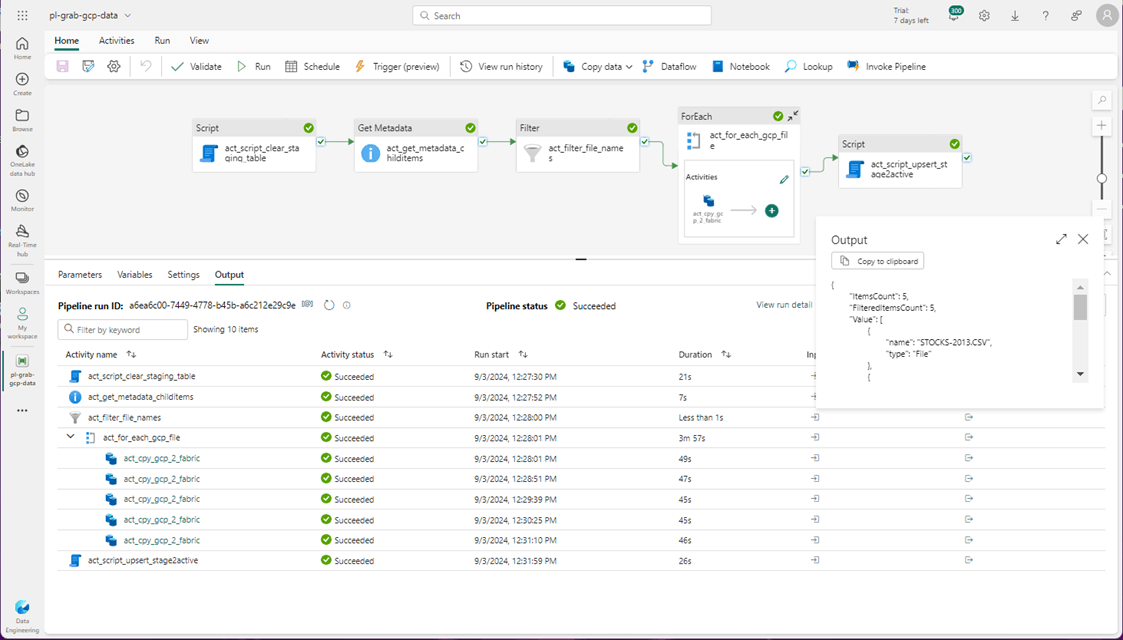
The overall execution time 291 seconds which is under 5 minutes. This is not as good as the 12 seconds for the COPY INTO statement. However, it is not as bad as the original estimated time 51 hours. The key lesson from this exercise is to use a few large files instead of many small files when writing Fabric Data Pipelines.
Summary
Microsoft Fabric has a shiny new data warehouse that is built upon the Delta Lake format. The data pipelines in Microsoft Fabric allow the designer to read files from all three major cloud vendors. These files can be placed into a staging table and merged into the final active table. Currently, the data warehouse does not support the MERGE statement. However, we can write our own stored procedure to handle the cases when we need to insert and update rows. The typical load time for a file depends on cloud vendor. Timings ranged from 44 to 83 seconds. If we estimate the total load time using an ADF pipeline for all S&P 500 files for a given year, we are looking at hours to load the warehouse.
Don’t fret! The COPY INTO statement can save you hours when loading data. The statement currently supports Azure Data Lake Storage and Azure Blob Storage as source locations. Today, we tried using both a storage account key and a shared access signature. The first access method has a bug. Any paths that contain special characters result in no files being found. The second access method works as one would expect. The statement ran in 12 seconds; found over 2,500 files; and loaded 635,817 records. For now, the COPY INTO statement wins the algorithm contest.
To recap, the data warehouse in Fabric allows the big data engineer to design a model without worrying about how the data is stored internally. Some operations perform better than others. Today, we tried to work with many small files using data pipelines as our extract, load, and translate tool. It did not work out so well. A second round of processing was performed using five files, one per each year. The execution time was around 5 minutes, which is acceptable. The moral of the story is to use large data files when possible.