

My first exposure to Terraform was when I started to work with data in the AWS cloud. As a Cloud Data Engineer I was expected to cover a wide range of infrastructure provisioning so I found myself having to learn rather more about cloud infrastructure than I had expected.
Understanding the problem
We want repeatability when deploying infrastructure across environments. A web based Cloud/SaaS Console remains useful for visualising your infrastructure but for actual maintenance we must have infrastructure-as-code (IAC). This is just as we have SQL scripts to develop and maintain our databases.
When I started using AWS, it had three methods of spinning up infrastructure
- From the web console
- Using the
awscommand line tool (CLI) - Writing Cloud Formation templates.
Nowadays we also have the AWS CDK that allows us to maintain infrastructure in a programming language in which we might already have skills.
- Python
- Java
- JavaScript/TypeScript
- C#
- GO
The AWS CLI has its uses though for IAC I would keep it as a lump hammer for when all else has failed. It isn't really intended to script up and maintain a large infrastructure estate.
Cloud Formation was fine for basic activities but as our needs became more sophisticated it became a bit of a nightmare. We also had to consider other SaaS products such a GitHub and working with other cloud providers. Maintaining several products is especially hard when each product and cloud has its own approach to IAC.
Terraform removed a lot of the stress by providing a common approach across all products. Take a look at the Hashicorp Providers page shows the breadth of providers available.
What is Terraform?
Terraform is a command line tool that allows you define your infrastructure in the Hashicorp Configuration Language, HCL. HCL acts as an abstraction layer for the cloud APIs and libraries. Just like SQL this is declarative language so you tell it what you want the end result to be and it works out how it is going to achieve it.
HCL has its own in-built functions for manipulating the contents of its data types. Examples include the following.
- Concatenating lists into a single list
- Joining lists into strings
- Populating placemarkers in a template file with appropriate values
- Reading file formats such as YAML and JSON into Terraform data structures
- Extracting attributes from data structures and building other structures
Look at the last point. HCL does not edit data, it takes an immutable input and provides an immutable output. HCL is a declarative, functional programming language.
What are the main components of Terraform
There are 3 types of component in Terraform
- Plug-in
- Provider (which is a type of Plugin). It will be written in GO and talks directly to Terraform over RPC.
- Module
A unit of code you write in Terraform is called a module and your modules can be made up of other modules. An example would be a module that defines the infrastructure for pulling data (extraction) from outside your organisation. Sub-modules could include the following infrastructure.
- Retrieving data using an API
- Taking a docker image, running it as a docker container to extract data from an external SQL database
- Pulling data from an sFTP site
A Terraform provider is a wrapper for an API and within that API its endpoints are represented by the following: -
| Terraform Artefact | Description |
|---|---|
| Resource | Creates or updates infrastructure. In SQL terms this is akin to CREATE or ALTER |
| Data | There are two things that a data object can do
Think of it as being a DESCRIBE or SHOW query or SELECT against INFORMATION_SCHEMA objects. |
Terraform Resource and Data objects are also modules however when we talk about Terraform modules we tend to mean something we write as represented by the graphic below.
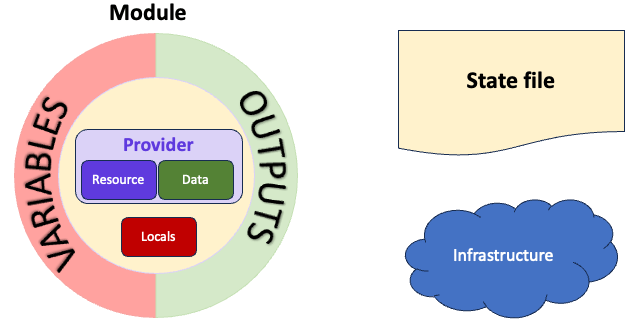 General view of Terraform components
General view of Terraform componentsLet's look at these in a bit more details
Providers
Let us suppose that I want to use the Github provider. I would set up a requirements.tf file as follows.
terraform {
required_version = ">= 1.9.0"
required_providers {
github = {
source = "integrations/github"
version = ">= 6.2"
}
}
}
# Config settings for the Github provider
provider "github" {
owner = "djp-corp"
}I am telling Terraform that I wish to use a minimum of version 1.9.0 and the Github provider (plugin) must be at least version 6.2. I have configured my GitHub provider so that the owner is my company, the DJP Corporation.
Provider authentication
For authentication Terraform does read environment variables and for Github the default is to look for an environment variable called GITHUB_TOKEN. This will contain a Github PAT (Personal Access Token) that I set up in Github and configure to expire every 30 days.
For AWS I use the aws sso (AWS Single Sign-On) command line and a simple shell script that assumes the relevant AWS role and makes the temporary AWS credentials available for my session as environment variables.
One of the challenges with Terraform authentication is to have just the amount of permissions you need to deploy the infrastructure you want. The way my company approaches this is for the data engineers in the development environment to have close to admin privileges. Deployment to higher environments can only take place using the CICD pipeline.
Variables
Again, think of a module as being a function or stored procedure. It must have its input parameters defined and variables are how we define those input parameters. The convention (but not an enforced rule) is to store those variables in a file called variables.tf.
Here are two examples of variable declaration.
variable "api_concurrency" {
description = "The maximum number of concurrent api calls that are allowed to run at one time."
type = number
default = 16
}
variable "log_level" {
description = "Valid values are NONE, ERROR, WARN, INFO, DEBUG"
type = string
validation {
condition = contains(["NONE", "ERROR", "WARN", "INFO", "DEBUG"], var.log_level)
error_message = "log levels must be one of NONE, ERROR, WARN, INFO, DEBUG"
}
}So variables are declared using a variable {} block but they are referenced in Terraform code using the var prefix, var.log_level.
The minimum declaration would be the variable type however my company standard is also to provide a description that is meaningful to the maintainer.
The 2nd declaration illustrates that you can choose to validate the input for your variables too.
Your variables type can be
- Primitives which are number, string, bool
- Collection types such as list, set or map
- Structural type such as object.
These can be as complex or as simple as you need. For example if we wanted a variable that held a list of columns we might have something similar to the code below.
variable "column_list" {
type = list(object({
name = string
alias = optional(string, null)
type = string
required = optional(bool, true)
unique = optional(bool, false)
exclude_column = optional(bool, false)
}))
}Outputs
The convention is to name the file outputs.tf.
Just as variables represent the contract for the inputs to a module, outputs describe what the module will return. Using the example of our extraction module we may need also have an ingestion module that needs to know the values of some of the extraction outputs.
An output can be a primitive type such as a string, number, boolean etc or the complex output from a module.
output "rds_instance" {
value = module.postgres_rds_instance
description = "The full set of exposed properties for the Postgres RDS instance created within the module"
}The minimum definition is the value, however a description meaningful to the users of the module is a sensible standard to adopt, particularly if you write modules that are to be shared as common components.
By the default Terraform will echo all outputs to the terminal. If you have some outputs that you don't want visible then an additional sensitive = true parameter will stop that happening.
Locals
The convention is to name the file locals.tf.
This is where we can use the HCL in-built functions to read data structures and write out other data structures. I'll illustrate this with an example
# This would normally be in the module variables.tf file.
variable "name" {
description = "The list of strings that will make up resource names"
type = list(string)
}
# This would be in the module locals.tf file
locals {
name = concat(var.name, ["api", "data"])
data_content = templatefile("${path.module}/templates/api-data-retrieval.json",
{
lambda_function_arn = module.api_data_lambda.aws_lambda_function_arn
lambda_name = join("_",local.name)
support_email_address = var.support_email_address
hostname = var.api_base_url
}
)
}
So we have our extraction module that calls our api_data module.
- var.name is passed into our api_data module from our extraction module and contains a list defining the name of our overall application, say ["external", "extract"]
- The concat function will join these lists together to product ["external", "extract", "api","data"]
templatefile is an inbuilt HCL function that allows us to read a file containing place markers and replace those placemarkers with the values we assign to those place markers. In this case we are submitting
- The output from the api_data_lambda module
- external_extract_api_data which we get by joining our local.name elements with an underscore character.
- Variables declared in the module passed in using the
varprefix.
The utility module
Almost all the modules I have seen are for spinning up infrastructure. At a minimum they comprise of the following
- At least one provider
- Variables
- At least one resource module
- Possibly a data module
- Optionally but usually outputs
- Optionally locals
In older versions of Terraform the capability to make infrastructure more data driven were limited. Today we might have a JSON or YAML file that describes the properties we wish to use to generate Github repositories. Our locals file extracts and builds the sets of data required to be able to generate infrastructure in a loop. This has allowed us to come up with modules that don't spin up infrastructure, they just carry out the data transformation necessary for to provide data for other modules to use.
Such a module will consist of the following
- Variables for input
- Locals to transform that input
- Output to expose the transformed input.
We simply call this utility module from whatever module needs it.
module "utility_transforms" {
source = "../utility_transforms"
name = var.name
a_parameter = var.an_input_variable
another_parameter. = var.another_parameter
}
module "our_resource_module" {
source = "github.com/some_reusable_module?ref=v1.0.0"
for_each module.utility_transforms.some_list_of_properties
# rest of module
}
Resources
The convention is for the entry point for a module to be called main.tf.
A resource is what creates/alters infrastructure. It has two arguments and in addition the items within the {} containing the parameters we wish to pass. The arguments are as follows
- The function name/API endpoint for the object we wish to create
- A label that we can use to refer to the resource outputs. Again, remember a resource is also a module.
Earlier my Provider example used Github so we can now create a GitHub repository. The code in our main.tf file would contain the following
resource "github_repository" "blog_content" {
name = "sql_server_central_content"
description = "Keeps graphics, example code and documents for SSC articles"
}
Only the name property is mandatory but where a resource provides a property to supply a description I strongly recommend you use it.
Once our GitHub repository has been created then we can create any other objects either in or related to that object. These could include
.gitignorefile- Standardised
.github\workflowfiles - Repository rules
- Tags
resource "github_repository_topics" "blog_tags" {
repository = github_repository.blog_content.name
topics = ["content", "graphics"]
}So why don't we just put name = "sql_server_central_content" in the code to create repository topics? As a declarative language Terraform the dependency between the github_repository resource and the github_respository_topic means that the repository will be created first. If you hard-code the name then Terraform won't know that there is a relationship and might try to create the topics before there is a repository in which to create them. This would fail.
For GitHub the resources use the name of the repository which we provide. For other Terraform providers such as AWS resources have an identifier known as an ARN (Amazon Resource Name) which isn't known until the object is created.
Data
As mentioned earlier, data modules are akin to SELECT statements. They have the same two arguments that a resource does but their parameters tend to be those items that, in database terms, would be indexed columns we would use in our WHERE clause.
The Terraform State file
So far I have not mentioned the most important Terraform component. That is the Terraform State file which is a big JSON file that keeps track of the infrastructure that your Terraform code has deployed.
As AWS users we keep our state files in an S3 bucket with versioning switched on so that we can retrieve previous versions of that file.
The relationship between your code, state file and infrastructure can be summed up in the table below.
Artefacts | Description |
|---|---|
| Your code files | What you want the infrastructure to be when Terraform carries out a deployment |
| Terraform State file | Terraforms view of your infrastructure as of the last deployment |
| Infrastructure | What your infrastructure actually is
|
The diagram below shows what happens when we tell Terraform to produce an execution plan or to deploy infrastructure.
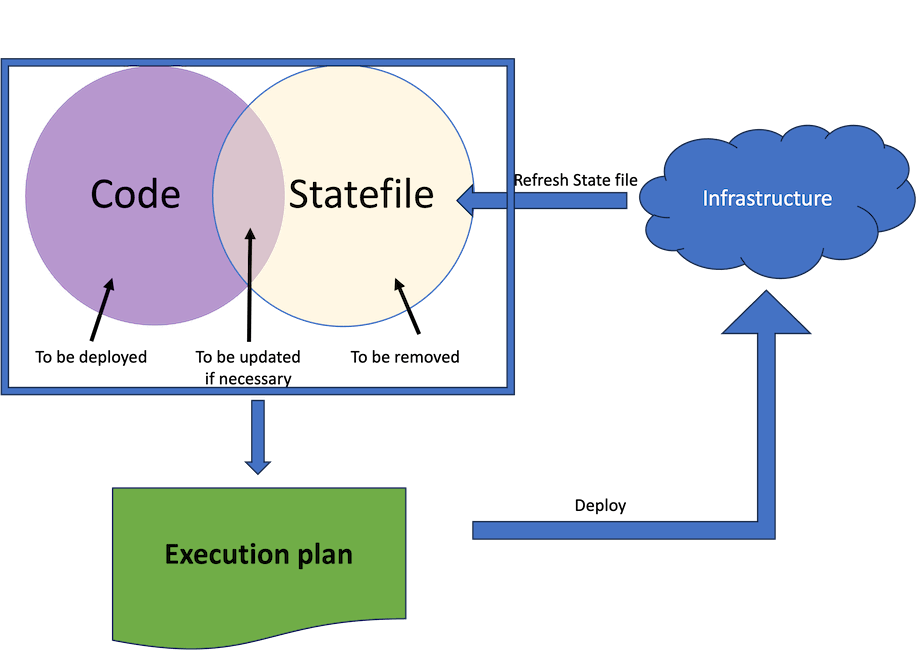 Understanding the relationship between Terraform code, the contents of the state file and infrastructure
Understanding the relationship between Terraform code, the contents of the state file and infrastructure- Take the contents of the State file and update it from the real infrastructure
- Work out what needs to be deployed (created) updated or removed
- Build an execution plan that takes into account the various dependencies
- Deploy infrastructure based on the execution plan
Scenario | Action |
|---|---|
| Created outside of Terraform | No action. Terraform has no awareness of knowledge of this infrastructure. |
| Created by Terraform, updated outside of Terraform | Terraform will see the difference and update that item to match your code |
As a general rule don't mix and match your infrastructure creation methods. If you create something without using Terraform and later try and create it with Terraform then you will get an error.
If you are looking to adopt Terraform and have existing infrastructure then from Terraform 1.5.0 there is an import statement that lets Terraform become aware of infrastructure and place the appropriate entries in its state file.
It is also possible to tell Terraform to forget that it manages a particular piece of infrastructure.
Deploying your code
The basic commands you need to know are as follows.
Terraform command | Action |
|---|---|
terraform init | Downloads all relevant providers and plugins |
terraform plan | Refreshes the state file then produces an execution plan but does not make any infrastructure changes. You can store the execution plan for use later using the -out parameter |
terraform apply | This will deploy your infrastructure but will pause to ask you to confirm deployment after displaying the execution plan. If you used the -out parameter with terraform plan then you can tell Terraform to apply the previously generated plan. |
terraform fmt | This will format your Terraform code. |
terraform destroy | Any infrastructure for which a state file reference exists will be destroyed, or at least an attempt to destroy it will be made. |
The learning experience
I recommend finding courses and articles by Ned Bellavance. Ned is a Hashicorp Ambassador which is something like a Microsoft MVP. He was also an MVP.
As a general comment I found Terraform relatively easy to learn and to pick up the concepts. For me there were some pain points learning to use Terraform for real infrastructure.
Infrastructure knowledge
This is a big one. You have to gain a thorough understanding of the infrastructure you are proposing to manage. If your infrastructure is complex then the scope of what you have to understand can be huge. I found it relatively easy to understand the basics of the AWS services we use but struggled with the security policies and roles and the plumbing to connect the components together securely.
No dedicated IDE
If you are used to programming in one of the JVM or .net languages then debugging Terraform code can be a frustrating due to the absence of things I took for granted in the IDEs used for traditional languages.
In something like Pycharm I can click on a Python function and a menu option or key combination will tell me everywhere that function is used. As far as I am aware there is nothing like that for Terraform. There is no REPL (Read Evaluate Print Loop) capability as there is in most IDEs. There are plug-ins for VS Code but these I would class as "better than nothing".
You can't really step through your code, there are no break points. I found that many cases the values I needed to debug the locals.tf file were marked as "only available after apply".
Performance
Under the hood Terraform is calling APIs and it can make a huge number of calls to those APIs. It feels like Jeff Moden's RBAR (Row by Agonising Row). A terraform plan or terraform apply can be slow especially when you are used to traditional languages..
When using the GitHub provider the underlying appears to be rate limited. That is, when you send a lot of traffic to it the rate limiter deliberately slows down the responses. If you manage a significant number of GithHub resources this deliberate slow-down can be very frustrating.
Provider upgrades
These are double edged swords. The plus side is that the providers, including Terraform, are making worthwhile improvements to their functionality at a dramatic rate.
The down side is that the pace of change can be punishing with more deprecations than you might expect.
Infrastructure destruction
For our Terraform reusable modules our CICD pipeline performs various apply/destroy cycles to test those modules. Although there has been a marked improvement in Terraform there are still cases where the execution plan gets the order of destruction wrong which causes failures. Terraform does have a depends_on attribute which is akin to a query hint though this is fallible.
As a beginner it takes time to work out whether a refusal to destroy is down to legitimate provider safeguards rather than Terraform execution plan hiccups. When deploying cloud infrastructure you must check for left behind infrastructure if you want to avoid unexpected bills.
Hints and tips
If an infrastructure or Terraform object has a description object then use it and make its contents meaningful.
Devise and apply a carefully thought out naming convention. Given that IDEs are offer limited help in navigating Terraform projects a good naming convention will help enormously.
Use terraform fmt and also tflint. If you are working with AWS there is a specific plugin called tflint-ruleset-aws.
For people needing to run different versions of Terraform then for Mac and Linux users consider the tfenv utility to allow you to switch between versions.
Being able to iterate over a data structure that is easy to maintain in order to generate infrastructure is extremely useful. However, there is a balance to be struck between keeping your Terraform resource code terse and easy to understand against the complexity that may appear in any locals{} block.
There are some things that Terraform can do that are not its core strength and Hashicorp themselves warn against using it as a infrastructructure post provisioning configuration tool. Another example is where a database provider allows the creation of schemas, tables and views. For platforms like Snowflake there are cloud and Snowflake objects that need to be created with awareness of each other. I wouldn't use this as THE way of deploying all DB objects.

