open query via linked server to db2 is showing terrible performance
-
Hi this post is mostly about cross server concepts vs a query being sent to and run on the target server and then the data simply coming back over the network. but any feedback is appreciated.
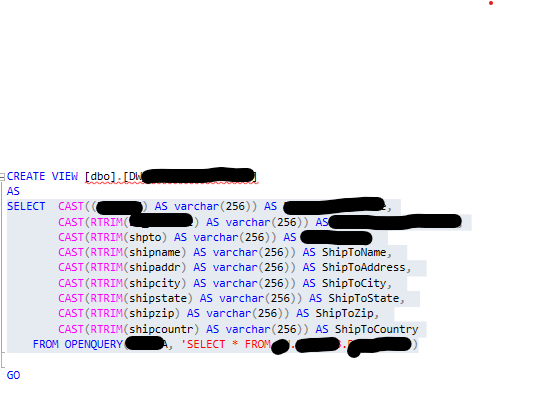
we have a sql server linked server thru which the db2 erp query (view) shown below is sent to a db2 AS400. This query returns 179 K records whose average length is 116 bytes and it takes at least 1 hr 40 minutes to run. The db2 erp was just migrated to the cloud. But even before that there were some serious performance issues. I did ask the erp owner to remove the tons of blanks in the returned data but even our security guy thinks that isnt going to help. The erp owner says she gets quick response when running our various queries directly.
In a previous life i thought more about cross server performance issues but have to admit i thought they'd generally be more of a problem if joins were being powered somewhere other than the target server. notice there is no apparent join here but i can ask the owner if there is one on the other side.
we are getting terrible performance on this dw extract. can the community tell me where the bottleneck is likely occurring or what i can do to come to that conclusion myself? and some possible workarounds?
my understanding is that with this erp now being in the cloud, there is a network shortcut or 2 (i think its a reduction of hops) networking can plumb for us to help but i think understanding more about the problem and the fact that this was an issue before we went to the cloud justifies asking the question now. And i think its important to mention that up to a few months ago performance was bad but got SERIOUSLY worse even before we went to the cloud with this erp.
the provider appears to be MS OLEDB for DB2.
One last thing that might be relevant...today one of the normally quick (36 seconds) queries involved in extracting this erp's dw data had to be killed after we saw it running for 1hr and 20 minutes. it was trying to extract only 504 records.

-
thx ken, what are the decent odbc drivers for db2?
and at a high level will i be running wireshark while this issue is occurring and show some sort of output from it to our network guys?
at least on their site i dont see anything descriptive about their product.
-
This is probably an issue with *how* SQL Server is sending the query to the DB2 instance. As soon as you use that view - and either join to another table or add a where clause, SQL Server is almost certainly converting it to a cursor based process and pulling the data row by row.
Try modifying the OPENROWSET with the specific filtering you need - without joining to any local tables. Put the results into a temp table and then join to local tables.
Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs -
thx jeffrey. there is no join and we want the whole table. i was a little confused by these 2 statements which seem to contradict each other...
or add a where clause, SQL Server is almost certainly converting it to a cursor based process
Try modifying the OPENROWSET with the specific filtering you need
-
some things to consider - normally, although not always, data conversion to char datatypes should be done on the linked query side - not sure if this is the case and if the data being sent is already char type. if not you should do the corresponding cast on the openquery select itself.
I also query why convert all to varchar(256) - is that truly the correct size for each of those columns?
regarding the "slow query" you mentioned - was slowness the same using a straight "select ... from openquery..." instead of using the view? views can misbehave while straight sql is more stable.
-
thx frederico, i might be misunderstanding.
that view is doing the trimming over on the linked server (sql server) side, not db2. are you saying it might help to put all the trimming etc right in the openquery? i can try that.
i inherited all those conversions. i can shore them up to what they should really be.
i will also try a straight select and post back here.
-
here is what i got...my takeaways are that the blanks coming across the network are a factor (at least for our driver) and like the community suggested , waiting to do rtrims on sql rather than sending them to db2 is a bad idea. A peer suggested IBM's connector/driver. Interestingly i just noticed that out of about 180k ship to dimension records , and for the attributes we need in the DW, 175,921 are duplicates.
- sending the rtrim down to db2 on each col inside the openquery with a select * from the openquery gave me these results (no casts, no views), not sure a view would matter though
1 column 7 minutes 3 seconds
2 columns 15 minutes 6 seconds
3 columns 22 minutes
6 columns 28 minutes compared to at least one hr 40 mins
2. forgetting the rtrims and just selecting those 6 cols inside the openquery and selecting * from the latter gave me these results...this tells me the excessive volume of spaces is for some reason a factor...
6 columns i killed it at 12 minutes after it only picked up about 1/7 th of the data.
3. selecting with UR (i think db2's version of nolock which i'm not a fan of) and otherwise like #1
6 columns 26.75 minutes but who wants the risk of dirty reads to save less than 2 minutes?
-
yes I mean doing it by having DB2 doing all the work.
so it would be
select *
from openquery(remoteserver,
'select rtrim(col1) as col1
, VARCHAR_FORMAT(datecolumn, ''YYYY-MM-DD HH24:MI:SS'') as datecolumn
, VARCHAR_FORMAT(numericcolumn) as numericcolumn
from tablename')note that I am converting non char types to char - this because datatype conversion can be a lot slower than char due to structure types differences between SQL and other vendors.
Viewing 9 posts - 1 through 9 (of 9 total)
You must be logged in to reply to this topic. Login to reply