Parallel Index Operations on Azure Managed Instance
-
MS Articles say that Parallel Index Operations are only available in Enterprise Edition, but I have an article that implies (says) it can be configured for Azure Managed Instance , and is enabled by default: https://learn.microsoft.com/en-us/sql/relational-databases/indexes/configure-parallel-index-operations?view=sql-server-ver16
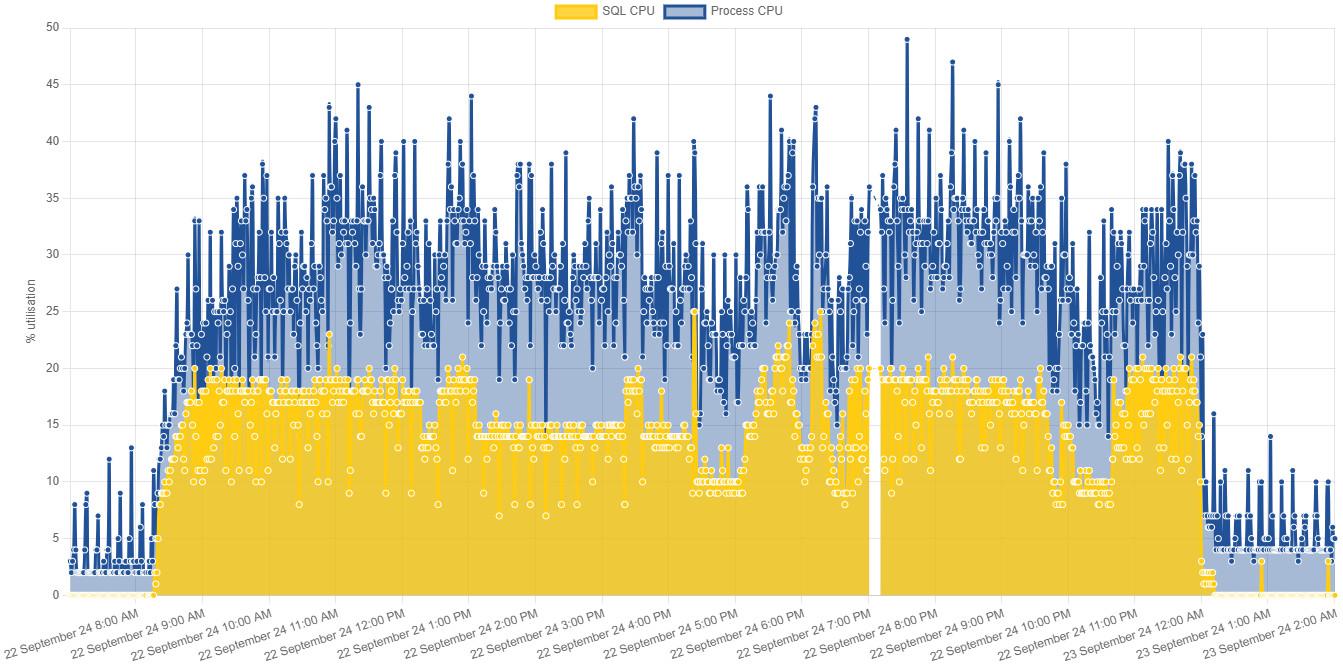
However my SQL CPU load data during the Index Rebuild shows a load of only 20% on an 8 Core MI server (the gold area).

As you can see, this is 16 hours of rebuilds. To complete the picture, there is only ONE user database with ONE large table (470GB) in it, with a clustered index and 3 non-clustered indexes.
I was thinking of using WITH MAXDOP = 4 to try get a shorter duration, but I'm not sure if this won't actually make it worse.
Why would SQL opt to not use more cores, or is it using all the cores, but just not able to use more load on the cores? Besides the optimization, there's little else going on over the maintenance window.
Leo
Nothing in life is ever so complicated that with a little work it can't be made more complicated. -
Thanks for posting your issue and hopefully someone will answer soon.
This is an automated bump to increase visibility of your question.
-
I found the issue, and the restriction isn't at the CPU level.
It turns out the server is memory constrained, with PLE over the index optimization period dropping below 60 seconds most of the time. In parallel to and partly as a result, Disk Latency Writes goes up to 200ms and above, and Disk Latency Reads initially peaks at 50ms for about 45 minutes, then settles down to a steady 25ms.
Simply put it looks like SQL simply doesn't have enough data "on hand" to keep the CPUs more than 20% occupied. I'm encouraging the client to switch to Azure MI Next-gen, with more CPU and the improved IO capability to see if this makes significant improvements. I would really like to get the index rebuilds down from the extreme of 16 hours.
Leo
Nothing in life is ever so complicated that with a little work it can't be made more complicated. -
To be honest, you're probably wasting your time doing traditional index maintenance. Worse yet, you could actually be perpetuating fragmentation if you're using REORGANIZE.
With the thought that I named the presentation the worst way possible, please see the following 'tube which is NOT just about Random Guids. I just used them because they're the poster child for fragmentation and I use them to bust a lot of fragmentation myths and to destroy the supposed "Best Practice" Index Maintenance that most of the world (including a younger me) had been (maybe still are) has been following for the last almost 3 decades.
https://www.youtube.com/watch?v=rvZwMNJxqVo
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Just get a bigger truck may get this thing done $$$$
Did you validate and test other options for your single table ( 476GB ) ?
How much of that data is active?
Is your clustered index accurate?
Any indexes that don't have an optimal usage?
can you shift data at rest?
On top of that, when your db resides in the cloud, your operation may also cause your PaaS to get throttled due to this atypical behaviour !
Johan
Learn to play, play to learn !Dont drive faster than your guardian angel can fly ...
but keeping both feet on the ground wont get you anywhere :w00t:- How to post Performance Problems
- How to post data and code to get the best help- How to prevent a sore throat after hours of presenting ppt
press F1 for solution, press shift+F1 for urgent solution 😀
Who am I ? Sometimes this is me but most of the time this is me
Viewing 5 posts - 1 through 5 (of 5 total)
You must be logged in to reply to this topic. Login to reply