

Many companies have technical debt which consists of applications and/or databases that are no longer in support or cannot be upgraded. How can we get this data in an Azure Data Lake when the size of the tables are large and there are not slowly changing dimensions within the source database tables. Do not worry, there is a commercial off the shelf (COTS) solution that can help. Fivetran is a company that specializes in the automation of disparate sources into a chosen destination. This extract and load (EL) tool will read the write ahead log (transaction log) off your ancient database and replicate the data to a modern data platform.
Business Problem
Our manager knows the pubs database, which is installed on a PostgreSQL database in our data center, does not have any slowly changing dimensions. How can we replicate this data to an Azure Databricks schema containing delta tables?
What are slowly changing dimensions (SCD)? Type 1 SCD updates the record in place as well as an update timestamp. To perform an incremental load, just find all the records that have new timestamps. Type 2 SCD or effective dating is used to understand when a record was important. For instance, John was a data architect level 1 between 1/1/2017 and 12/31/2020. He was promoted to level 2 on 01/01/2021. The first record would have start and end dates reflecting the period in which the job title was active. The second record would have a begin date of 01/01/2021. The newest records would have an end date with a null value.
Another way to incrementally load records from a database table that does not have slowly changing dimensions is to use a hash function. All columns except for the primary key columns are joined together using a computed column. Null values are replaced with a default value for a given data type domain. The hash function is applied to this large string to create a unique value. Now, we can use the primary key and hash column to compare what is in our data center to what is in the cloud? Any matches on primary key with mismatched hash keys are changed records while non-matched primary keys in the source indicate a new record. This technique is not without possible issues. If you have schema drift, then the all the hash keys are invalid when a new column is added. Collison of keys is a possibility if not enough bits are used.
The best solution is to use a COTS package such as Fivetran. All insert, update, and delete actions are written to the log before persisting to disk. We know exactly what has changed and can incrementally load the data into the cloud. Even this technique might have issues due to the source system. For instance, an ALTER TABLE command is a Data Definition Language (DDL) statement. This information might not be captured in the logs of certain databases. Therefore, a DROP TABLE followed by a refresh might be needed to add schema changes to the target tables.
Technical Solution
A trial version of Fivetran will be used to create the proof of concept (POC) for our boss. The following tasks will be explored so that we have a complete understanding of how to deploy Fivetran on additional application servers.
- Prerequisites for Fivetran
- Install Fivetran Software
- Configure Fivetran repository
- Configure source and target systems
- Create source and target locations
- Create a new replication channel
- Snapshot load of pubs schema
- Test insert, update and delete actions
- How to handle schema drift
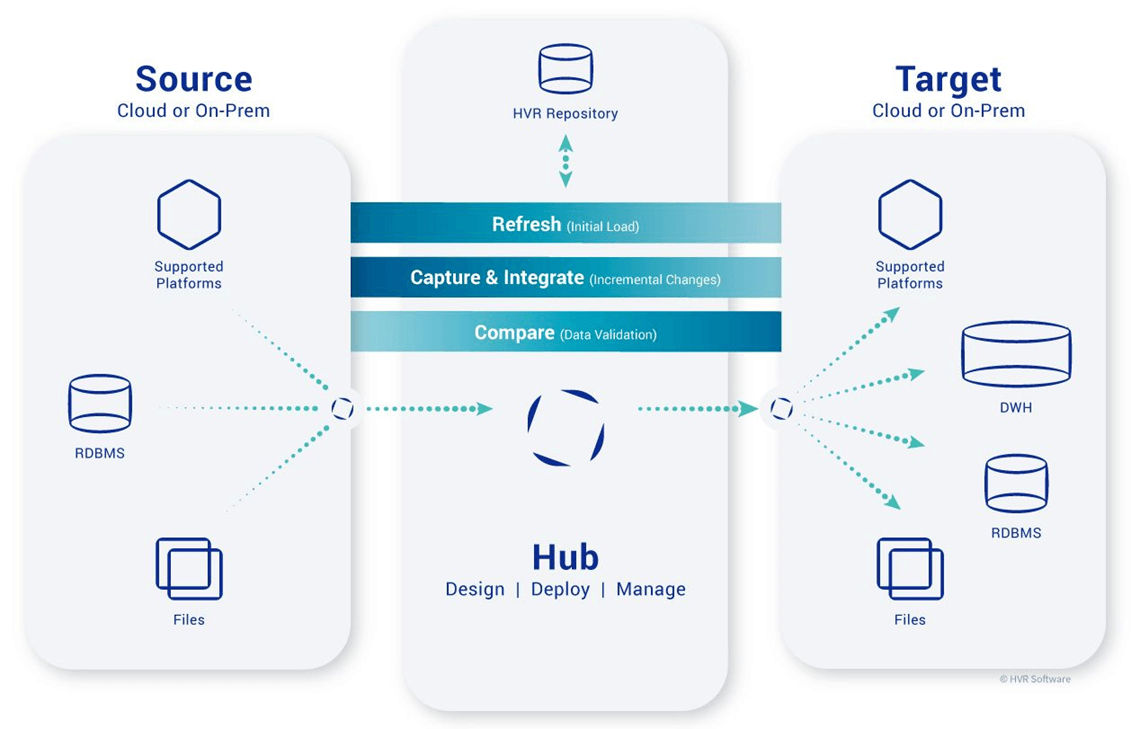
The image below was taken from the Fivetran documentation on the High Availability Replication (HVR) software. This software uses a hub and agent design. Since our POC only has one database, we only need to have the hub. As you can see, many different types of sources and targets are supported by the software.
Installation Prerequisites
The HVR software requires the PERL language to be installed locally. I chose to download and install Strawberry Perl for Windows since it is free.
Download the MSI package and execute the program to start the installation.
The installation wizard will tell you when the PERL language has been successfully installed. Make sure the bin directory has been added to the search path. This is an old school technique for MS DOS but used by many client applications.
Install HVR Software
The first step is to create a cloud account with the Fievetran for a free trial. To get the software, we need to log into the website using this url.
Go to the downloads section of the portal. Choose the latest windows executable for HVR.
Start the Microsoft Software Installer (MSI) to begin the installation. There are many screens to go through and I included all of them for reference.
Like most software packages, the vendor is asking us to accept a license agreement.
The default destination directories is where the software will be installed.
You can rename the program folder if you want to.
Since we have only a single use case, we will be installing the “HVR Hub System”. If we had multiple use cases, we could set up a hub and spoke design.

The TCP/IP port settings are for the local web application. You can even set up HTTPS if you need to.
Of course, even after a successful installation and configuration, errors will occur. You can configure alerting on the hub for these events.
I decided to use the local system account for the services. If we were dealing with a domain controller and needed rights to a service, I might have ran the software under a service account.
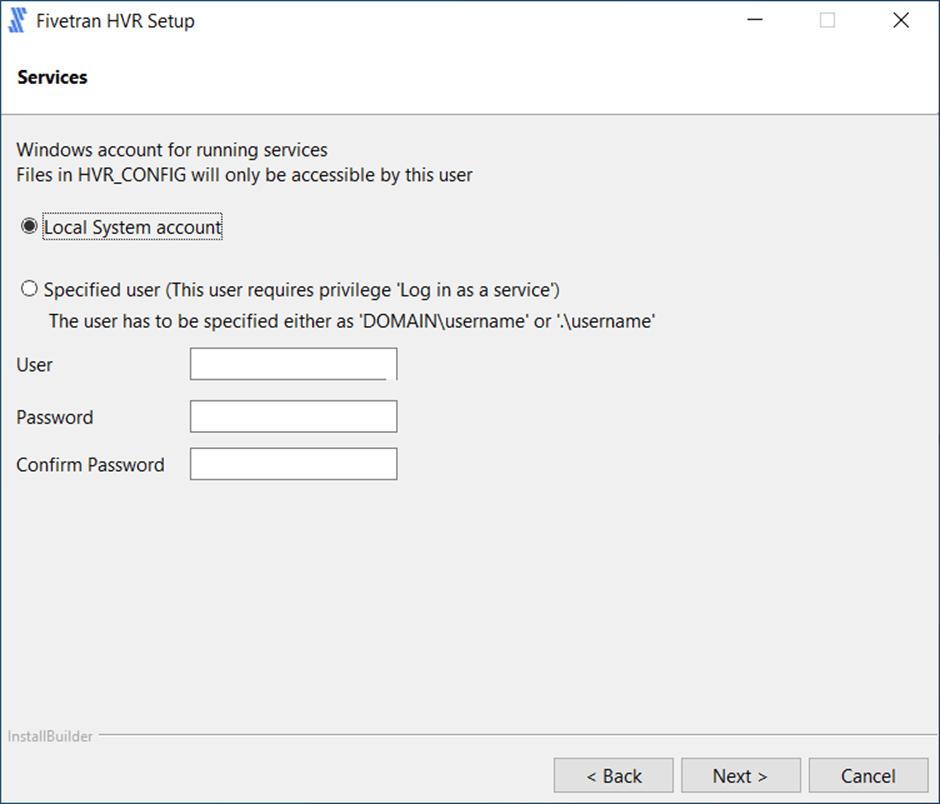
This is the most important screen of all. Please click to add the environment variables to the operating system. I do not know why this is not the default. The software will not work for windows if the variables are not defined.
It is okay to start the installation. You will see a bunch of files being unpacked and copied.
If you make it to the screen shot below, the Fivetran HVR Hub software has been successfully installed. It is now time to configure the software.
I just want to stress again the requirement for PERL. The MSI executable will install the software without it. However, when configuring the HRV software it will force you to uninstall the HUB and meet the language requirement before trying again.
Repository Configuration
The default port for the HVR software is 4340. Let’s configure the repository at this time.
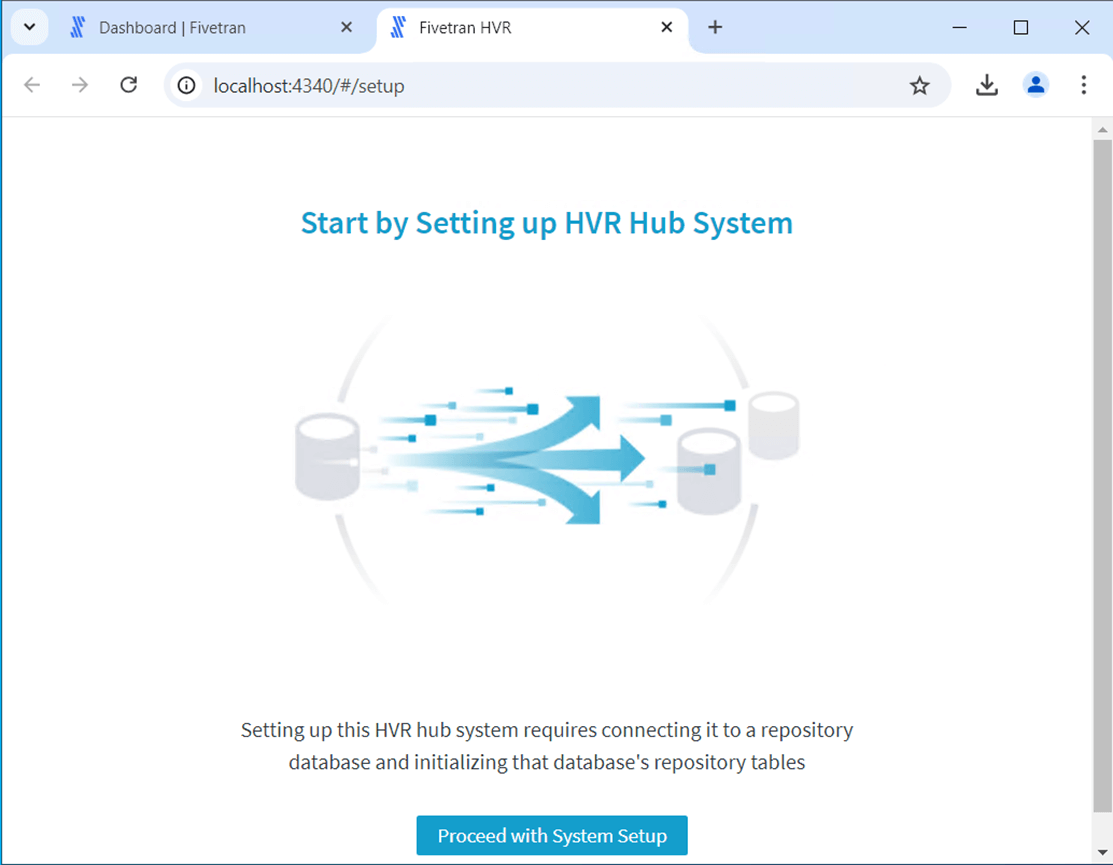
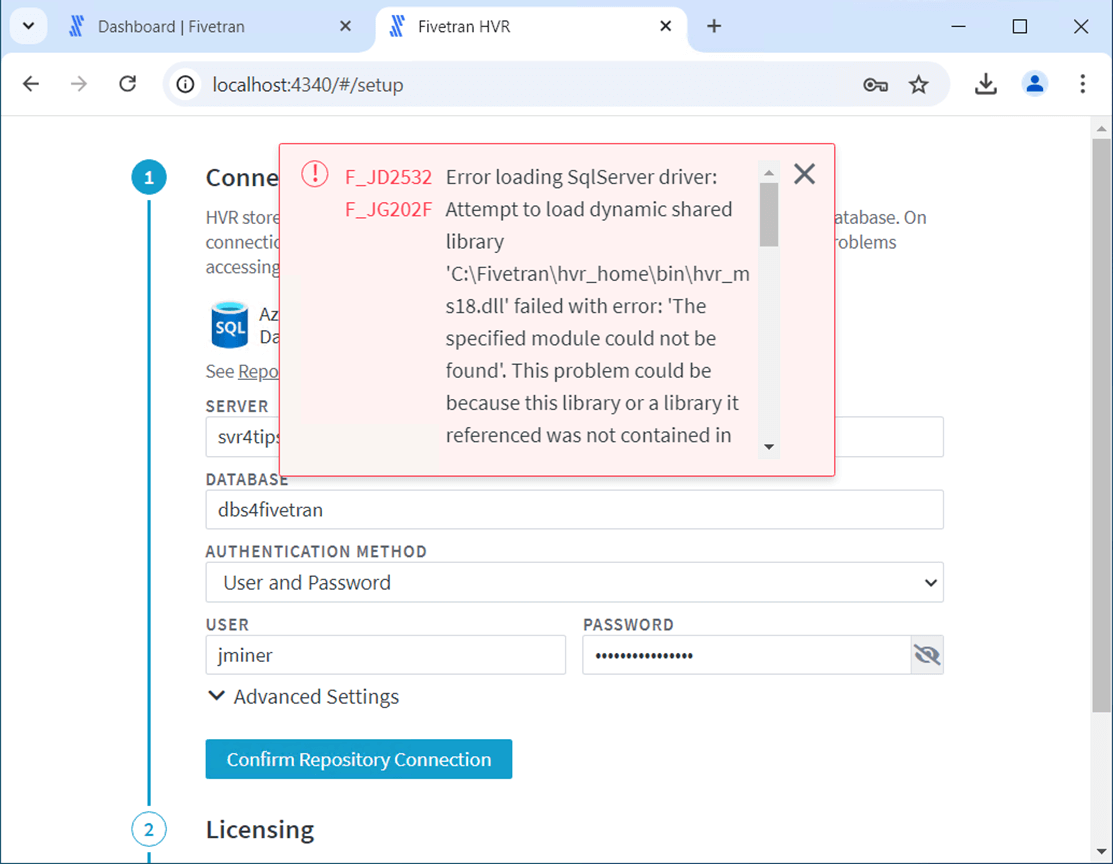
There are many different databases that can be used to contain the repository information. I chose to add a database named dbs4fivetran to an existing and logical Azure SQL Database Server. The installation errors out since we do not have the ODBC driver for SQL Server. Please download and install the driver now using this URL.
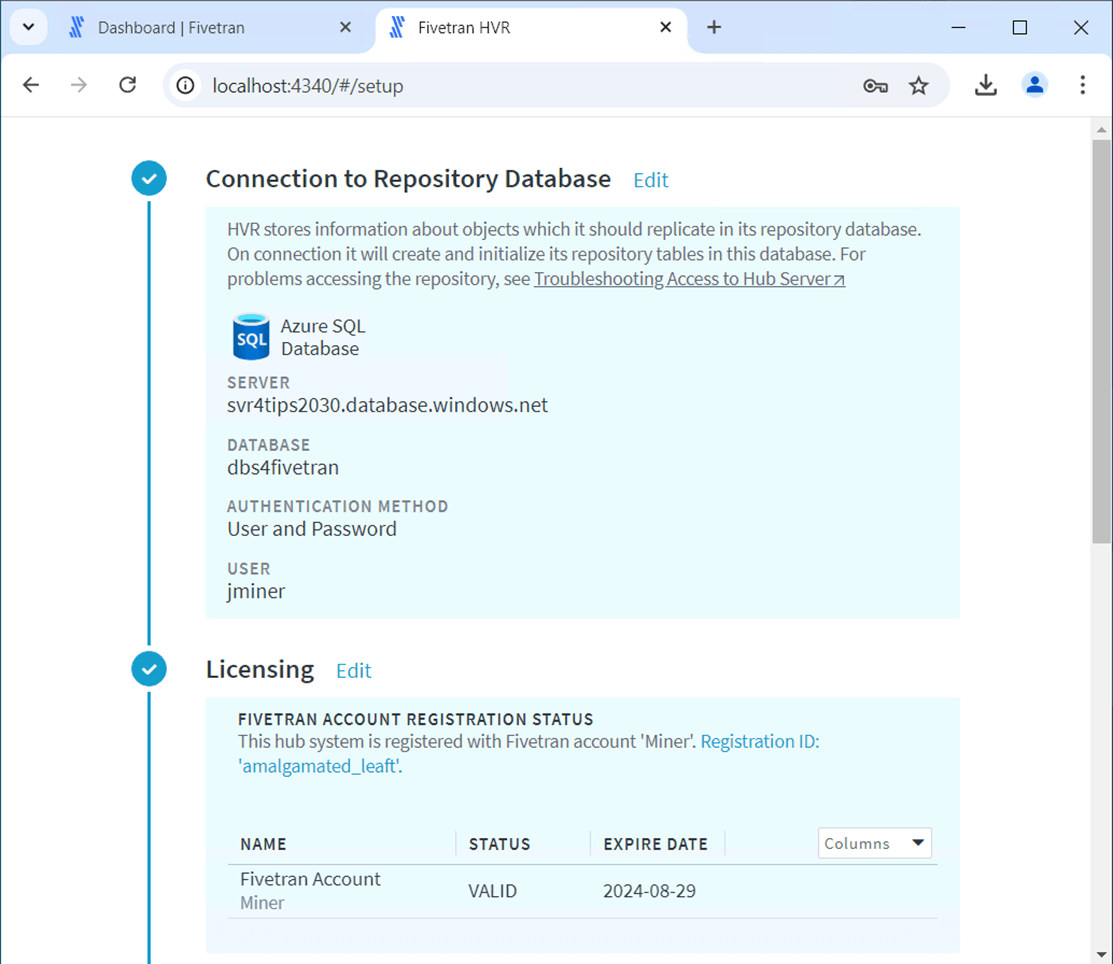
The screen shot below shows both the repository database and licensing for the trial are in order.
Configure Source and Target
Every piece of software has requirements. HVR software is no different when working with a source and target. Today, we are going to look at the source and target locations.
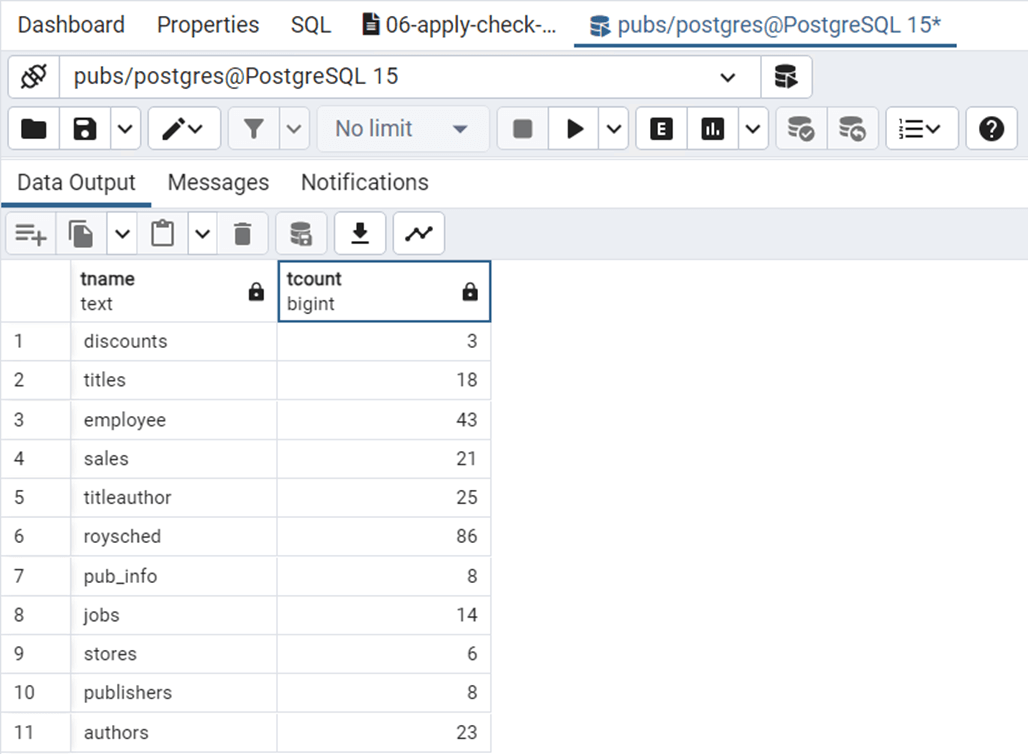
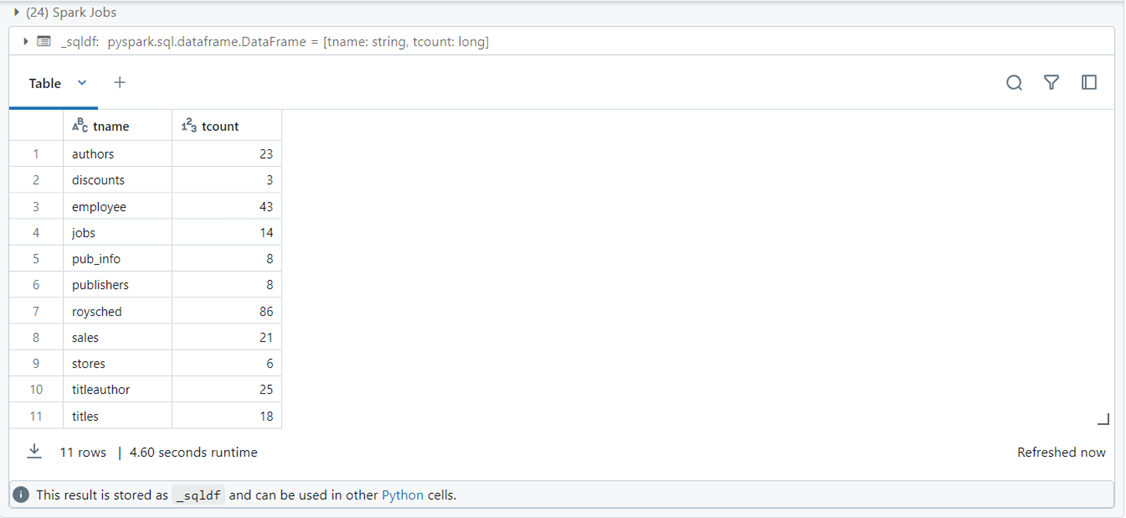
The SQL code below gets the rows counts for each table in our PostgreSQL database named pubs.
-- -- Source - get row counts by table -- select 'authors' as tname, count(*) as tcount from dbo.authors union select 'discounts' as tname, count(*) as tcount from dbo.discounts union select 'employee' as tname, count(*) as tcount from dbo.employee union select 'jobs' as tname, count(*) as tcount from dbo.jobs union select 'pub_info' as tname, count(*) as tcount from dbo.pub_info union select 'publishers' as tname, count(*) as tcount from dbo.publishers union select 'roysched' as tname, count(*) as tcount from dbo.roysched union select 'sales' as tname, count(*) as tcount from dbo.sales union select 'stores' as tname, count(*) as tcount from dbo.stores union select 'titleauthor' as tname, count(*) as tcount from dbo.titleauthor union select 'titles' as tname, count(*) as tcount from dbo.titles
Testing is the most important part of any software design. The image below shows the expected results in a Hive Database on Azure Databricks after the first snapshot is applied.
This article is not meant to be an administrator guide to PostgreSQL. However, the default write ahead logging for the database is not correctly set for Fivetran. By default, the database was set to replica. Use the ALTER SYSTEM command to change it to a value of logical. This will require a restart of the windows services. Also, any older logs will have to be truncated and/or rolled since Fivetran does not understand them.
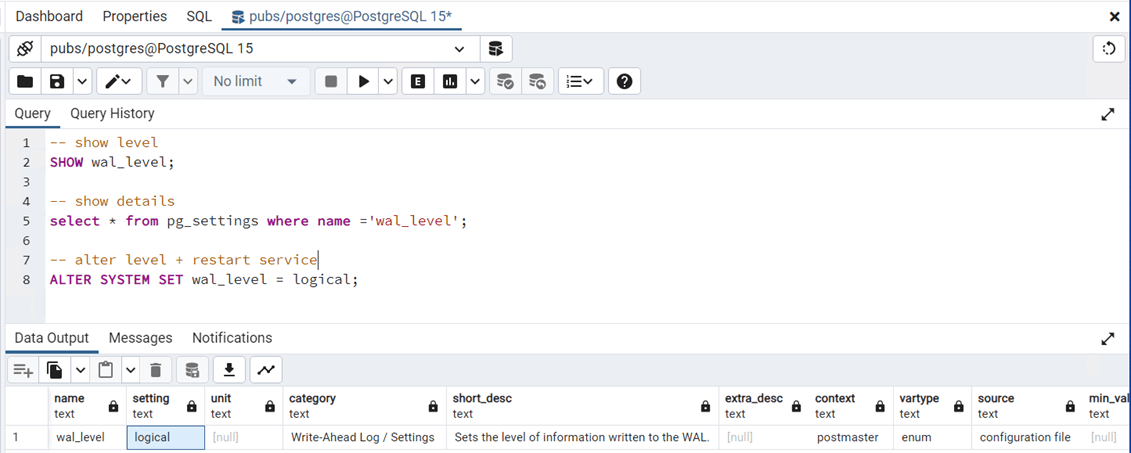
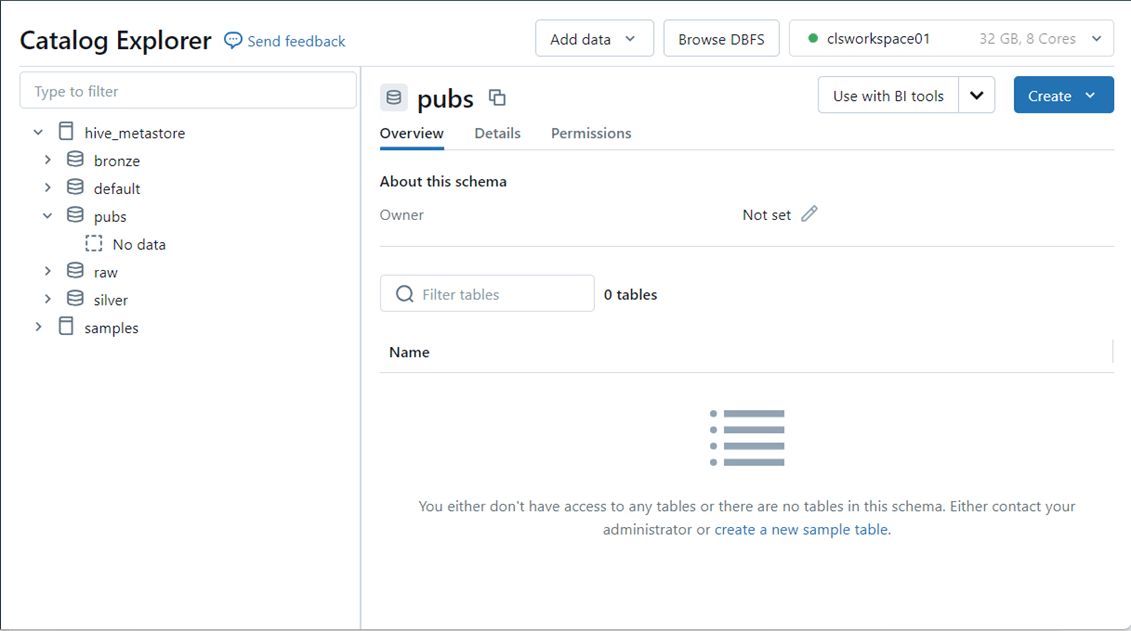
In this proof of concept, the target location is a hive meta store in Azure Databricks. Fivetran does not create targets. At this time, create an empty pubs database.
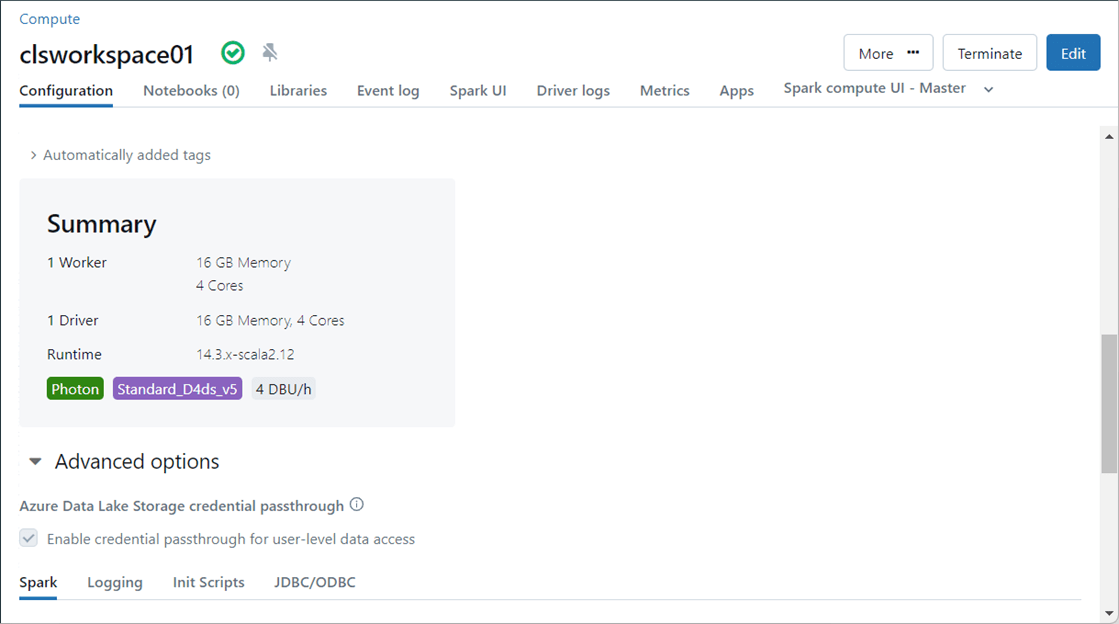
Since my Azure Databricks deployment has existed for some time, I do not have Unity Catalog. There are two things we need to configure for our cluster to work. First, we need to use credential passthrough to the Azure Data Lake Storage.
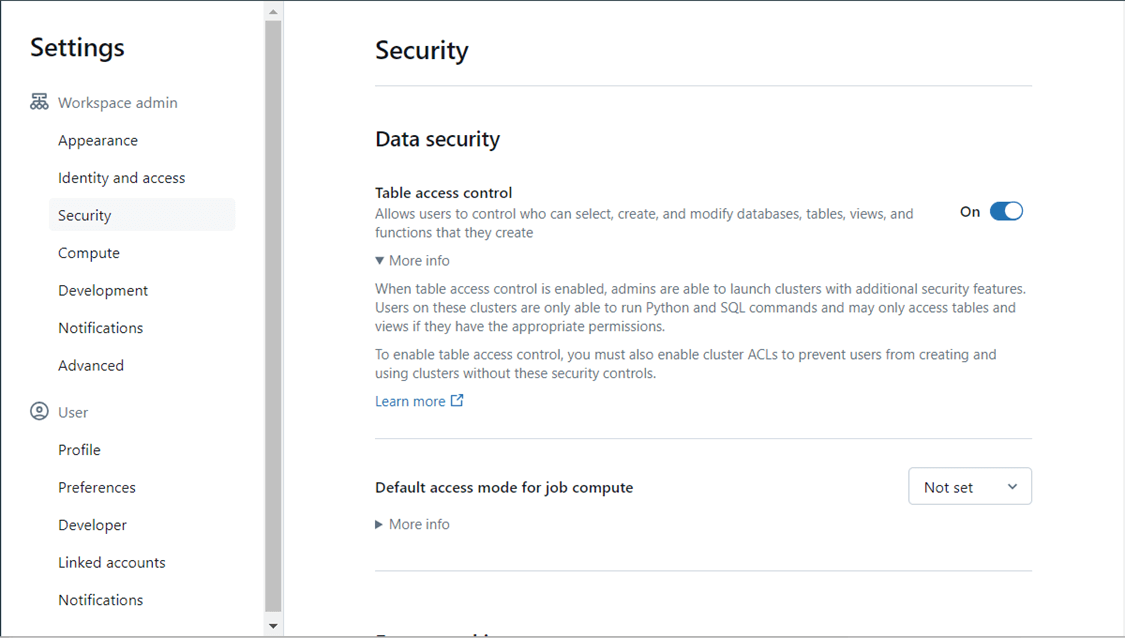
Second, we need to enable table access controls. This setting can be found to the far upper right if you are an administrator.
Source and Target Locations
All work in the HVR hub is done with the web application. The desktop shortcut will launch the site into a web page.
Here is the results of my work. The documentation for configuring PostgreSQL as the source and Azure Databricks as the target explains the details. I will give you a high-level overview of the tasks in the next few screens. Of course I used funny names for each product.
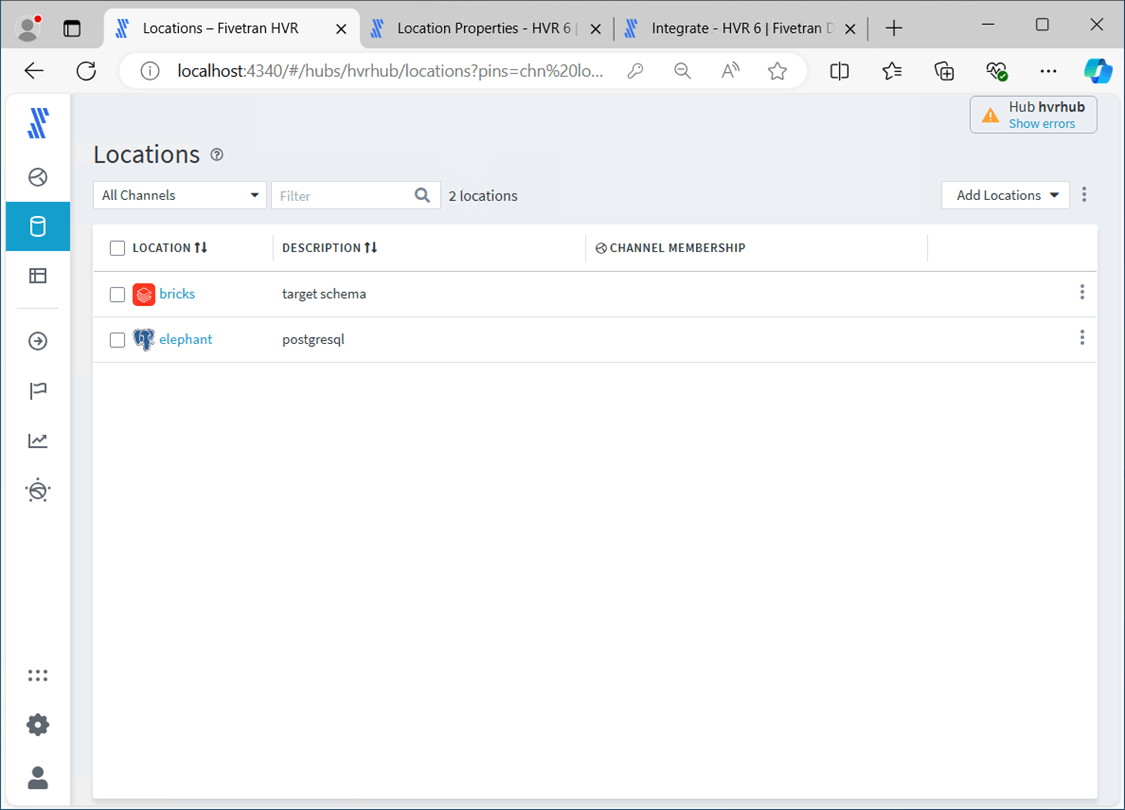
Let’s look at the elephant settings now. The typical database connection settings are seen below. I created a user named hvr_user with access to the pubs.
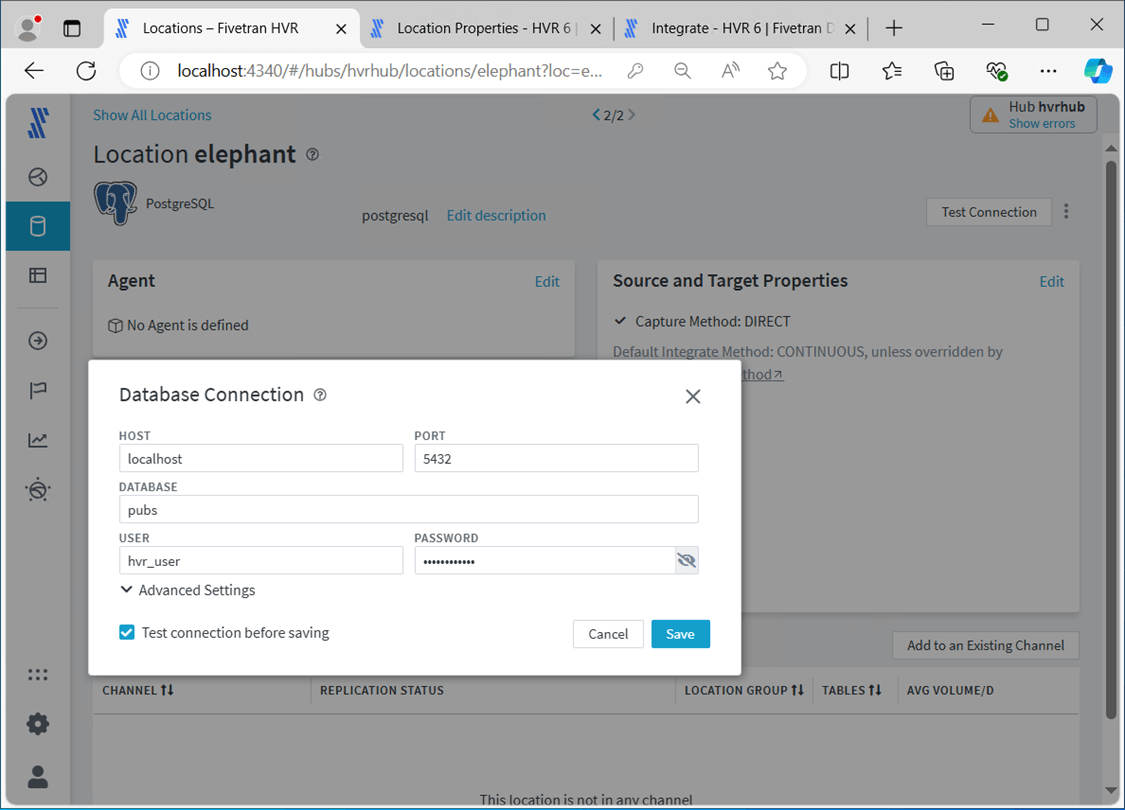
Sometimes, a source has different ways to capture the transactions from the database. I chose to read the log for new transactions.
Please install the Simba Spark ODBC driver on the machine from which HVR connects to Databricks. Please see the documentation for details on downloading and installing the driver.
Let’s look at the brick settings now. Fivetran leverages the SQL endpoint of the Databricks cluster. This information can be found on the configuration of the cluster under advance options and JDBC driver. You will need to create an personal access token for the user profile in which Fivetran will use.
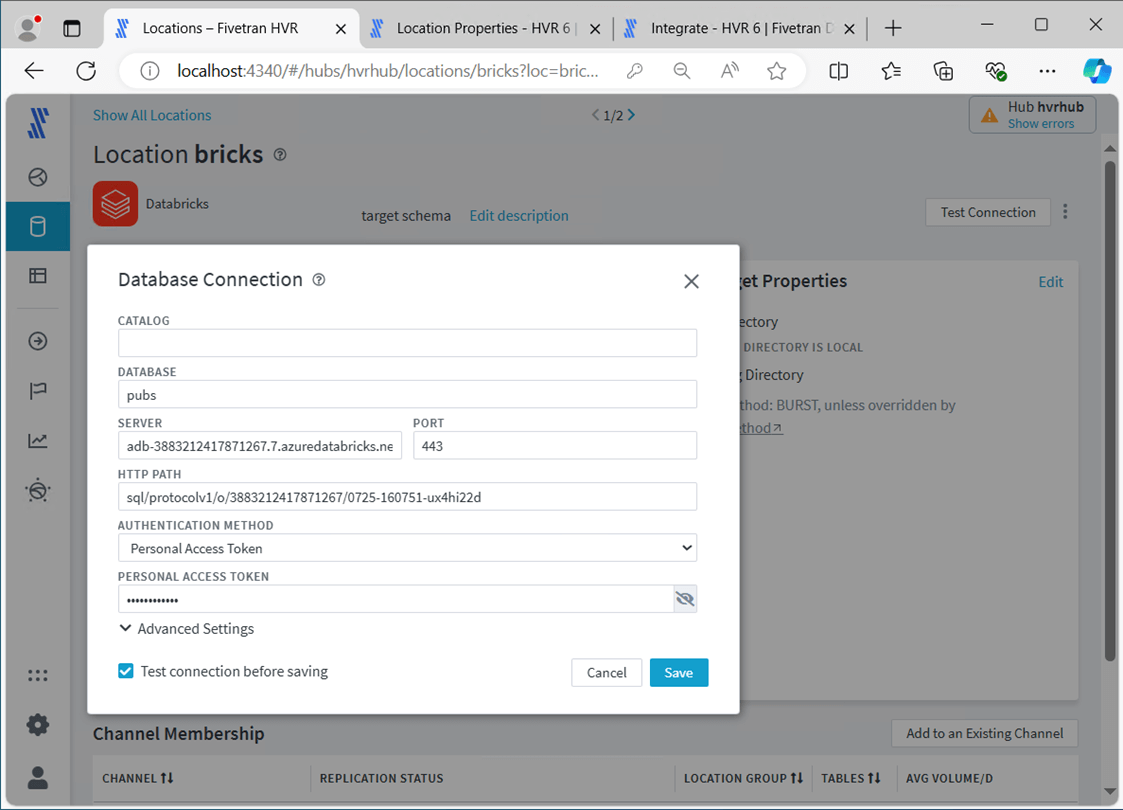
Fivetran uses Azure Data Lake Storage as a staging area for files that will be imported into the Delta Tables in the Databricks Hive Catalog. If you look at the channel logs, you can even see the COPY INTO syntax that is being used.
Regardless of how Fivetran works, we will need a service principle as well as the OATH endpoint. This is the same information that is needed to mount ADLS storage. See this article for details.
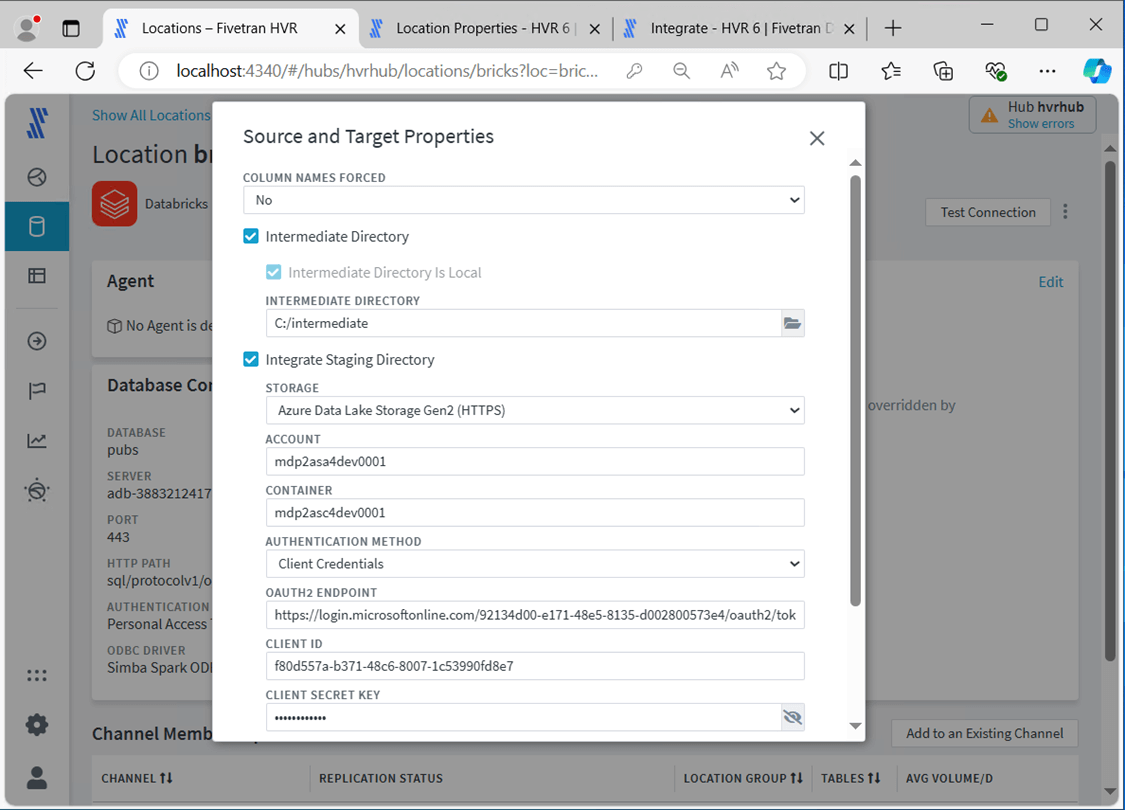
Now that we have the source and target locations defined, we can create a replication channel.
Replication Channel
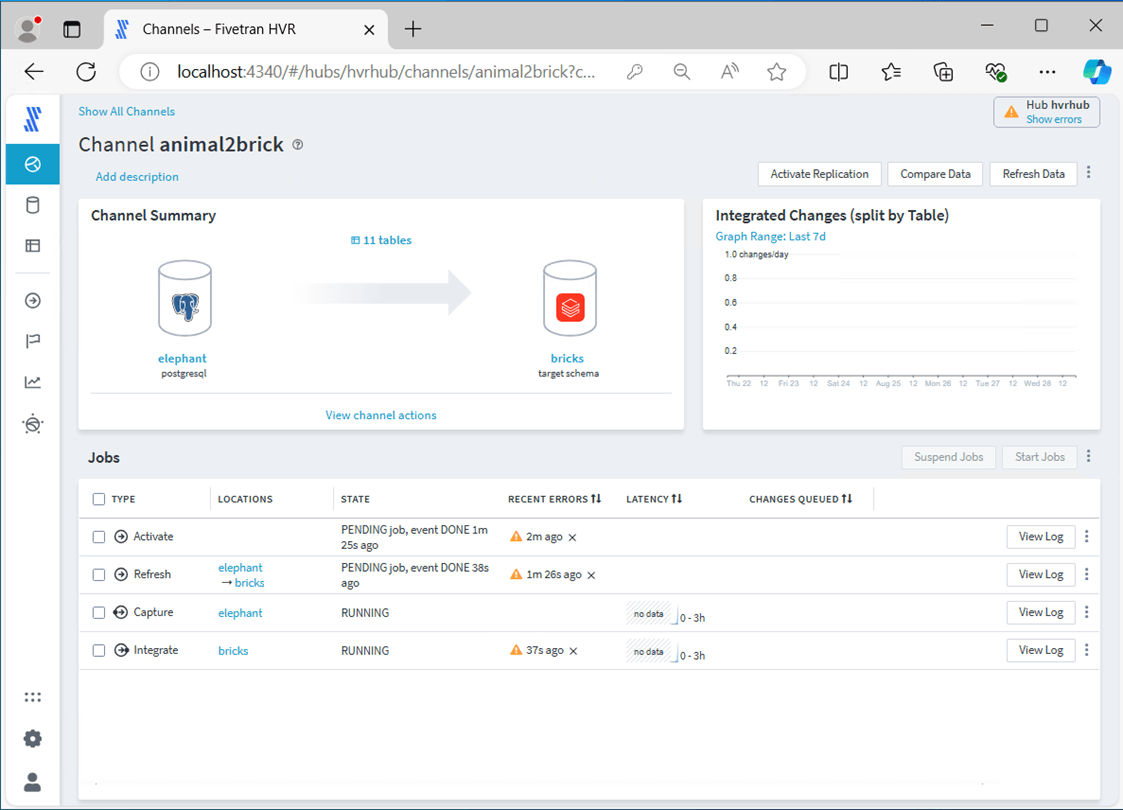
I will keep joking about how PostgreSQL is an elephant and Databricks is a brick. We essentially want to convert the animal into a brick. The image below shows the completed channel without starting replication. Let’s go over the details in the next few images.
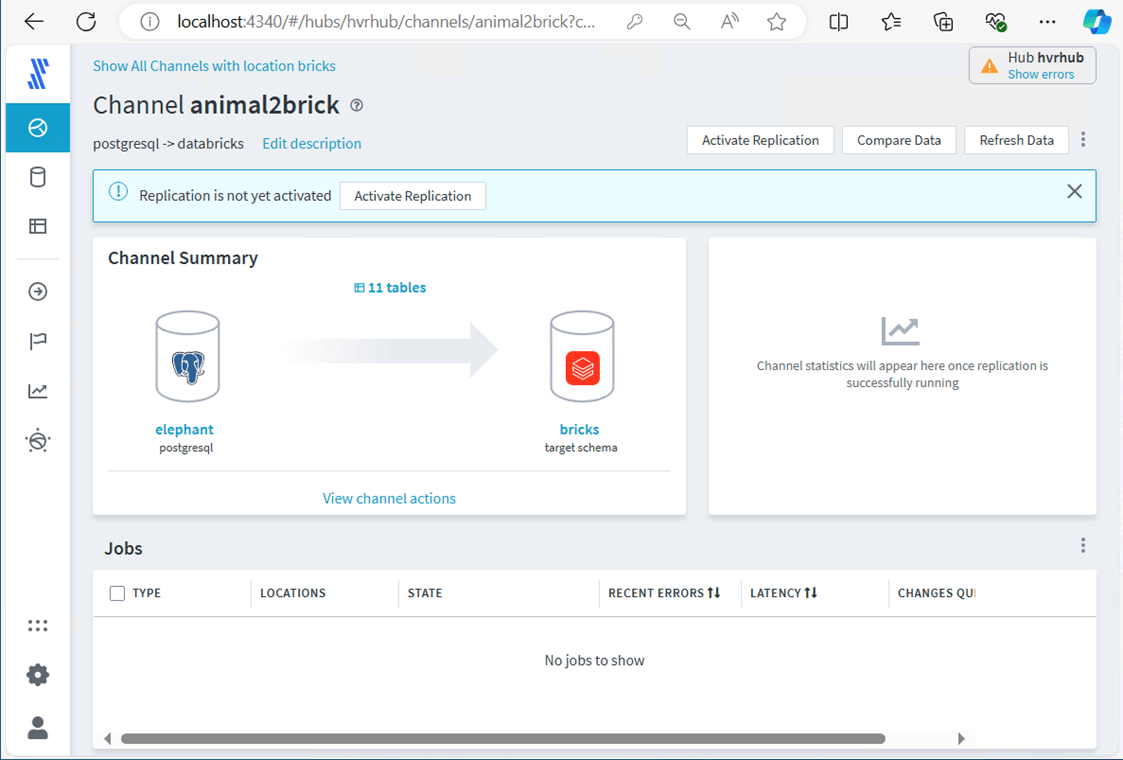
Steps 1 and 2 are focused on defining the source and target locations. I consider this step the most important part of replication. How do we want the software to act? There are three replication styles. Since I want to track all changes, I am going to select the TimeKey.

We do not have to copy all source tables over to the target. However, I chose to do just that.
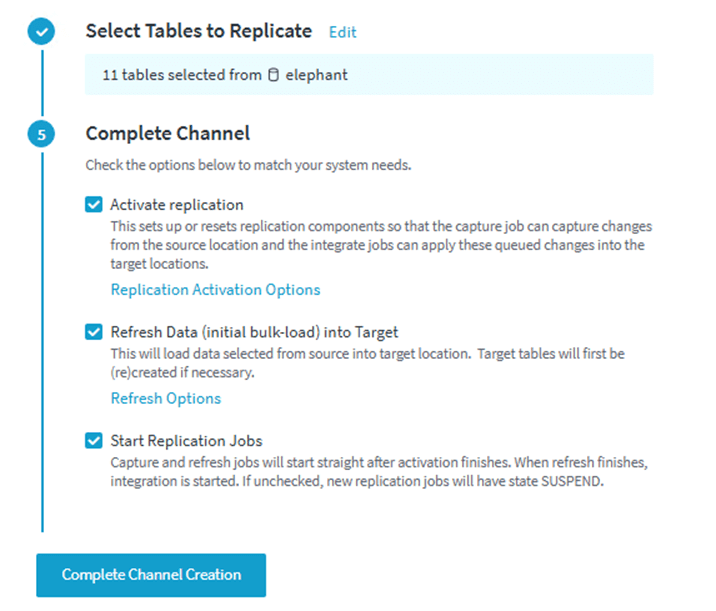
If you complete the channel create and the jobs execute fine, then you followed all the steps in the article. If there are errors, you missed a step.
Test DML Actions
The PostgreSQL database has a data manipulation language that contains the following statements: insert, select, update and delete. This is sometimes referred to as CRUD. All actions except for the select statement result in transaction log entries.
Today, we are going to execute these actions on the author’s table.
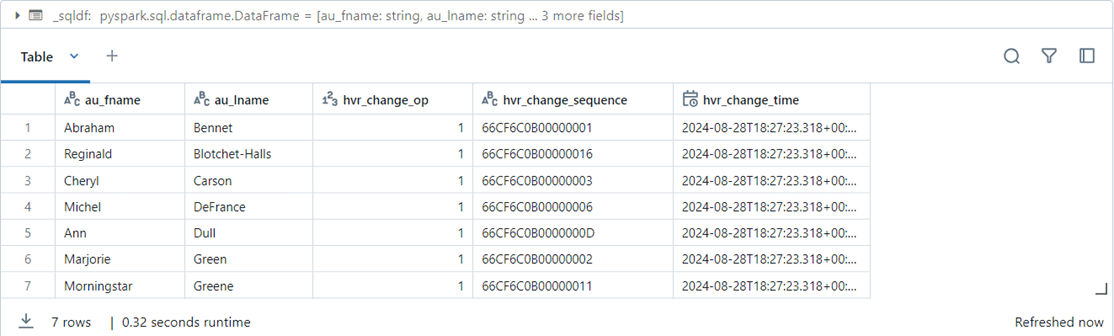
The Spark SQL seen below was executed in Azure Databricks. The output can be seen above. The three new hvr columns are important. We can do a row number over clause to get the most recent record and operation.
%sql select au_fname, au_lname, hvr_change_op, hvr_change_sequence, hvr_change_time from pubs.authors order by 2, 1 limit 7
To see if the initial replication (snapshot) matches our PostgreSQL tables, run the following Spark SQL.
-- -- Destination - get row counts by table -- select 'authors' as tname, count(*) as tcount from pubs.authors union select 'discounts' as tname, count(*) as tcount from pubs.discounts union select 'employee' as tname, count(*) as tcount from pubs.employee union select 'jobs' as tname, count(*) as tcount from pubs.jobs union select 'pub_info' as tname, count(*) as tcount from pubs.pub_info union select 'publishers' as tname, count(*) as tcount from pubs.publishers union select 'roysched' as tname, count(*) as tcount from pubs.roysched union select 'sales' as tname, count(*) as tcount from pubs.sales union select 'stores' as tname, count(*) as tcount from pubs.stores union select 'titleauthor' as tname, count(*) as tcount from pubs.titleauthor union select 'titles' as tname, count(*) as tcount from pubs.titles
The image below matches our previous table and row count test.
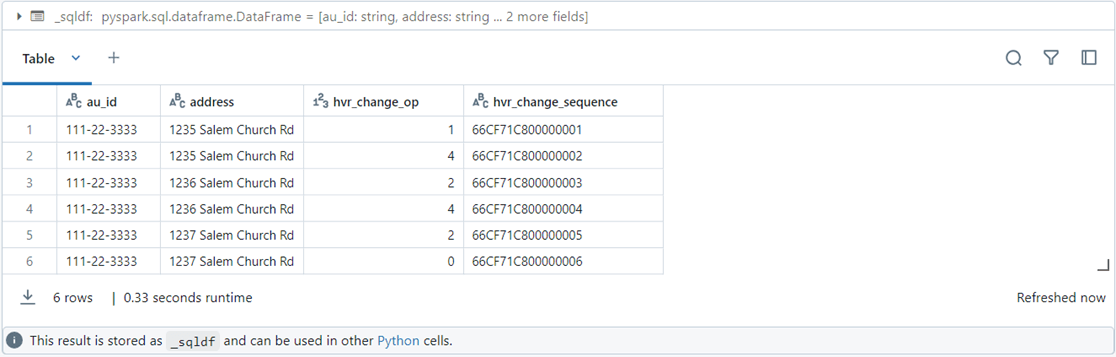
Please execute the PostgreSQL SQL below. It inserts, updates, and deletes data. There is an ALTER table statement inside the batch that causes schema drift.
-- Insert record
INSERT INTO dbo.authors (au_id, au_lname, au_fname, phone, address, city, state, zip, contract)
VALUES ('111-22-3333','Jack', 'Nash', '258-555-1212', '1235 Salem Church Rd', 'Elizabeth City', 'NC', 27909, False);
-- Update record
update dbo.authors
set address = '1236 Salem Church Rd'
where au_id = '111-22-3333';
-- Drift schema
ALTER TABLE dbo.authors
ADD email VARCHAR(255);
-- Update record
update dbo.authors
set address = '1237 Salem Church Rd'
where au_id = '111-22-3333';
-- Delete record
delete from dbo.authors
where au_id = '111-22-3333';
The image below shows the time sequence of the changes that occurred in PostgreSQL and were replicated to Databricks. What do the change op codes mean?
The image below was taken from the Fivetran documentation on HVR 6. It explains each change operation. If we sort by sequence number, we can see the last operation was a delete.

If we examine the authors Delta Table in Azure Databricks, the new email column does not show. We will talk about that issue in the next section.
Schema Drift
Change is a part of life. The chances that a table will remain static over its lifetime is probably slim. So how can we deal with changes to the underlying tables?
Typically, databases record the CRUD actions in the transaction log and Fivetran detects those actions. The AdaptDLL feature of Fivetran allows the developer to decide how to respond to DDL (data definition language) statements. Unfortunately, PostgreSQL does not have enough functionality to support this feature.
Even with AdaptDLL, a change to a primary key definition will cause a full refresh of the table. If we find the authors table in the Hub software, we can click the three ellipses to redefine the table from the source. See image below for details. You optionally can select sensitivity if you want to ignore changes.
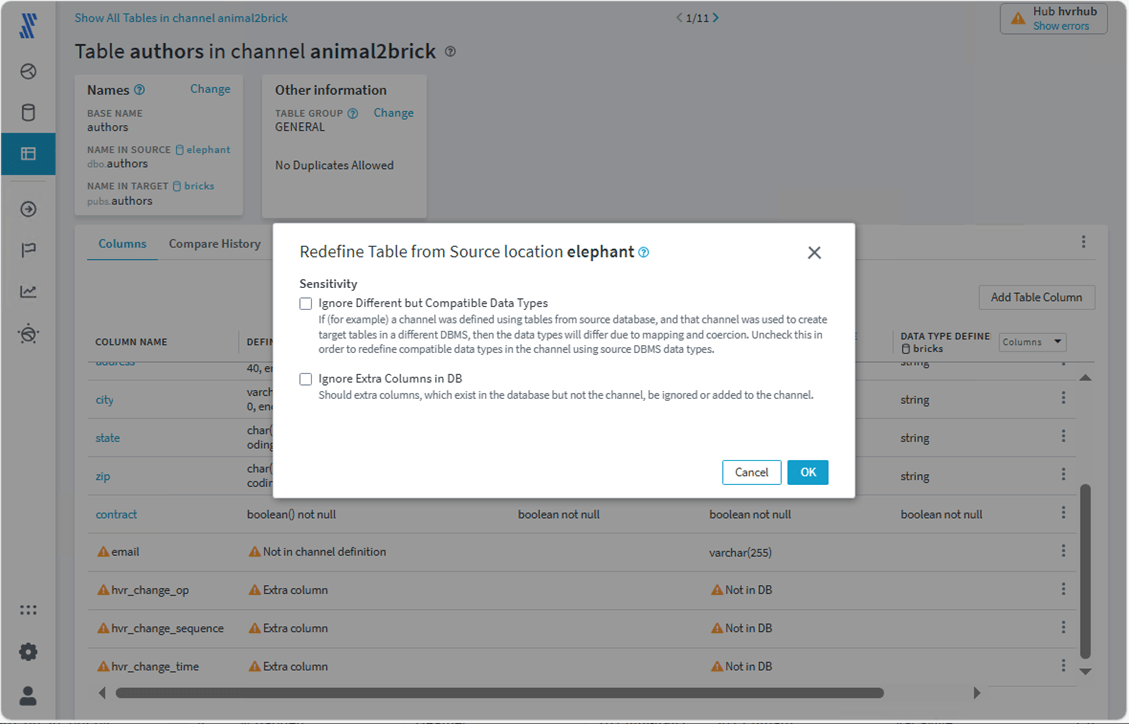
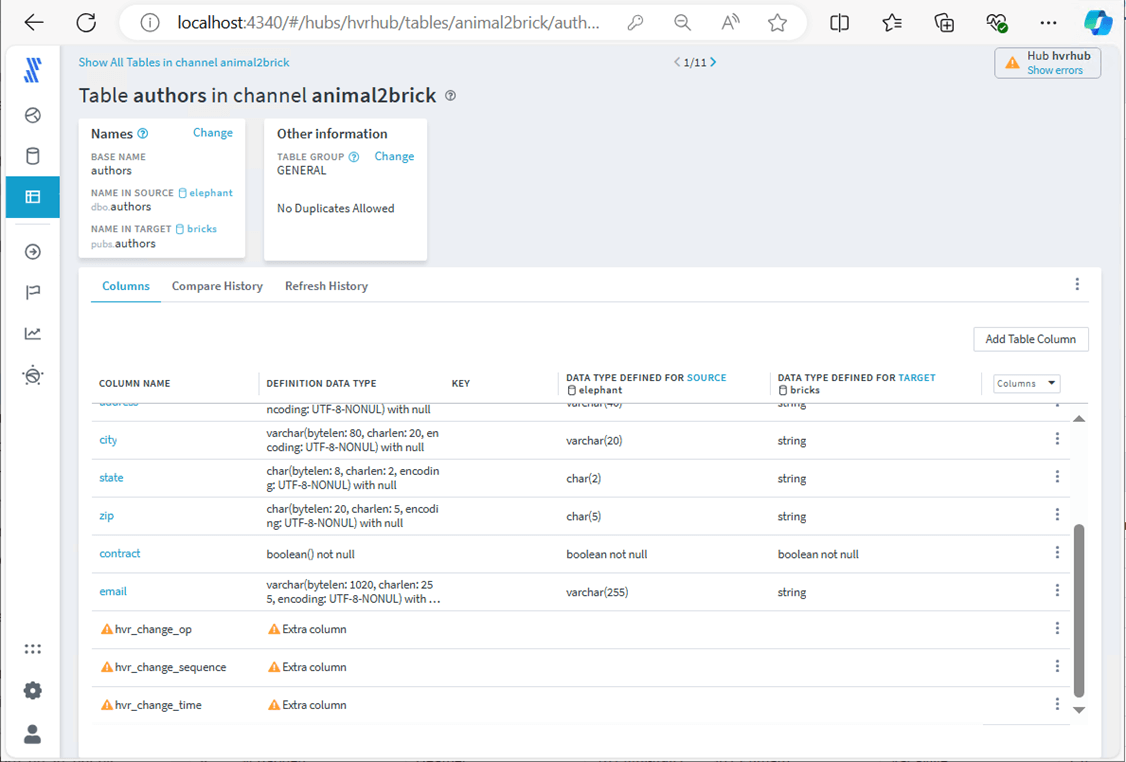
The table definition has now changed with the email column being added to the table.
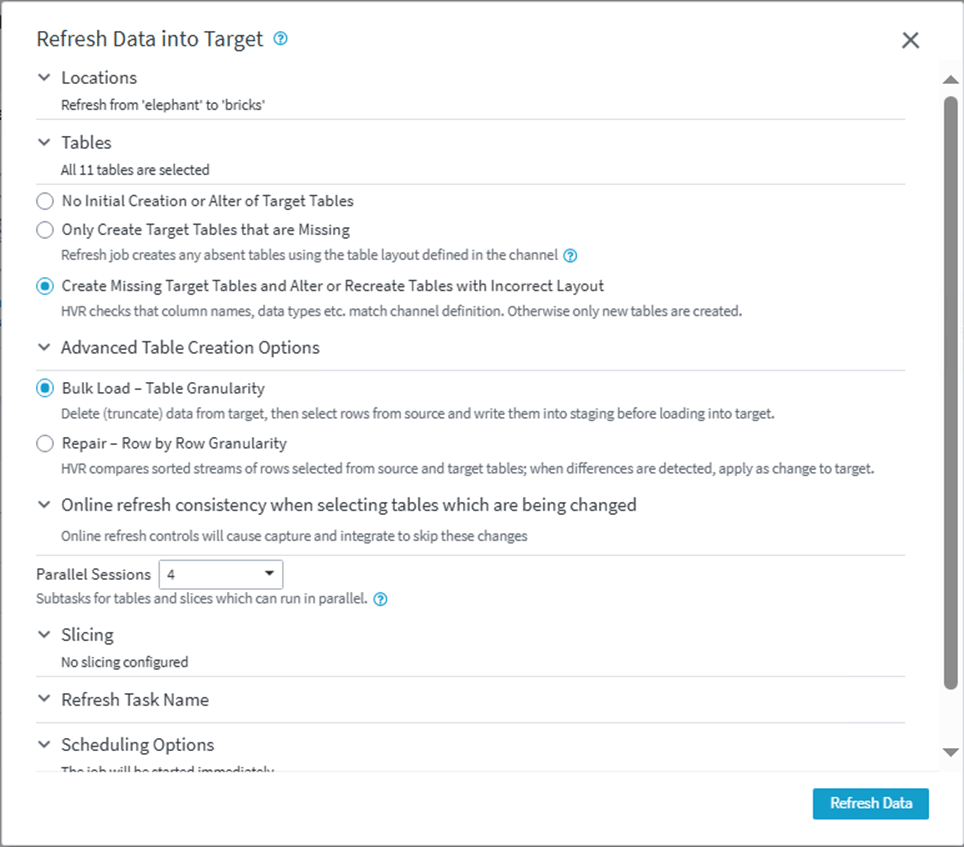
Manually drop the authors table from the Hive database. Run the refresh to create missing target tables.
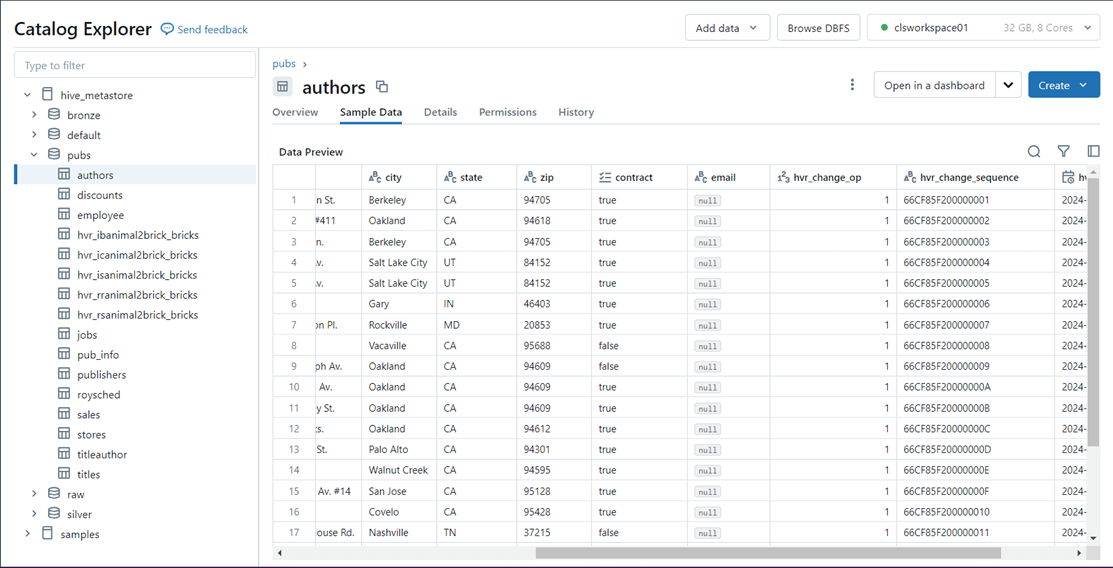
If we look at the hive database and authors table in the Catalog Explorer of Databricks, we can see the new column named email has appeared. Please note there are six tables prefixed with hvr. These are used by Fivetran and should not be touched. Additionally, a table with a postfix of _b might appear for the base tables of our model. This table appears when bursting happens.
In short, Fivetran delivers on its promise to be an easy to install and configure software for replication. This includes schema drift.
Fivetran Pricing
This snapshot was taken from the pricing tool. The pricing curve shows you the cost of monthly active rows goes down with usage. The more you use, the cheaper it gets per row.
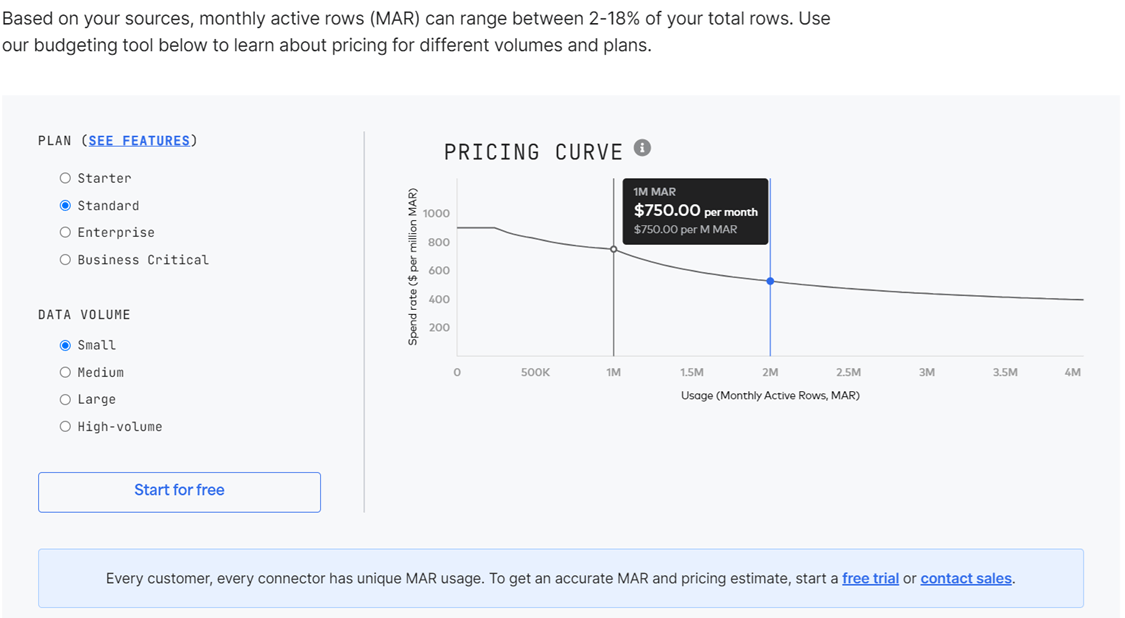
The above cost estimates 5 million total rows and 1 million MARs. The result is a yearly cost estimate of 9,000 USD. Who can write EL software on such a budget? No one can! I suggest you look at Fivetran’s product line today.
Summary
As a Data Architect, my job is to design systems for clients daily. The first step in creating a Data Warehouse or Data Lakehouse is to get data into the cloud. This rudimentary task can take days if you must write custom software. If you use a product like HVR, this same task can take hours.
Like most software, the HVR requires the following components for a PostgreSQL to Databricks replication: PERL language – used by HVR software, SQL Server ODBC driver – used to connect to my repository, and Spark ODBC driver – used to connect to Databricks. There are a couple configuration items to check off before we can start replication. For instance, the write ahead logging must be robust enough for HVR. Additionally, table access controls must be enabled on the Databricks cluster.
What I did not show you is the logs for integrate job. The rows that are exported from PostgreSQL are compressed before transferring to ADLS storage. That means the software is transferring data quickly from point A to point B. Additionally, Spark SQL is used to insert data from files in Azure storage into the Databricks Delta Tables. If you want to learn more about the internals, please see the online documentation.
To recap, I will be recommending this replication software to clients that just want to pump data into staging tables in either a Data Warehouse or Data Lake. This jump starts an analytics project and allows the architect to focus on data modeling instead of data loading.
