simple linked server plumbing
-
Hi, as a favor to a friend who needs to split databases between servers, and doesnt want to change code, he has a select on a.dbo.view that used to run from db Q easily because db A was on the same server. I havent done one of these in a long time but shouldnt he just add a linked server thru which this will happen? I can see making the target in the linked server the old server but how will sql associate A.dbo.view with that linked server?
-
SQL won't associate the view with the linked server. You will need to update the code to tell it to use the linked server. IF you break the single system up to 2 systems, you'll need code changes. No way around that.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
thx, what if he puts a surrogate db on the new server called A. And it has a view that thru the linked server sends the correct query to A thru either open query or another choice?
by other choice pls see the example below. Im trying to jog my memory. but isnt the 1st node (eg databaseserver1) the linked server name? and the second the catalog "under" the linked server as defined on the new server? if yes, i think he's asking if a synonym can translate "databaseserver1.db1." into "A. " . That way his code can stay the same. And he wouldnt need a surrogate db on the new server.
select foo.id
from databaseserver1.db1.dbo.table1 foo
inner join databaseserver2.db1.dbo.table1 bar
on foo.name = bar.name
- stan wrote:
thx, what if he puts a surrogate db on the new server called A. And it has a view that thru the linked server sends the correct query to A thru either open query or another choice?
by other choice pls see the example below. Im trying to jog my memory. but isnt the 1st node (eg databaseserver1) the linked server name? and the second the catalog "under" the linked server as defined on the new server? if yes, i think he's asking if a synonym can translate "databaseserver1.db1." into "A. " . That way his code can stay the same. And he wouldnt need a surrogate db on the new server.
select foo.id from databaseserver1.db1.dbo.table1 foo inner join databaseserver2.db1.dbo.table1 bar on foo.name = bar.name
That is still a code change - and you definitely need to consider permissions since you would be going from DB-1 to a view in DB-2 that is accessing a database across a linked server.
If the original view has all objects in the view schema qualified - then you could add a synonym and reference the synonym. The first step would be to add the synonym in DB-1 to reference the view in DB-2, then a code change to modify the code in DB-1 to use the synonym instead of 3-part naming to access the view.
Then - it is just a matter of recreating the synonym to use the linked server instead of the local database:
-- In DB-1 before adding linked server
CREATE SYNONYM dbo.View FOR db-2.dbo.View;
GO
-- In DB-1 after adding linked server
DROP SYNONYM IF EXISTS dbo.View;
CREATE SYNONYM dbo.View FOR linked_server.db-2.dbo.View;
GOThe code in DB-1 then just uses dbo.View.
But - this does require code changes. However, they should be very simple changes where you replace 3-part named objects with the 2-part synonym.
Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs -
thx jeffrey. i'd like to restate the problem so that i can follow what you are saying. and distinguish his code base changes from other changes.
server1 , db1 has dbo.view1.
server2, db2 has a select ? from db1.dbo.view1 in its code base. it also has a linked server called server1 with catalog db1 defined subordinate to the linked server.
what he is asking is if he creates an alias on server2 that translates "db1" to "server1.db1." could he avoid code base changes? i suspect between kerberos and a good userid choice, he could pull off the security challenge. but i wonder if a collision might occur between the created alias name and an already defined catalog name in the linked server. and an error might occur.
- stan wrote:
thx jeffrey. i'd like to restate the problem so that i can follow what you are saying. and distinguish his code base changes from other changes.
server1 , db1 has dbo.view1.
server2, db2 has a select ? from db1.dbo.view1 in its code base. it also has a linked server called server1 with catalog db1 defined subordinate to the linked server..
If you go with the surrogate database idea, create an empty db1 on server2, then create the synonym described above and you can reference it with the three part name. Similarly you could create view1 in the surrogate database, but point it to the linked server. I don't know which is preferable, but I assume you can't create both.
USE db1 -- on server2
GO
CREATE SYNONYM [dbo].[view1] FOR [server1].[db1].[dbo].[view1]
GO
CREATE VIEW dbo.view1 AS
SELECT * FROM server1.db1.dbo.view1
GO
USE db2
GO
SELECT TOP 10 *
FROM db1.dbo.view1 -
thx ed b. what if we forget about the surrogate db. and all we have is what shows below. can he avoid changes to his code base on db2?
server1 , db1 has dbo.view1.
server2, db2 has a select ? from db1.dbo.view1 in its code base. it also has a linked server called server1 with catalog db1 defined subordinate to the linked server..
-
If changing code is a no go, is adding code OK?
If so, you could set up a linked server from A to B and then set up a trigger on all tables involved in the stored procedure to push from server A to B then the stored procedure on B could be cross-database still, but wouldn't need to be cross-instance.
So on server B, you'd have 2 db's, db1 which would sync relevant data from server A's db1 to server B's db1, then server 2's db2's stored procedure could keep the 3 part naming, no synonym, you are just good to go.
Cons to this approach are that you will have delays in data modification on server A's db1 tables that have the triggers due to the trigger needing to complete before the query can complete. You also end up with data duplication, and if server B's db2's stored procedure changes data in db1, you'd also need to push that back to server A.
If you are OK with syncing but don't like the trigger approach, you could also set up service broker. Still uses triggers, but it is a lot more lightweight AND it is asynchronous and eventual consistency. What I mean is when service broker fires, it doesn't care on the state of your query and it doesn't block your query. It is also default low priority, so if it gets involved in a deadlock, it will always be the victim and, depending on your configuration, it can simply retry after failing.
Now, that being said, service broker is not the easiest thing to set up, but once it is up and running and configured properly, it's pretty stable. We set it up a few years back and initial setup was a pain in the butt, and finding the "gotcha's" of the system wasn't fun, but we got it sorted out pretty quick after go live and it ran flawlessly for years with minimal DBA intervention. Ours was retired earlier this year as we don't need it anymore, but it was fun while it lasted.
Just thinking of other options for this.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
You can create a 2 part synonym with the same table name as before that points to the linked server using 4 part naming. Zero code changes will be required.
However, no matter which method you use, you are going to suffer some inter-server performance issues (especially if JOINs are involved) because of the linked server. Instead of the synonym, you could try to mitigate that issue a bit by creating a view using the old table name but using OPENDATASOURCE so source the remote table .
You could also try REPLICATION. I say that in unqualified manner, though, because I've not had to work with any form of replication for literally 20 years. I don't know what, if any, changes there have been there over the last 2 decades.
I know there's probably nothing you can do to avoid the database split but I have to say it out loud anyway... I hope management where your friend works will be happy with the slowdown. What I recommend is telling your friend to setup a test and see if it actually works "good enough" before destroying what they currently have.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
thx jeff. we just learned synonyms dont work with (arent allowed on) linked servers. But something was bothering us and it goes like this...
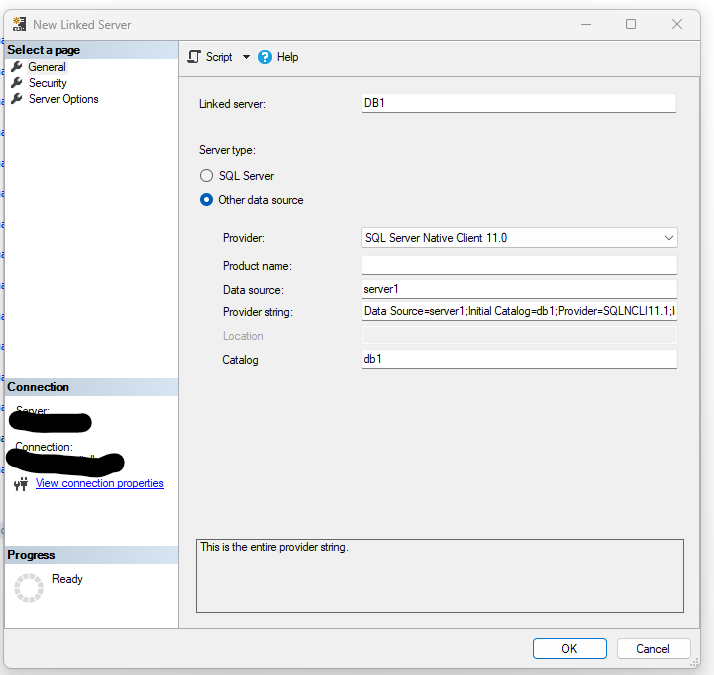
our theory (from other experiences) is that the name of a linked server need not be tied to the underlying server, db etc. so i tried adding a linked server as you see below. it seems (not sure) that the error i got has to do with insufficient privileges. we pinged our dba to see what he thinks. the theory is that this linked server's underlying plumbing points all the way to a db. so his select from db1.dbo.view1 might work. what do you think?

-
As this is a SQL2022 thread, you could also look at using Polybase and an external table.
As mentioned by @Mr Brian Gale, cross server queries in SQL Server, for an application, are an horrible idea. Replication or Service Broker would be better. If you really want cross server queries, I would be inclined to let the application server connect separately to both databases and do any 'joins' on the application server. This will help keep the load off the database servers and their expensive licenses.
-
thx Brian, Jeff, Ken. I'm reading the polybase thing now.
I didnt think it mattered but now i should mention that server2 is destined for 2022. Server1 is stuck on 2019 for reasons that werent explained to me but i suspect have to do with licensing, saving $ etc etc. so i dont know if that makes polybase a non starter. i am already wondering though if a synonym can be created that will be relevant to a polybase external table like they are on std tables, views etc.
does anybody have an opinion on the idea i illustrated where the linked server is named db1 and the underlying plumbing identifies a connection to server1 and db1?
-
Another reason why you may be stuck at 2019 on server1 is supported OS. I know my SQL instances are stuck on older versions due to the OS version, but we have plans to fix that soon.
My opinion, I'd highly recommend you change the code. My reasoning - kludgy solutions result in hard to support work. It is a case of technical debt that will come to bite you in the future. Plus, adding a linked server and then doing a search through the server2 DB for all calls to server1's DB and adding the linked server name is going to be a lot more helpful to future developers. If someone sees a call to db1.schema.table and they don't see db1 on the server, then they will be confused how things are working and it'll take time to figure out how it is working. It is MUCH nicer future developers (including future you) to do things the right way during transitions like this. Mind you, for cross server queries, I wouldn't use the 4 part naming - I'd use OPENQUERY.
Cross server queries are a performance suck. Best performance is to keep everything in 1 DB. If that is not possible, cross DB queries are fast. Cross server queries are ALMOST ALWAYS slower as they can't use statistics unless you use OPENQUERY. A good read up on cross server queries is available here - https://techcommunity.microsoft.com/t5/azure-database-support-blog/techniques-to-enhance-linked-server-performance/ba-p/1804527
In that blog post, you can see they compare performance and what you are doing is the first (ie slowest) example. Changing it to a remote join helped performance, but you can see that code changes to use OPENQUERY made things drastically faster. I've also found that at times for very large tables, it is MUCH faster to pull the data from the remote table into a temp table and use that in your query. Especially if you are reading from the table multiple times.
I encourage you to change the code so you don't go through all this work only to hurt performance badly, only mildly.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
thx Brian. This is really interesting. In the meantime we have proven that creating a linked server whose name is db1 but plumbing is server1.db1 does work with 0 code changes (change, new, remove) . I warned my friend about the likely performance hit.
- stan wrote:
thx jeff. we just learned synonyms dont work with (arent allowed on) linked servers.
How did you supposedly "learn" that they aren't allowed on linked servers? I ask because I don't recommend things that aren't working for me. I have many synonyms in many databases on many servers that point at a linked server by name.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 15 posts - 1 through 15 (of 22 total)
You must be logged in to reply to this topic. Login to reply