

At Microsoft Ignite, one of the announcements was for Azure SQL Database Hyperscale, which was made available in public preview October 1st, 2018 in 12 different Azure regions. SQL Database Hyperscale is a new SQL-based and highly scalable service tier for single databases that adapts on-demand to your workload’s needs. With SQL Database Hyperscale, databases can quickly auto-scale up to 100TB, eliminating the need to pre-provision storage resources, and significantly expanding the potential for app growth without being limited by storage size. Check out the documentation.
Compared to current Azure SQL Database service tiers, Hyperscale provides the following additional capabilities:
- Support for up to a 100 TB of database size
- Nearly instantaneous database backups (based on file snapshots stored in Azure Blob storage) regardless of size with no IO impact on Compute
- Fast database restores (based on file snapshots) in minutes rather than hours or days (not a size of data operation)
- Higher overall performance due to higher log throughput and faster transaction commit times regardless of data volumes
- Rapid scale out – you can provision one or more read-only nodes for offloading your read workload and for use as hot-standbys
- Rapid Scale up – you can, in constant time, scale up your compute resources to accommodate heavy workloads as and when needed, and then scale the compute resources back down when not needed
The Hyperscale service tier removes many of the practical limits traditionally seen in cloud databases. Where most other databases are limited by the resources available in a single node, databases in the Hyperscale service tier have no such limits. With its flexible storage architecture, storage grows as needed. In fact, Hyperscale databases aren’t created with a defined max size. A Hyperscale database grows as needed – and you are billed only for the capacity you use. Storage is dynamically allocated between 5 GB and 100 TB, in 1 GB increments. For read-intensive workloads, the Hyperscale service tier provides rapid scale-out by provisioning additional read replicas as needed for offloading read workloads.
The Hyperscale service tier is primarily intended for customers who have large databases either on-premises and want to modernize their applications by moving to the cloud or for customers who are already in the cloud and are limited by the maximum database size restrictions (1-4 TB). It is also intended for customers who seek high performance and high scalability for storage and compute.
The Hyperscale service tier supports all SQL Server workloads, but it is primarily optimized for OLTP. The Hyperscale service tier also supports hybrid and analytical (data mart) workloads.
It is available under the vCore-based purchasing options for SQL Database (it is not available yet for SQL Database Managed Instance).
Azure SQL Database Hyperscale is built based on a new cloud-born architecture which decouples compute, log and storage.
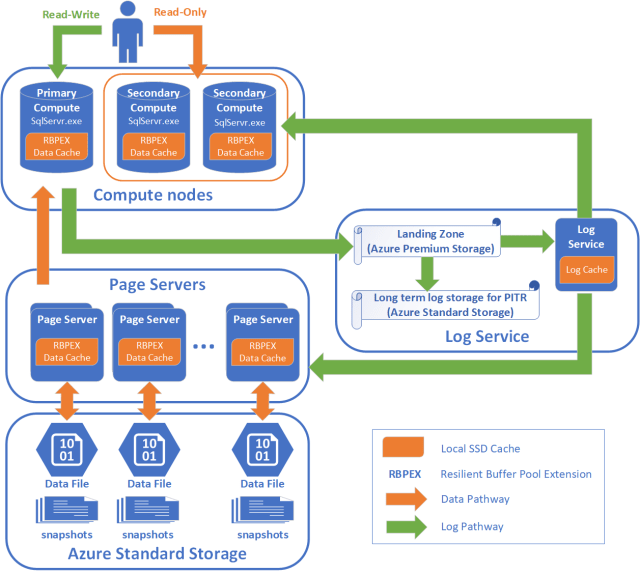
A Hyperscale database contains the following different types of nodes:
Compute nodes
The compute nodes look like a traditional SQL Server, but without local data files or log files. The compute node is where the relational engine lives, so all the language elements, query processing, and so on, occur here. All user interactions with a Hyperscale database happen through these compute nodes. Compute nodes have SSD-based caches (labeled RBPEX – Resilient Buffer Pool Extension in the preceding diagram) to minimize the number of network round trips required to fetch a page of data. There is one primary compute node where all the read-write workloads and transactions are processed. There are one or more secondary compute nodes that act as hot standby nodes for failover purposes, as well as act as read-only compute nodes for offloading read workloads (if this functionality is desired).
Log service
The log service externalizes the transactional log from a Hyperscale database. The log service node accepts log records from the primary compute node, persists them in a durable log cache, and forwards the log records to the rest of the compute nodes (so they can update their caches) as well as the relevant page server(s), so that the data can be updated there. In this way, all data changes from the primary compute node are propagated through the log service to all the secondary compute nodes and page servers. Finally, the log record(s) are pushed out to long-term storage in Azure Standard Storage, which is an infinite storage repository. This mechanism removes the necessity for frequent log truncation. The log service also has local cache to speed up access, so you have end-to-end log latencies in the 2ms range. When the Azure Ultra SSD storage technology becomes available, this latency will shrink to around 0.4ms for remote, fully durable and resilient data storage.
Page servers
The page servers host and maintain the data files. It consumes the log stream from the log services and applies the data modifications described in the log stream to data files. Read requests of data pages that are not found in the compute’s local data cache or RBPEX are sent over the network to the page servers that own the pages. In page servers, the data files are persisted in Azure Storage and are heavily cached through RBPEX (SSD-based caches).
Page servers are systems representing a scaled-out storage engine. Multiple page servers will be created for a large database. When the database is growing and available space in existing page servers is lower than a threshold, a new page server is automatically added to the database. Since page servers are working independently, it allows us to grow the database with no local resource constraints. Each page server is responsible for a subset of the pages in the database. Nominally, each page server controls one terabyte of data. No data is shared on more than one page server (outside of replicas that are kept for redundancy and availability). The job of a page server is to serve database pages out to the compute nodes on demand, and to keep the pages updated as transactions update data. Page servers are kept up-to-date by playing log records from the log service. Long-term storage of data pages is kept in Azure Standard Storage for additional reliability.
Azure standard storage node
The Azure storage node is the final destination of data from page servers. This storage is used for backup purposes as well as for replication between Azure regions. Backups consist of snapshots of data files. Restore operation are fast from these snapshots and data can be restored to any point in time.
Automated backup and point in time restore
In a Hyperscale database, snapshots of the data files are taken from the page servers periodically to replace the traditional streaming backup. This allows for a backup of a very large database in just a few seconds. Together with the log records stored in the log service, you can restore the database to any point in time during retention (7 days in public preview and will be configurable up to 35 days at general availability) in a very short time, regardless of the database size (a 50TB database takes just 8 minutes to restore!).
Since the backups are file-snapshot base and hence they are nearly instantaneous. Storage and compute separation enable pushing down the backup/restore operation to the storage layer to reduce the processing burden on the primary compute node. As a result, the backup of a large database does not impact the performance of the primary compute node. Similarly, restores are done by copying the file snapshot and as such are not a size of data operation. For restores within the same storage account, the restore operation is fast.
Highly Available Components
Each of the components in the Azure SQL Database Hyperscale architecture is designed to be highly available so that there will be no interruptions in database access:
- Compute nodes each have at least one replica running and hot at all times. In the event of a compute node failure or failover, the replica would immediately take over the Primary role, keeping the database online and available. A replacement replica can be started up very quickly, and can warm up its caches as a background task without impacting production performance. Other replicas may be configured for read scale-out purposes. With this architecture, the compute nodes are effectively stateless
- Page servers each have a standby replica online with their RBPEX cache fully populated, so they’re available to take over for the active page server in the event of failure. Again, because they’re stateless outside of cached data, a replacement can be online very quickly, without any risk of data loss
- The log service doesn’t have a hot standby, but this is unnecessary as the log service has no cached data and can be replaced as quickly as you could failover to a standby replica. The data that’s managed by the log service resides first in the landing zone, which is resilient Azure Premium Storage (soon Ultra SSD storage), and is ultimately persisted in Azure Standard storage for long-term retention
So, as you can see, there’s no component that represents a single point of failure. All Hyperscale components have active standbys, with the exception of the log service, and all data is backed by fully resilient Azure storage.
More info:
Video New performance and scale enhancements for Azure SQL Database
Introducing Azure SQL Database Hyperscale

![]()
