View generating different plan
-
Hello
I have a view based upon a number of tables
I'm selecting the same data from this view on 3 identical servers (same memory, processors, tempdb, settings etc.)
The amount of data is nearly the same - Same on most dimensional tables; 10's of thousand out of millions of the fact (so < .5%)
On one of the servers, it generates a good plan and runs in seconds
On one specific table it uses an Index seek for around 1 million rows
On two of them it generates a very bad plan and runs indefinitely
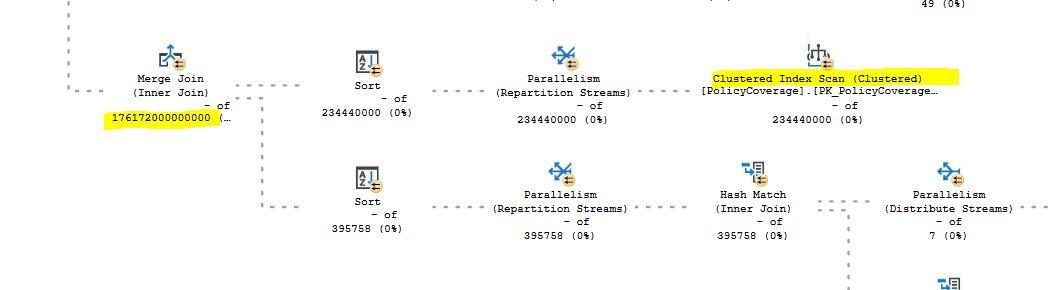
On the same table it uses generates a clustered index scan across around 200Million rows
There are no differences between the indexes on that table
Stats and fragmentation looks good
One generates joins that say approx 1M out of 2M
The bad plan returns estimates on a number of operations in excess of of 175,000,000,000,000
So widely out!
I'm just wondering what else could cause this
Thanks
- Damian
-
When is the last time you updated the statistics on these tables?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
I've tried, Jeff
It runs daily so it's fairly easy to just run an update statistics on all the tables involved
No impact i'm afraid
- Damian
-
Possibly a silly question but are the plans exactly the same apart from the estimates? What I mean is are you getting the same seeks and scans across all systems, just estimates are vastly different between the 3 systems.
If so, my next thought is that you say the data is ALMOST the same. Changes in data can result in different plans depending on the query and the view. And is the VIEW identical between the three systems AND does the view rely on any tables external to the database (via linked server or cross database calls)? Just trying to think of all the places where problems MAY come in.
And probably a silly question, but all 3 instances are at the same patch levels for the OS and SQL Server, right? Just want to make sure you are comparing apples to apples.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
Thanks Brian
Yes, all same patch levels, the view is identical and there are no cross database or linked server joins used
The plans are different
The good plan uses an index seek and estimates are reasonable (as it filters)
The bad plan uses a Clustered index scan and estimates start to go a bit crazy (this is a live estimate that I stopped so no % progress)

- Damian
-
Have you tried simply clearing proc cache for the database and then running the identical query on both systems? I ask because this is starting to smell like a simple case of "bad parameter sniffing" on the slower of the two machines. You might think that running the stats rebuild job you have might fix this but it may be that the particular stats required might not have been rebuilt and so a parameter sniffing problem could be left behind.
Also, the first image above is an execution plan... the second image is a run-time stats plan. Just to remove one more possible analysis difference, I'd stick with just one or the other.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Thanks Jeff
As it stands stats updated and indexes rebuilt
Also, proc cache cleared
It now runs through but still creates a different plan (same as before) with huge estimates
- Damian
-
At this point, I'd check to make sure that the code for the 3 views, the datatypes for the underlying tables, and the actual data in the tables matched on all 3.
I especially say that because of the "175,000,000,000,000" number you posted. Looks like a massive accidental many-to-many join a.k.a. a CROSS JOIN or a Triangular Join.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Can you show us the query?

Viewing 9 posts - 1 through 9 (of 9 total)
You must be logged in to reply to this topic. Login to reply