

In today's era of hybrid data ecosystems, organizations often find themselves straddling multiple data platforms for optimal performance and functionality. If your organization utilizes both Snowflake and Microsoft data stack, you might encounter the need to seamlessly transfer data from Snowflake Data Warehouse to Azure Lakehouse.
Fear not! This blog post will walk you through the detailed step-by-step process of achieving this data integration seamlessly.
As an example, the below Fig:1 shows a Customer table in the Snowflake Data warehouse.
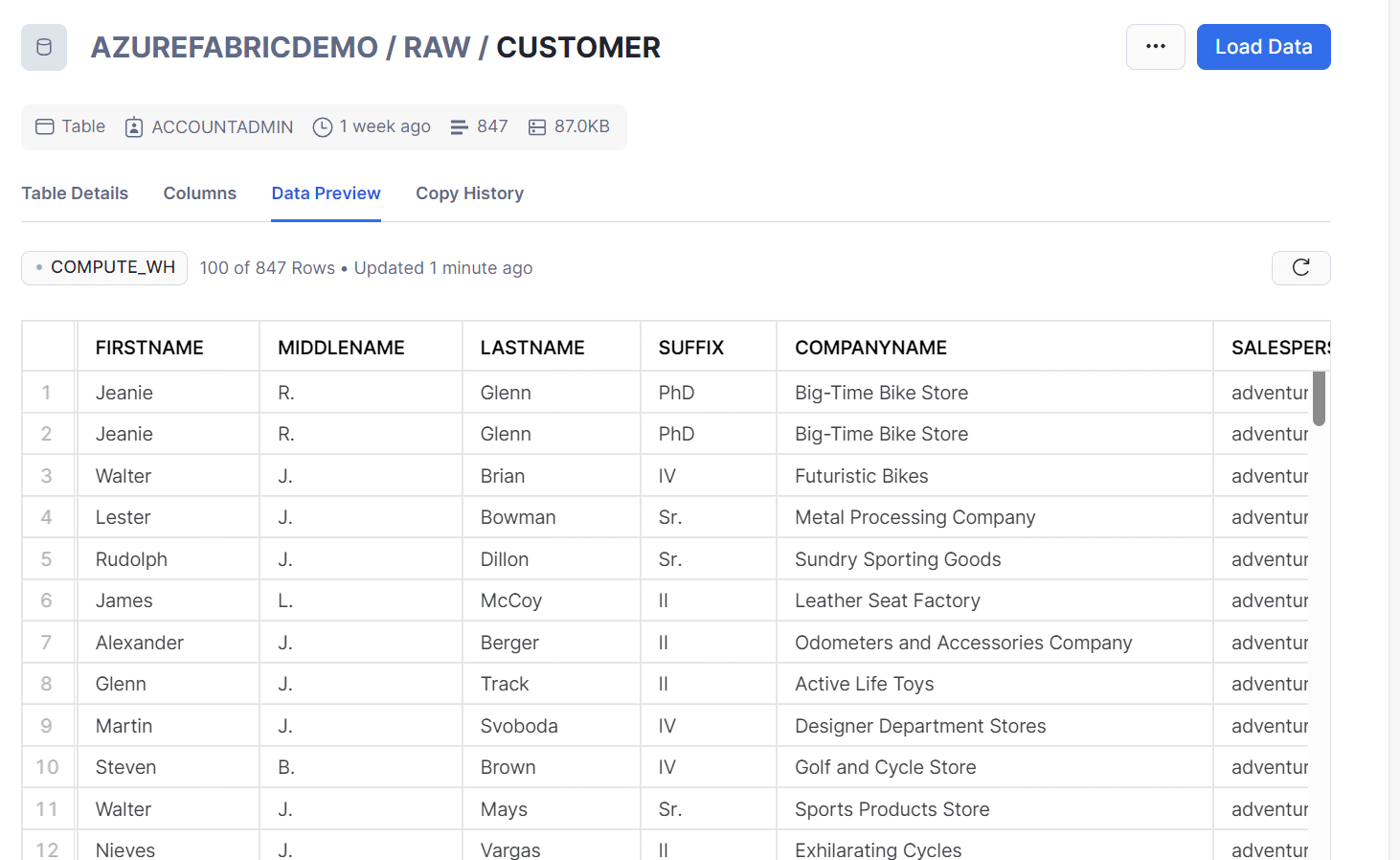
Fig 1: Customer data in the Snowflake data warehouse
To get this data from Snowflake to Azure Data Lakehouse we can use cloud ETL tool like Azure Data Factory (ADF), Azure Synapse Analytics or Microsoft Fabric. For this blog post, I have used Azure Synapse Analytics to extract the data from Snowflakes. There are two main activities involved from Azure Synapse Analytics:
- Creating a Linked Service
- Creating a data pipeline with Copy activity
Activity A: Creating a Linked Service
In the Azure Synapse Analytics ETL tool you need to create a Linked Service (LS), this makes sure connectivity between Snowflake and Azure Synapse Analytics. Please find the steps to create Linked Service:
Step 1) Azure Synapse got built in connector for Snowflake, Please click new Linked service and search the connector "Snowflake" and click next as shown in Fig 2 below
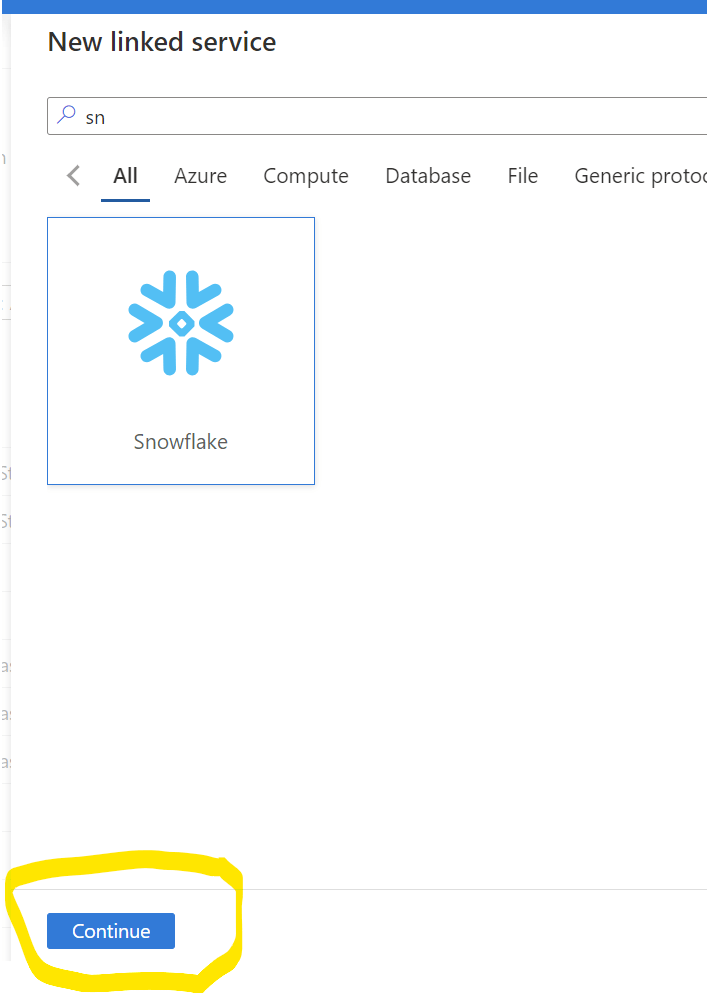
Fig 2: Built in connector Snowflake
Step 2) Make sure to fill all the necessary information. The details are described below for each section.

Fig 3: Linked service details
- a) Linked service name: Please put the name of the Linked service
- b) Linked service description: Provide the description of the Linked service.
- c) Integration runtime: Integration runtime is required for Linked service, Integration Runtime (IR) is the compute infrastructure used by Azure Data Factory and Azure Synapse pipelines. You will find more information under Microsoft learn page.
- d) Account name: This is the full name of your Snowflake account, to find this information in Snowflake you need to go to Admin->Accounts and find out the LOCATOR as shown in figure 4.
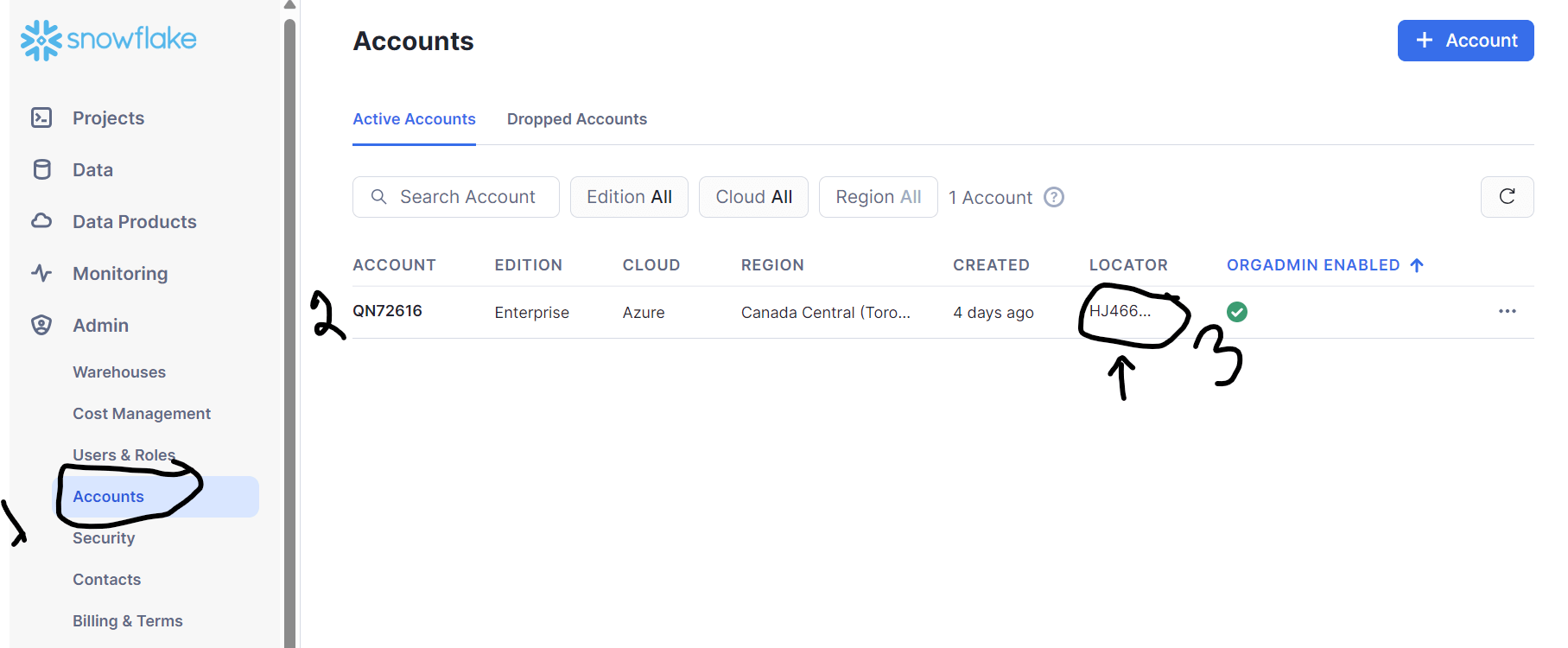
Fig 4: Snowflake account name
If you hover over the LOCATOR information, you will find the URL as shown in fig 5.
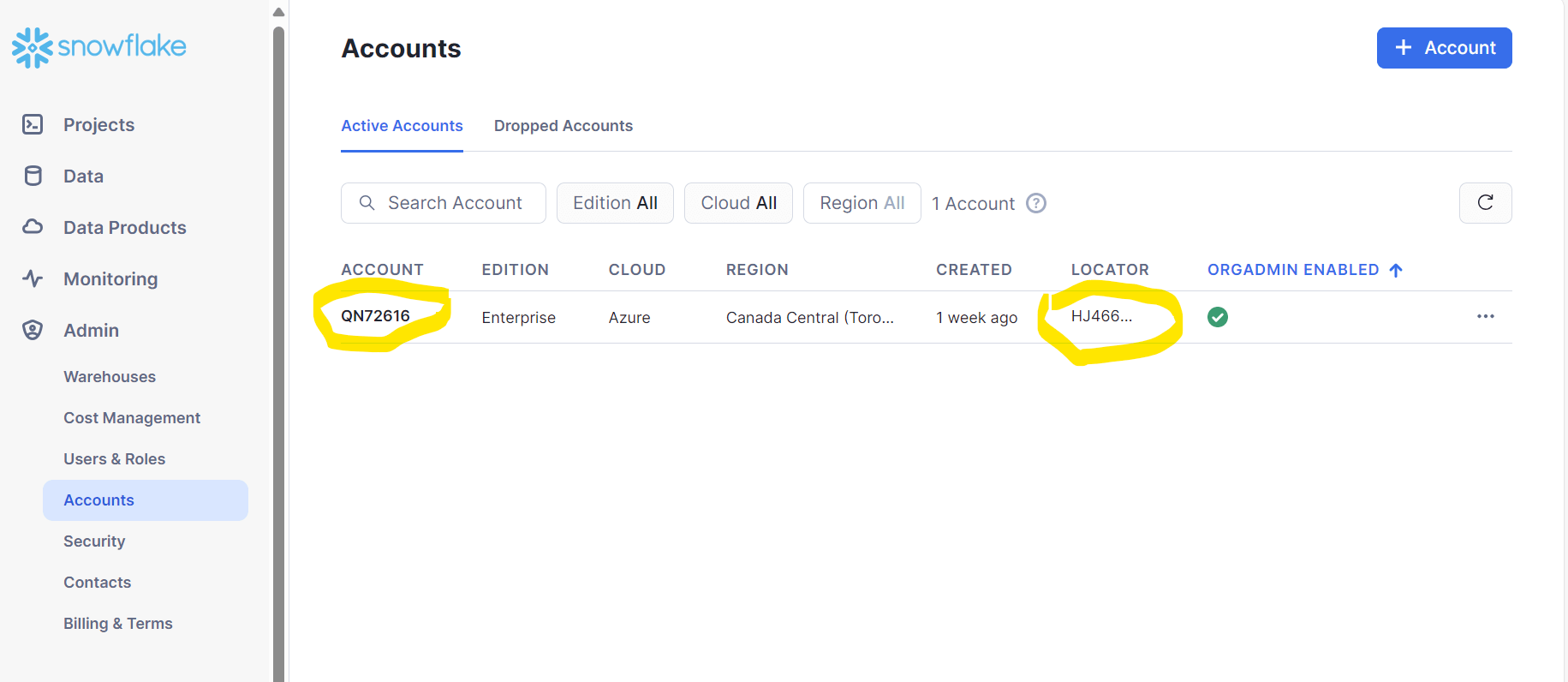
Fig 5: Snowflake account URL
Please don't use full URL for the Account name in Linked Service. Keep the value until https://hj46643.canada-central.azure (in this example.
- e) Database: Please find the database name from Snowflake, go to Databases->{choose the right Database} as shown in Fig 6
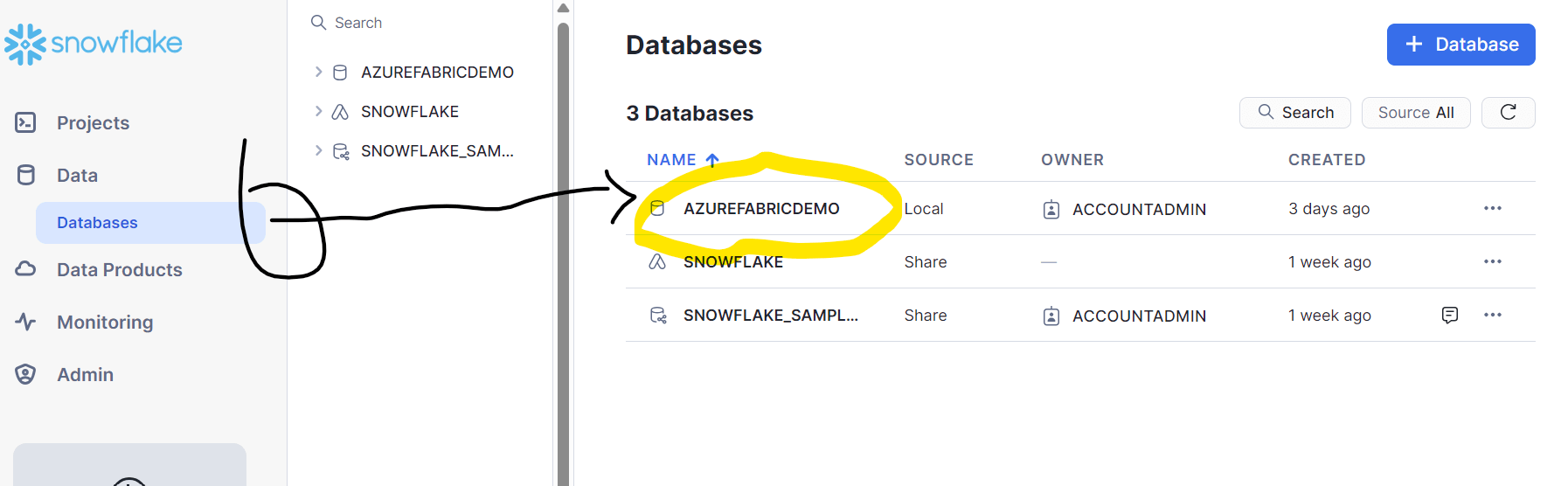
Fig 6: Snowflake Database
A Snowflake database is nothing but storage. In general ,MS SQL databases, ORACLE or Teradata have their compute and storage together and this is called a database. However, in Snowflake, the sorage is called the database and the compute is their Virtual Data Warehouse.
- f) Warehouse: In Snowflake, you have warehouse in addition to the database. Please go to Admin->Warehouses->{choose your warehouse} as shown in fig 7. We have used the warehouse: AZUREFABRICDEMO
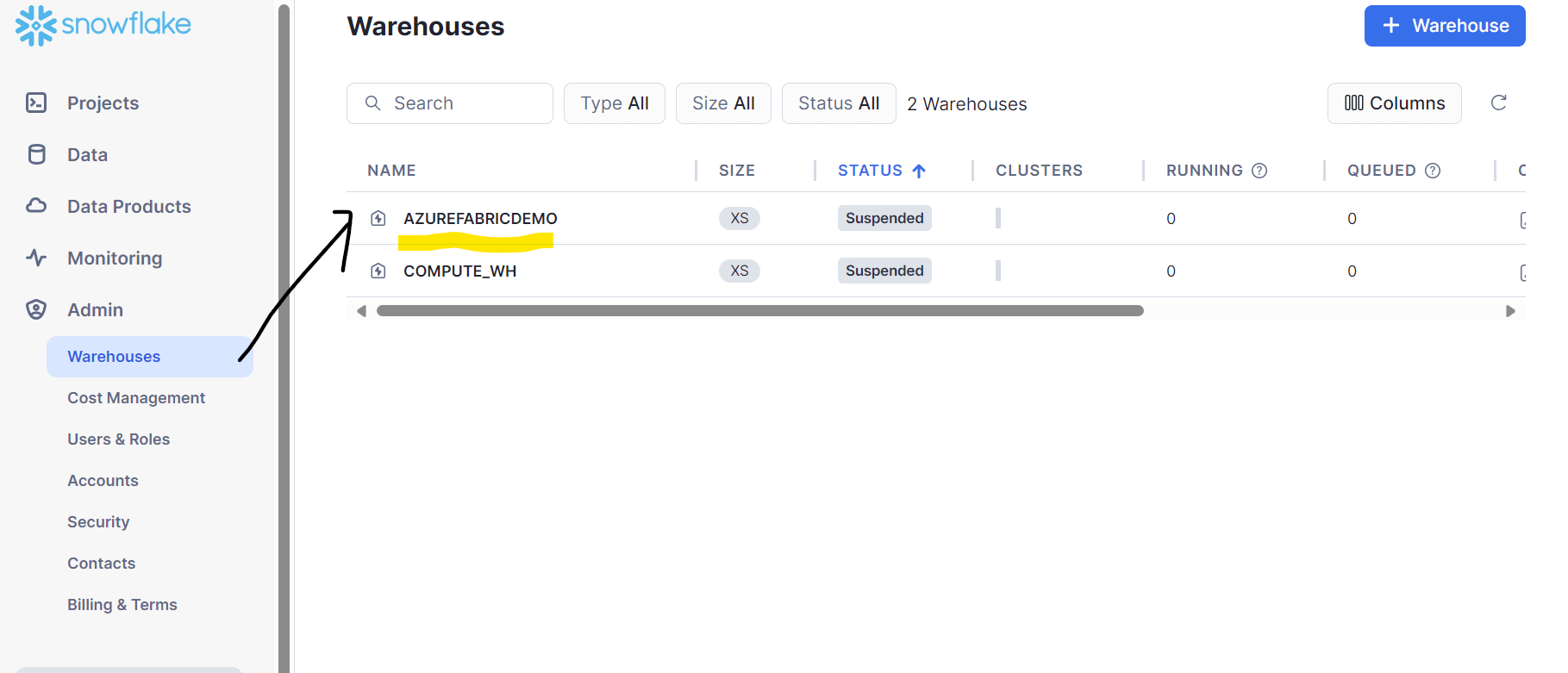
Fig 7: Virtual Warehouse in Snowflake
- g) User name: User name of your Snowflake account
- h) Password: Password of your Snowflake account
- i) Role: Default role is PUBLIC, if you don't use any other role it will pick PUBLIC. I did not put any specific role so kept this field empty.
- j) Test connection: Now you can test the connection before you save it.
- k) Apply: If the earlier step "Test connection" is successful, please save the Linked service by clicking apply button.
Creating a Data Pipeline with a Copy Activity
This activity includes connecting the source Snowflake and copying the data to the destination Azure data Lakehouse. The activity includes following steps:
- Synapse Data pipeline
- Source side of the Copy activity needs to connect with the Snowflake
- Sink side of the Copy activity needs to connect with the Azure Data Lakehouse
Each of these steps is described below.
Create a Synapse Data pipeline
From the Azure Synapse Analytics, create a pipeline as shown Fig 8
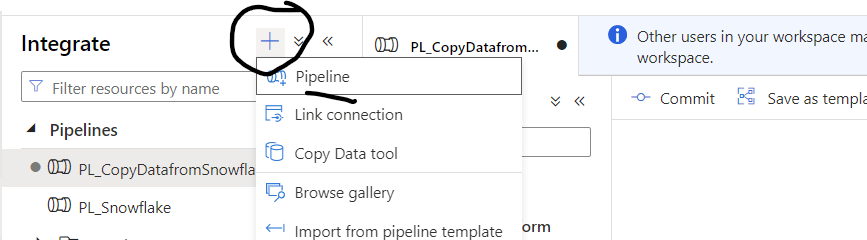
Fig 8: Create a pipeline from Azure Synapse Analytics
Then drag and drop Copy activity from the canvas as shown in Fig 9, You will find Copy activity has both a source and a sink.
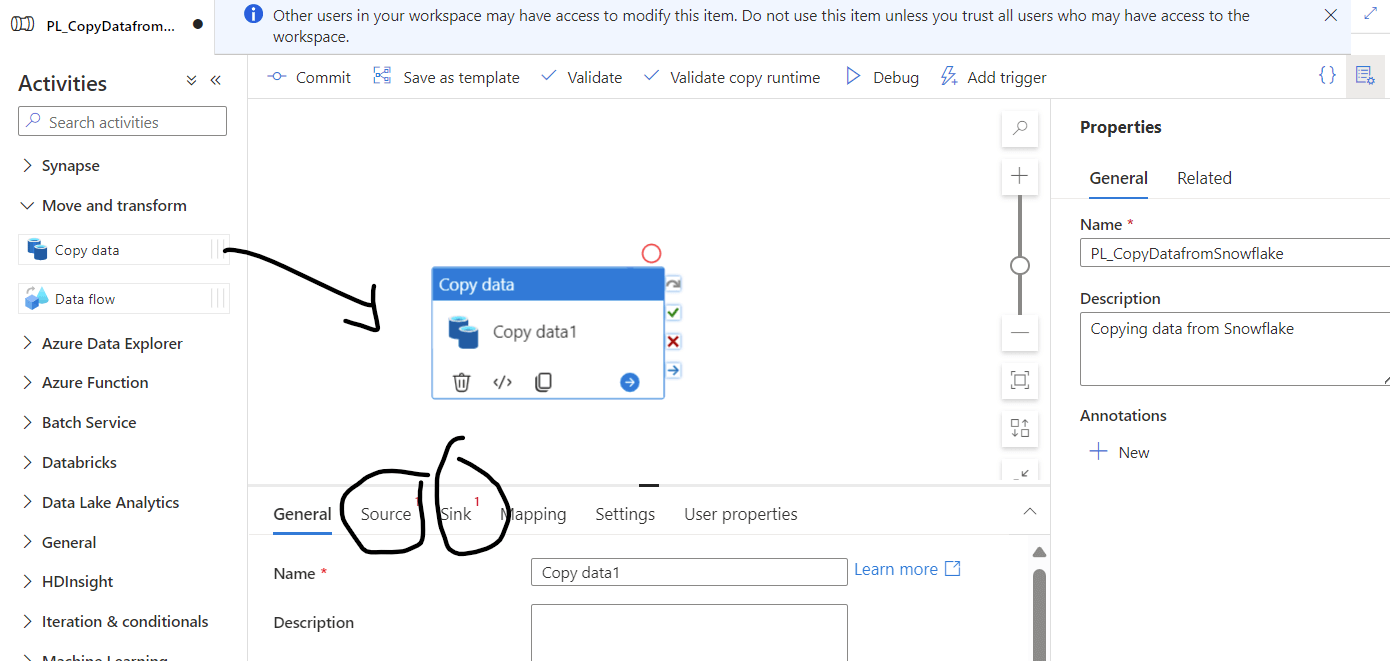
Fig 9: Copy Activity
The Source side of the Copy activity needs to connect with the Snowflake
The Source side of the Copy activity needs to connect with the Snowflake Linked service that we created under the Activity A: Creating Linked service. To connect Snowflake from Synapse pipeline, first choose "Source" and then click "New" as shown in below fig 10
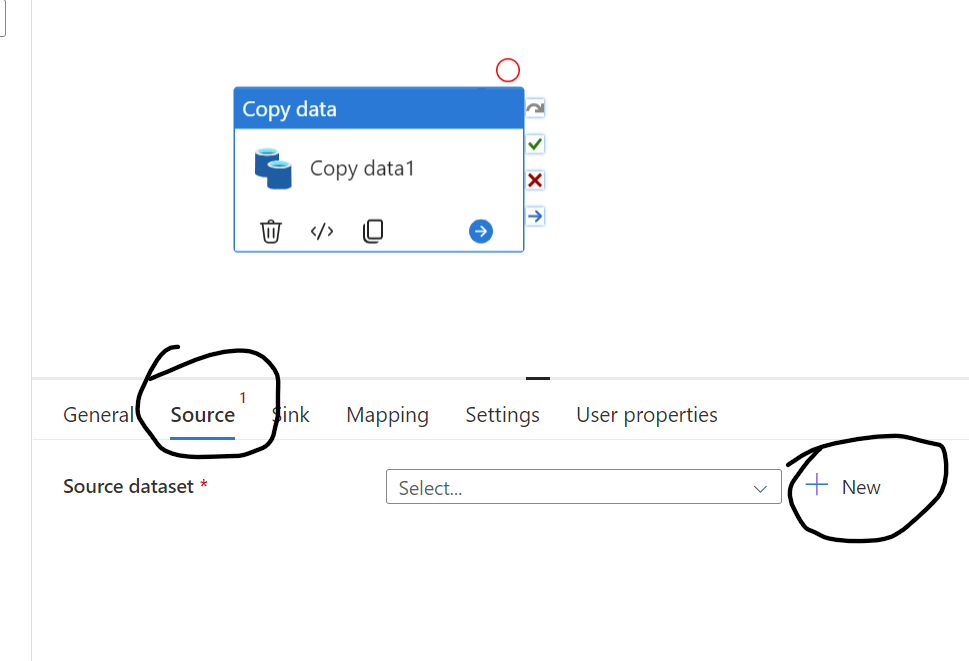
fig 10: Source dataset (step 1)
The next step is to choose Snowflake as shown in below fig 11

Fig 11: Source dataset with Snowflake (step 2)
After choosing the above integration dataset, you will find another UI which you need to fill up as shown in fig 12
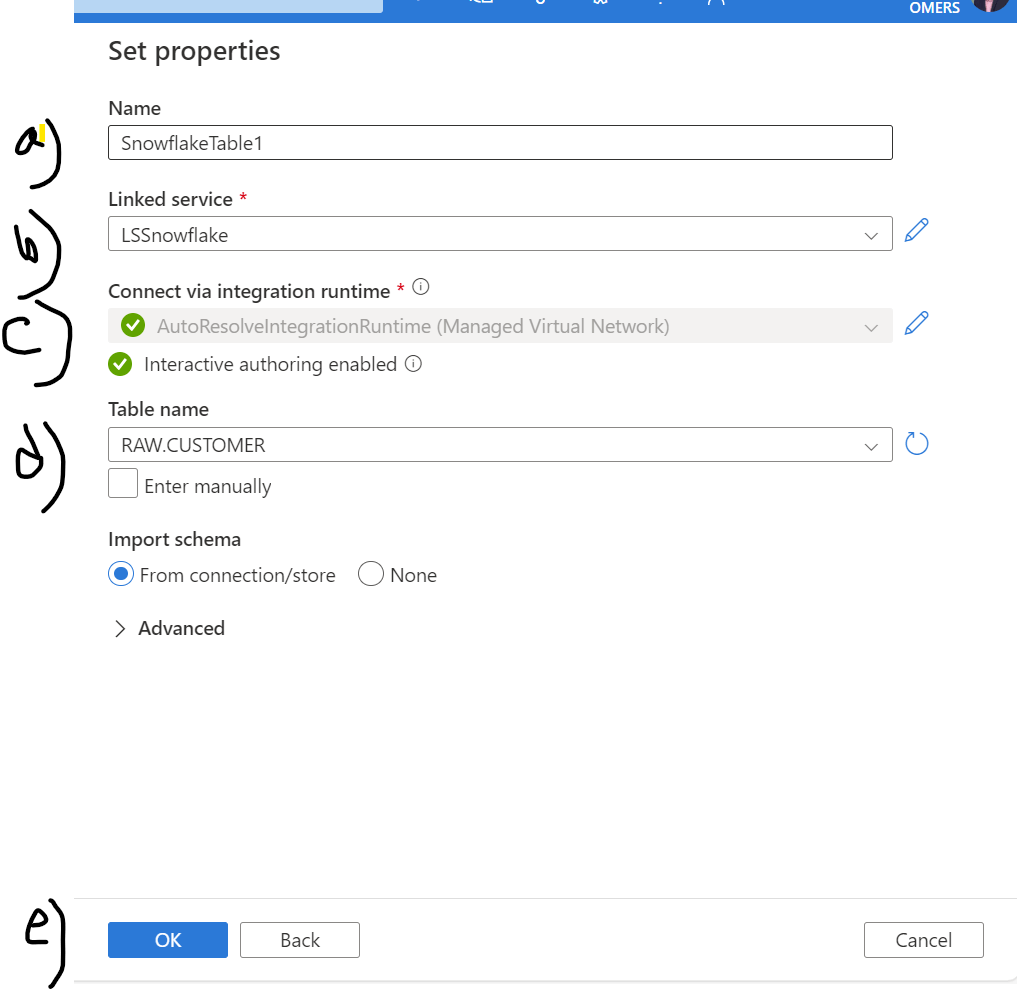
Fig 12: Source dataset details
Each value is described below:
- a)Name: Provide a dataset name
- b)Linked service: Please choose the Linked service which we already created under the Activity A
- c)Connect via Integration runtime: Choose the very same Integration runtime you used at the Activity A.
- d)Table name: Now you should able to find all the table from Snowflake, so choose the right table you want to get data from.
- e) Click 'Ok' to complete the source dataset.
Connect the Sink side of the Copy Activity
At this point, we need to connect the sink side of the copy activity, fig 13 shows how to start with sink dataset.
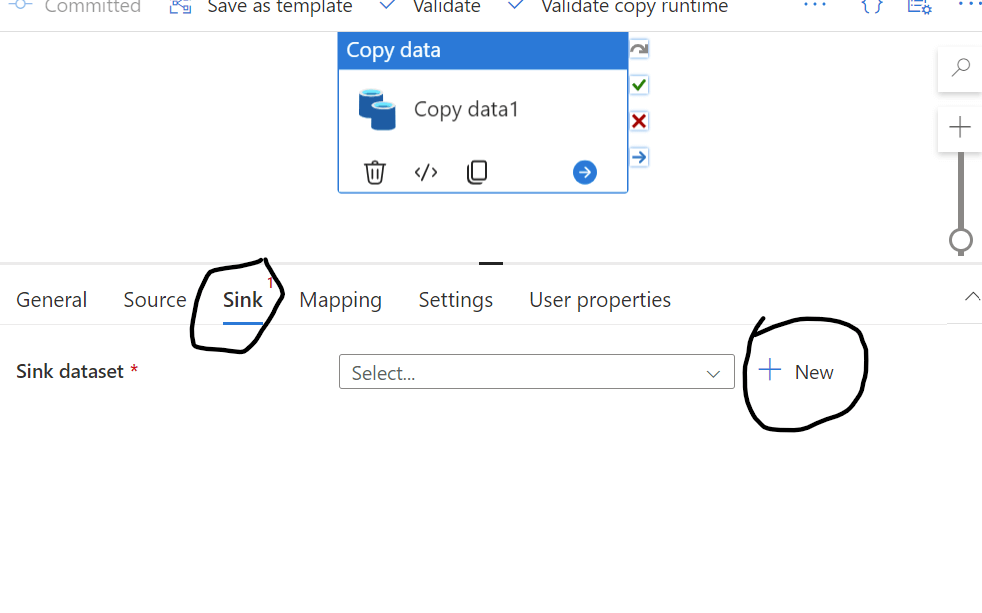
Fig 13: creating sink dataset
Then fill up the details to create Sink dataset as shown in the below fig 14
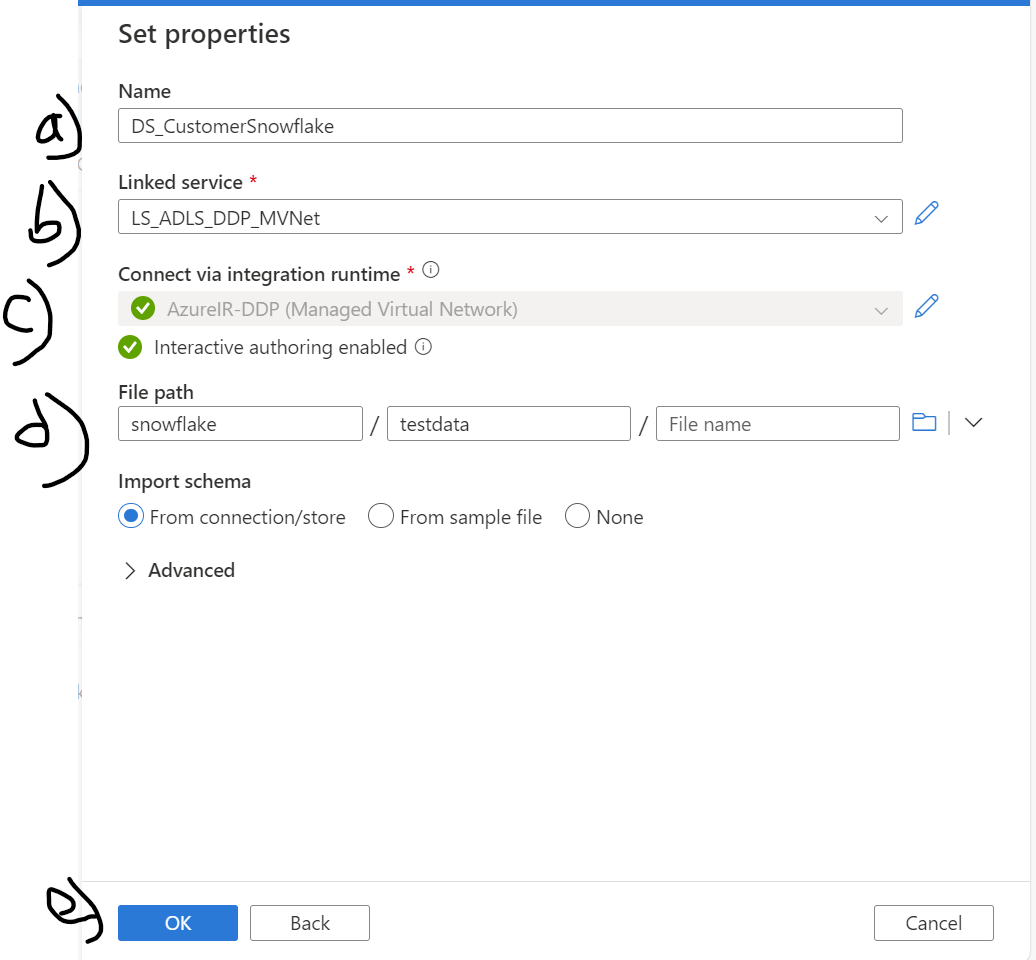
fig 14: Sink dataset properties
Each value is described below:
- a) Name: Provide a dataset name
- b) Linked service: Please choose the Linked service which we already created under the Activity A
- c) Connect via Integration runtime: Choose the very same Integration runtime you used at the Activity A.
- d) File Path:Now you need to choose the file path in Azure Data Storage account. I have already created a storage account, container and sub directory. The file path is: snowflake/testdata
- e) Click 'Ok' to complete the source dataset.
The Synapse pipeline is completed. However, before executing the pipeline, need to check if there is any error in the code. To check it, please click 'validate'. When I did the validation found the below error as shown in fig 15
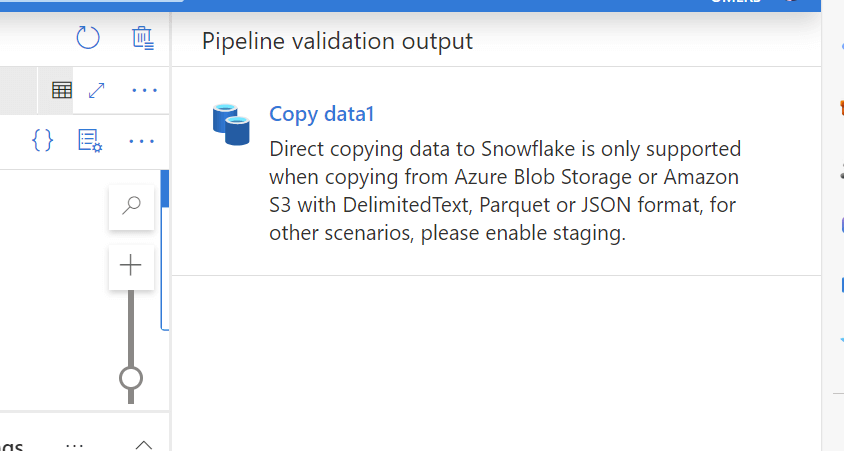
Fig 15: staging error
The error is self explanatory, since we are copying directly from Snowflake data warehouse, we must need to enable staging in the pipeline.
To enable staging, at first click on settings of the pipeline, then enable the staging and connect a Linked service that connect a storage as shown in the below fig 16.
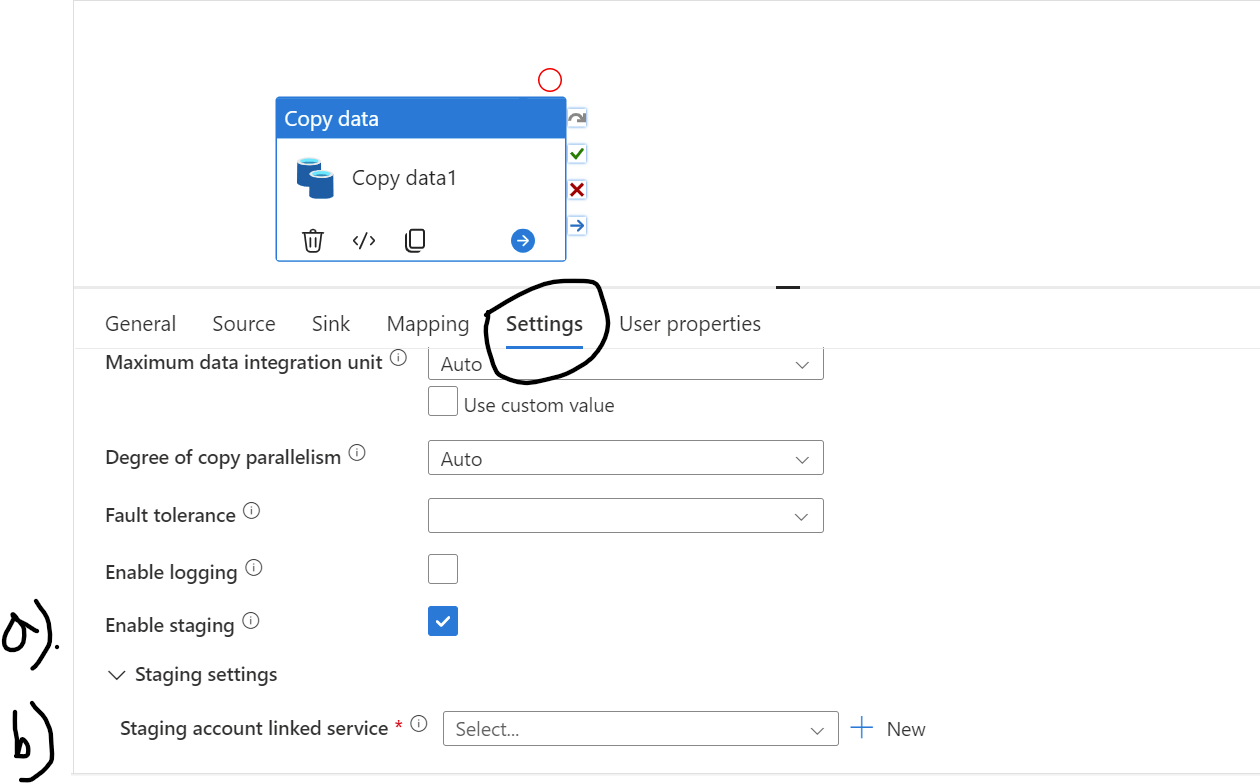
Fig 16: Enable staging in the Copy pipeline
When you are connecting the blob storage for the staging please make sure it's not ADLS storage account and must need to choose Authentication type SAS URI.
After fixing the error when execute it again, the pipeline moved the data from Snowflake data warehouse to Azure data lake storge. You will find a .parquet file created as shown below fig 17
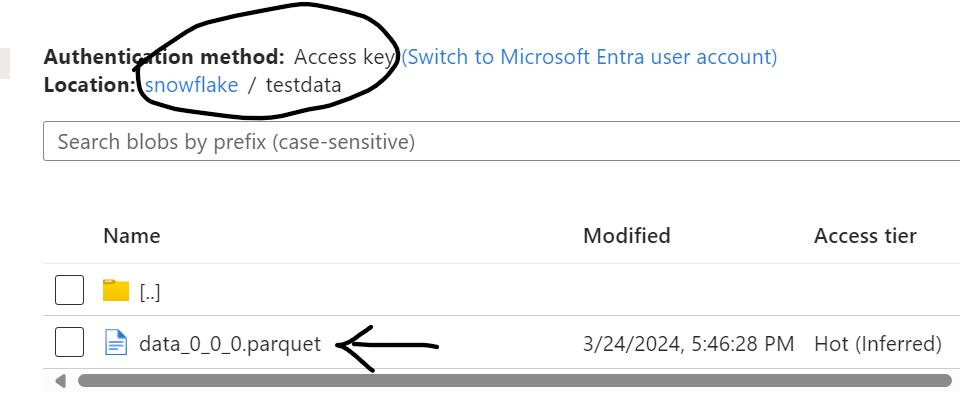
fig 18: Parquet file in Azure Data Lake
And finally, you can view the data by using notebook as shown in fig 18.
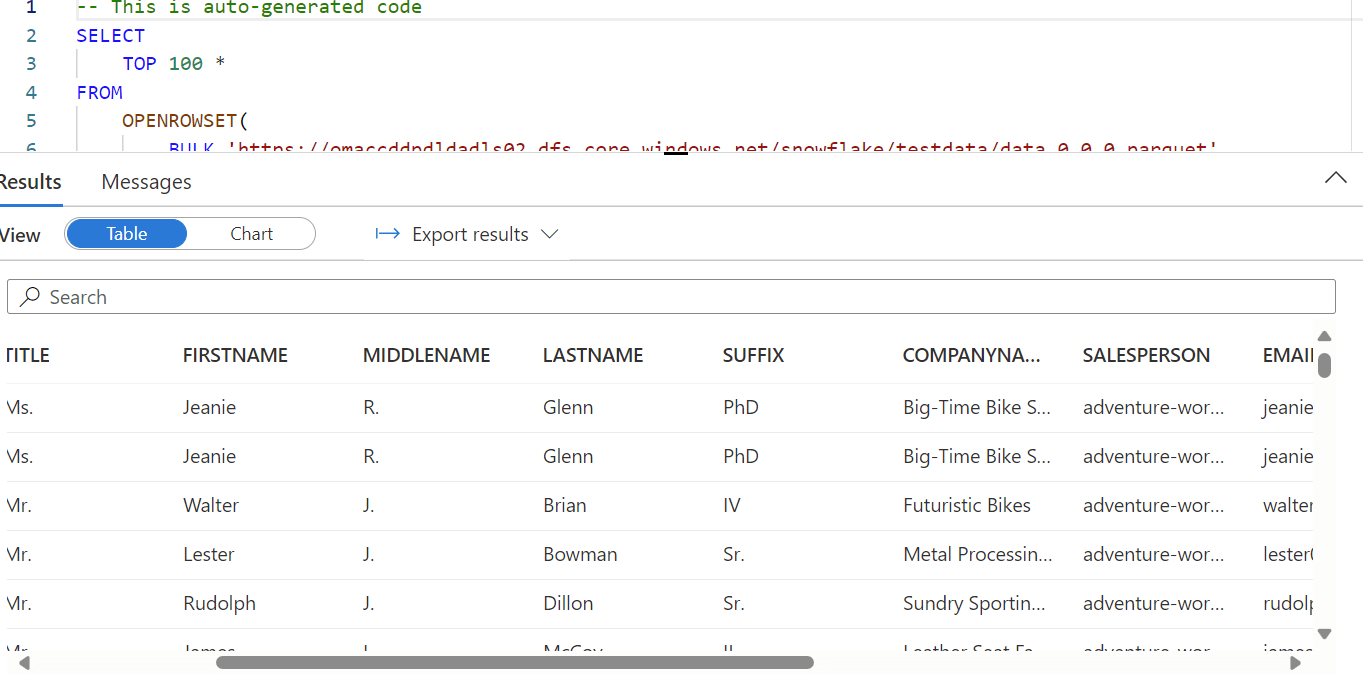
fig 18: Data from Azure Data Lake
The article shared how you can copy data from Snowflake Data warehouse to Azure Data Lake by using Azure Synapse Analytics. The same can be achieved through Azure Data Factory (ADF) as well as Microsoft Fabric.
