Query wont use any index - Cannot understand why
-
Hello,
I am new to the forum. I am using MSSQL at work. Quick information what we do, later what is the problem. Basically we are moving SAP systems(tables are moved) to MSSQL server. I have few very big tables, and WHERE clause, which for some reason does not use any of the indexes I tried creating. I am not expert on how the indexes are used so when I create them i kind of hoping they work, but here are few important facts that's need to be considered:
- In this particular case, the data wont be changed(Will stay static, no adding more data, no deletion, no changes of any kind), so I except much less fragmentation of the indexes.
- The data will be read using same Queries every time with a small exception where from time to time under "where clause" there will be changes. In this specific case the where clause remains the same. JOINS won't change
- Here is the whole Statement, I have indexes for the join which are partially used while the query runs, but for the WHERE clause, i have 4-5 different type of indexes, one big, few small, mix between big and small, and always uses only the indexes for the join, never the ones for "Where clause" and I am starting thinking, that I am doing something wrong here, or I don't understand how Indexes are structured and when the statement read them.
- I use "Count" but later on there will be normal select with fields.
SELECT COUNT (*)
FROM
BSEG I
LEFT OUTER JOIN
BKPF H ON (H.MANDT = I.MANDT AND H.BUKRS = I.BUKRS AND H.GJAHR = I.GJAHR AND H.BELNR = I.BELNR)
WHERE
(NOT (I.AUGBL = '')
AND NOT (I.AWTYP = 'GLYEC')
AND ((I.KOART = 'D' AND I.XHRES = 'X')
OR (I.KOART = 'K' AND I.XHRES = 'X')
OR (I.KOART = 'A' AND I.XHRES = 'X')
OR (I.KOART = 'M' AND I.XKRES = 'X')
OR (I.KOART = 'S' AND I.XKRES = 'X' AND I.XLGCLR = '')))
AND NOT (I.H_BSTAT = 'D')
AND NOT (I.H_BSTAT = 'M')- The row count on BSEG is: 64800853 and it's 84 544,398 MB and BSEG has 339387118 rows and it's 1 325 324,695 MB
- The server parameters are not problem, i have 256GB of RAM, 1,3TB Tempdb and 14 CPU cores.
- My understanding how the indexes are working is that, when I have in the JOIN the following columns: MANDT, BUKRS, GJAHR and BELNR, my index should have the same columns, and more importantly the same order in the index. That goes for all tables included in the join, in this case BKPF and BSEG should have indexes with the same column order.
- Next thing, to make sure the query is quicker also is good to have indexes for WHERE clause, same principle, the order of fields in the where clause and the order of fields in the index should be the same. Is that even correct?
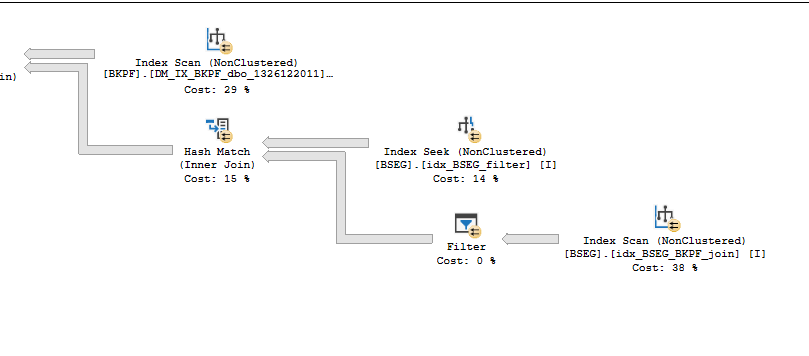
- Here i have few indexes in BSEG, and yet the query does not read a single one of them. BKPF index is used.

- Also i have index for the columns in WHERE clause - this is not used as well.
Can someone give tips, what might be the problem?
-
BSEG is a heap - why don't you have a Clustered index on it?
and reason for not using any of the other indexes may also be related to not having the correct clustered index - as well as not having a index on BSEG that covers the filtering criteria as well as the columns that are part of the select and the join to the other table.
so the SQL Engine decided that it is more cost effective to do a table (HEAP) scan than to do a index scan/seek followed by a row lookup to the HEAP to get the remaining required data.
-
We would need DDL for the tables and some cardinality info (how many rows for each condition).
But, overall, IF that is a consistent query pattern, you should cluster the table by / starting with:
( LXHRES, KOART )
IF those columns are char(1) (or varchar(1)), this would make sense.
IF I.XLGCLR is char(1), you might want to add it to the end of the keys.
IF you can an identity, or other short unique column value, add it to the end of the key to make it unique.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
You can simplify the query to this:
SELECT COUNT(*)
FROM BSEG I
LEFT JOIN BKPF H
ON H.MANDT = I.MANDT
AND H.BUKRS = I.BUKRS
AND H.GJAHR = I.GJAHR
AND H.BELNR = I.BELNR
WHERE I.AUGBL <> ''
AND I.AWTYP <> 'GLYEC'
AND (
(I.KOART IN ('D', 'K', 'A') AND I.XHRES = 'X')
OR (I.KOART = 'M' AND I.XKRES = 'X')
OR (I.KOART = 'S' AND I.XKRES = 'X' AND I.XLGCLR = '')
)
AND I.H_BSTAT NOT IN ('D', 'M')
;You should have indexes on:
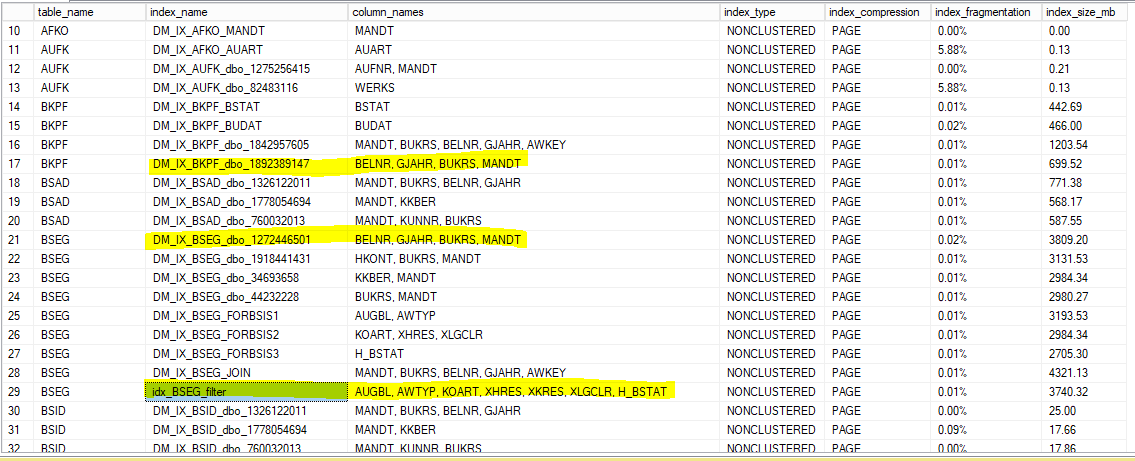
CREATE INDEX idx_BSEG_BKPF_join ON BSEG (MANDT, BUKRS, GJAHR, BELNR);
CREATE INDEX idx_BSEG_filter ON BSEG (AUGBL, AWTYP, KOART, XHRES, XKRES, XLGCLR, H_BSTAT);Also, INCLUDE all the columns that you are selecting in the index.
I would also run the query in Database Engine Tuning Advisor which you can find in SSMS under the Tools menu, then add any of the suggested statistics.
But if you want the best performance you should then create a schema bound view and then index the view:
CREATE VIEW dbo.MyIndexedView
WITH SCHEMABINDING
AS
SELECT COUNT_BIG(*)
FROM BSEG I
LEFT JOIN BKPF H
ON H.MANDT = I.MANDT
AND H.BUKRS = I.BUKRS
AND H.GJAHR = I.GJAHR
AND H.BELNR = I.BELNR
WHERE I.AUGBL <> ''
AND I.AWTYP <> 'GLYEC'
AND (
(I.KOART IN ('D', 'K', 'A') AND I.XHRES = 'X')
OR (I.KOART = 'M' AND I.XKRES = 'X')
OR (I.KOART = 'S' AND I.XKRES = 'X' AND I.XLGCLR = '')
)
AND I.H_BSTAT NOT IN ('D', 'M')
;
CREATE UNIQUE CLUSTERED INDEX idx_MyIndexedView ON dbo.MyIndexedView (TotalCount)
;Obviously the index should really be created on the columns you are selecting.
-
Hi everyone,
Thank you for you really quick and useful answers.
I forgot to tell you the most important part, I need optimize the query and tables for this query, and the query will run once, and will create a new table.
Then the parameters (AUGBL, AWTYP, KOART, XHRES, XKRES, XLGCLR, H_BSTAT) will change just a little bit and I will repeat, so I will create another table. Basically we are taking data from BKPF and BSEG with specific parameters and creating a new table with this data. For those who know SAP, we need to recreate from SAP S/4 HANA "views" BSIS, BSAS, BSIK ,BSAK ect. I need to make sure it is quick, but is not going to be used often, just few times so i don't want to get into so hardcore optimization.
Later today I will come back with an update what i tried and if it worked.
Thank you again!
-
Hello,
I have found the problem, in my indexes i forgot XKRES table I missed that there is difference: XHRES and XKRES.
After preparing the indexes now uses all of them and the query is a lot faster.
Quick question, based on the high size of the tables, indexes will be really big, so i have created them with PAGE Compression. Which is better, with or without compression? I assume the most important thing is in the indexes if they will fit in the RAM? that's why compressed is better, or I am totally incorrect?
Thank you once again!
Martin
- frederico_fonseca wrote:
BSEG is a heap - why don't you have a Clustered index on it?
and reason for not using any of the other indexes may also be related to not having the correct clustered index - as well as not having a index on BSEG that covers the filtering criteria as well as the columns that are part of the select and the join to the other table.
so the SQL Engine decided that it is more cost effective to do a table (HEAP) scan than to do a index scan/seek followed by a row lookup to the HEAP to get the remaining required data.
Hello, to answer your qeustion
I believe that the main reason would be that there is not Unique Primary Key in the table. There isn't even one filed that is unique. If that does not matter for the clustered index, in this case there is NO reason not having clustered index.
The real reason why there are no indexes at all, is that because I started some time ago this job and seems that from 11 people team nobody knew what Index is.. so that's the real reason why there are not indexes, and now I am working on them.
- Martass wrote:
Hello,
I have found the problem, in my indexes i forgot XKRES table I missed that there is difference: XHRES and XKRES.
After preparing the indexes now uses all of them and the query is a lot faster.
Quick question, based on the high size of the tables, indexes will be really big, so i have created them with PAGE Compression. Which is better, with or without compression? I assume the most important thing is in the indexes if they will fit in the RAM? that's why compressed is better, or I am totally incorrect?
Thank you once again!
Martin
If you have page compression the index will fit on fewer pages so there is less reading of the disk. But it will also have to decompress the pages. The best thing to do is try it with each one and then see what see what gives best performance.
-
Hello,
May be I am doing something wrong, may be I am not understanding how the indexes are working, but the final statement does not read the indexes. Here is the statement it should run once to create the table, then I will change the values in the filters and it will run again, to create another table, and I will repeat it 4 times for creation of 4 tables. That's why I decided to prepare indexes in a first place, to make sure quick go trough during creation of the table. So it won't run too long.
Later I will run the same query, where I will change the values in the condition.
SELECT
I.MANDT AS MANDT, I.BUKRS, I.HKONT, I.AUGDT, I.AUGBL,
CASE
WHEN I.KOART = 'S' THEN I.ZUONR
WHEN I.KOART = 'M' THEN I.ZUONR
ELSE I.HZUON
END AS ZUONR,
I.GJAHR, I.BELNR, I.BUZEI, I.H_BUDAT AS BUDAT, I.H_BLDAT AS BLDAT, I.H_WAERS AS WAERS, H.XBLNR,
I.H_BLART AS BLART, I.H_MONAT AS MONAT, I.BSCHL, I.SHKZG, I.GSBER, I.MWSKZ, I.TXDAT_FROM,
I.FKONT, I.DMBTR, I.WRBTR, I.MWSTS, I.WMWST, I.SGTXT, I.PROJN, I.AUFNR, I.WERKS, I.KOSTL, I.ZFBDT,
CASE
WHEN I.KOART = 'S' THEN I.XOPVW
ELSE ''
END AS XOPVW,
I.VALUT, I.H_BSTAT AS BSTAT, I.BDIFF, I.BDIF2, I.VBUND, I.PSWSL, I.WVERW, I.DMBE2, I.DMBE3, I.MWST2,
I.MWST3, I.BDIF3, I.RDIF3, I.XRAGL, I.PROJK, I.PRCTR, H.XSTOV,
CASE
WHEN I._DATAAGING = '00000000' THEN ''
ELSE 'X'
END AS XARCH,
I.PSWBT, I.XNEGP, I.RFZEI, I.CCBTC, I.XREF3, I.BUPLA, I.PPDIFF, I.PPDIF2, I.PPDIF3, I.BEWAR, I.IMKEY,
I.DABRZ, I.INTRENO, I.GRANT_NBR,
CASE
WHEN I.FKBER_LONG = '' THEN I.FKBER
ELSE I.FKBER_LONG
END AS FKBER,
I.FIPOS, I.FISTL, I.GEBER, I.PPRCT, I.BUZID, I.AUGGJ, I.UZAWE, I.SEGMENT, I.PSEGMENT, I.PGEBER, I.PGRANT_NBR,
I.MEASURE, I.BUDGET_PD, I.PBUDGET_PD,
'' AS FIPEX,
I._DATAAGING, I.KIDNO,
SUBSTRING(I.PRODPER, 1, 6) AS PRODPER,
H.PROPMANO, I.GKONT, I.GKART, I.GHKON, H.LOGSYSTEM_SENDER, H.BUKRS_SENDER, H.BELNR_SENDER, H.GJAHR_SENDER, I.BUZEI_SENDER,
I.HBKID, I.HKTID, I.EBELN, I.EBELP
INTO [dbo].[BSIS]
FROM
BSEG I
LEFT OUTER JOIN
BKPF H ON (H.BELNR = I.BELNR AND H.GJAHR = I.GJAHR AND H.BUKRS = I.BUKRS AND H.MANDT = I.MANDT)
WHERE
I.AUGBL = ''
AND NOT (I.AWTYP = 'GLYEC')
AND (
(I.KOART IN ('D', 'K', 'A') AND I.XHRES = 'X')
OR (I.KOART = 'M' AND I.XKRES = 'X')
OR (I.KOART = 'S' AND I.XKRES = 'X' AND I.XLGCLR = '')
)
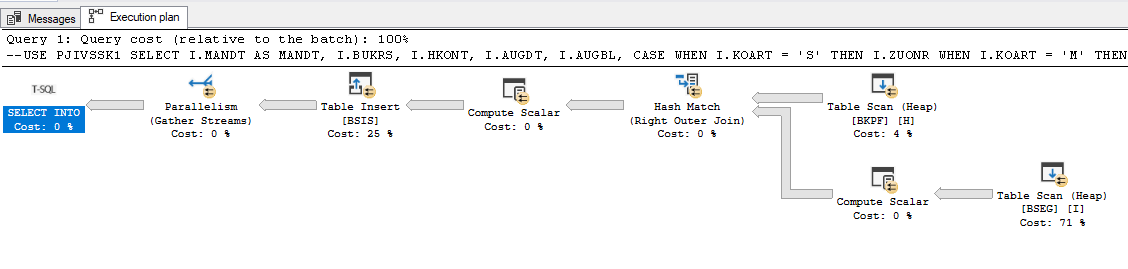
AND I.H_BSTAT NOT IN ('D', 'M')Now, when I show the execution plan, and when I execute it does not use the indexes.
Here are the indexes, don't mind the rest of the indexes, I need them for different statements.
Now, when I run "SELECT COUNT (*)" it uses the indexes, but when I try running the final statement which is in this message, does not use the indexes.
When I select TOP 10 for example, uses only the marked index from BKPF (DM_IX_BKPF_dbo_1892389147) and that's it.
What I am doing wrong?
Thank you in advance
Best Regards,
Martin
-
If you don't have all the columns that are included in the query in the index then SQL Server will have to read the index then go off to the table to get the value of the columns that the index does not have (index key lookup). SQL Server may work out that it is more effort to do this than read the entire table.
You can INCLUDE these nonkey columns that are in query the index:
If you do this, and make sure you INCLUDE all the columns referenced in the query for that table, SLQ Server will then probably use the index for the query.
-
p.s. Page compression includes Row compression, which basically turns a lot of "fixed width" datatypes to "variable width" and that can cause HUGE performance and log file problems due to possibly massive page splits during updates.
As always, "It Depends". Choose carefully.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Hi Jonathan,
Thank you for the clarification. Seems to me that I am not understanding the purpose of indexes in this case.
I thought that indexes are used to find quicker the records based on the conditions under where clause, and if there is JOIN, also the join. I didn't expect that I need to create index based on what is under "select".. may be my logic is totally wrong, but i can imagine how the query uses the indexes to identify the records i need based on the rules (join and where), and when identifies a record, read the rest of the data columns from this record. If Table Scan (heap) does that exactly that, then what is the problem to use the index, which will actually be able to help finding those records quicker? Or if it is not quicker, what I am missing here, why is not quicker?
Can I create Clustered index on table that there is no column with Unique value for each record? What are the prerequisites to be able to create and to make sense creating clustered index?
----
99% of the time the Statements that will be used, will be loading a lot of fields. What type of indexes is best prepare in sucha a cases? There are few important things:
- The database remains static, there wont be anything changed/deleted/added.
- The queries will be the same with small exceptions what fields will be used in where clause (1-2 fields more/less will be used, most of the time at least 2-3 fields will be present).
- The system that uses the SQL Server has one specific function, that always before running the query to load the data, runs 'count' of the records and if the count is more than 100 000, the main query to show the data is not started automatically, but the user should click a button to start. If the records are less than 100 000, the query is started automatically.
- This Count is using the same join/where clauses, only counts the records first, later runs second query to load the data from DB.
- This Count before loading the data makes the loading the data slower while the Application is used. I am testing directly in the SSMS where I don't run the count statement. So I need to make sure this count statement does not make things slower, and would be nice to create good indexes for it.
- Here is an example of complicated Query (The complication is the union), and the indexes I have made, and yet uses just few of those indexes.
- Here is the first query which counts, and later the application sends automatically the next which is eventually almost the same, just instead of count, loading fields from the tables:
SELECT COUNT_BIG(*) FROM
(Select * FROM "dbo"."BSIK" WHERE 1=1 AND [BSIK].[MANDT] = '500'
AND [BSIK].[BUDAT] <= '20151224'
AND [BSIK].[BUDAT] <= '20151224'
AND [BSIK].[BUKRS] = '0800'
UNION
SELECT * FROM [BSAK] WHERE 1=1 AND [BSAK].[MANDT] = '500'
AND [BSAK].[AUGDT] > '20151224'
AND [BSAK].[AUGDT] > '20151224'
AND [BSAK].[BUDAT] <= '20151224'
AND [BSAK].[BUDAT] <= '20151224'
AND [BSAK].[BUKRS] = '0800'
) AS [BSIK]
left join "dbo"."LFA1" on
lfa1.mandt = bsik.MANDT
and lfa1.lifnr = bsik.lifnr
left join "dbo"."LFB1" on
LFB1.mandt = bsik.MANDT
and LFB1.lifnr = bsik.lifnr
and lfb1.bukrs = bsik.bukrs
left join "dbo"."BKPF" on
BSIK.MANDT = BKPF.MANDT
and BSIK.BUKRS = BKPF.BUKRS
and BSIK.BELNR = BKPF.BELNR
and BSIK.GJAHR = BKPF.GJAHR
left join "dbo"."T001" on
BSIK.MANDT = T001.MANDT
and BSIK.BUKRS = T001.BUKRS
WHERE [BSIK].[MANDT] = '500'
AND [BSIK].[BUKRS] = '0800'
- Indexes:
/*
CREATE INDEX [DM_IX_BSIK_JOIN5_FI1510L] ON [dbo].[BSIK] ([MANDT], [BUDAT], [BUKRS]) WITH (DATA_COMPRESSION = PAGE);
CREATE INDEX [DM_IX_BSAK_JOIN5_FI1510L] ON [dbo].[BSAK] ([MANDT], [AUGDT], [BUDAT], [BUKRS]) WITH (DATA_COMPRESSION = PAGE);
CREATE INDEX [DM_IX_LFA1_JOIN_FI1510L] ON [dbo].[LFA1] ([MANDT], [LIFNR]) WITH (DATA_COMPRESSION = PAGE);
CREATE INDEX [DM_IX_BSIK_JOIN1_FI1510L] ON [dbo].[BSIK] ([MANDT], [LIFNR], [BUKRS]) WITH (DATA_COMPRESSION = PAGE);
CREATE INDEX [DM_IX_BSIK_JOIN2_FI1510L] ON [dbo].[BSIK] ([MANDT], [BUKRS], BELNR, GJAHR) WITH (DATA_COMPRESSION = PAGE);
CREATE INDEX [DM_IX_BSIK_JOIN3_FI1510L] ON [dbo].[BSIK] ([MANDT], [BUKRS]) WITH (DATA_COMPRESSION = PAGE);
CREATE INDEX [DM_IX_BSIK_JOIN4_FI1510L] ON [dbo].[BSIK] ([MANDT], [LIFNR]) WITH (DATA_COMPRESSION = PAGE);
CREATE INDEX [DM_IX_BSAK_JOIN1_FI1510L] ON [dbo].[BSAK] ([MANDT], [LIFNR], [BUKRS]) WITH (DATA_COMPRESSION = PAGE);
CREATE INDEX [DM_IX_BSAK_JOIN2_FI1510L] ON [dbo].[BSAK] ([MANDT], [BUKRS], BELNR, GJAHR) WITH (DATA_COMPRESSION = PAGE);
CREATE INDEX [DM_IX_BSAK_JOIN3_FI1510L] ON [dbo].[BSAK] ([MANDT], [BUKRS]) WITH (DATA_COMPRESSION = PAGE);
CREATE INDEX [DM_IX_BSAK_JOIN4_FI1510L] ON [dbo].[BSAK] ([MANDT], [LIFNR]) WITH (DATA_COMPRESSION = PAGE); */
- I have also indexes on BKPF, those seems to be used always. Main problem is using indexes for BSIK/BSAK and the union.. is there alternative that can make this work better/quicker?
- The BSAK and BSIK indexes weren't used even once, i tried few different conditions and queries, but seems that because of the union, those indexes are never used.
- Those tables are relatively small and the query runs for few seconds, but I have very similar situation with 2 huge tables (each around 1TB, with close to 1 Bilion records). I can't imagine there how long the query will run there...
- Here is the first query which counts, and later the application sends automatically the next which is eventually almost the same, just instead of count, loading fields from the tables:
Thank you in advance
-
" If Table Scan (heap) does that exactly that, then what is the problem to use the index, which will actually be able to help finding those records quicker? Or if it is not quicker, what I am missing here, why is not quicker?"
It will find the rows faster but when it finds the rows and you have columns in your select that are not in the index then it has to get the key to the row (stored in the index) on the table then go off to the table to read that row to get the other columns, it would have to do this for each row it finds. This is an expensive operation and if more than a few percent of the rows are returned then it costs more than a single scan of the entire table.
"Can I create Clustered index on table that there is no column with Unique value for each record? "
Yes, creating a clustered index basically orders the table. There is no need for SQL Server to do any index key lookups on a clustered index as it is part of the table. If there isn't a unique key to create a unique clustered index SQL Server will internally create a unique key for each row, so you don't need to worry about it.
If you want advice on what will be good indexes you can start by using the "Database Engine Tuning Advisor" in SSMS, it is located under the Tools menu. You just need to set the query off to run in there and it will recommend indexes and statistics it will also produce scripts to create them.
If you want the query to also run fast when you are selecting additional columns (not just count(*)) you should also include them in the query when you run it in Database Engine Tuning Advisor and it will probably add some INCLUDE columns to the recommended indexes.
- Jonathan AC Roberts wrote:
"
If you want advice on what will be good indexes you can start by using the "Database Engine Tuning Advisor" in SSMS, it is located under the Tools menu. You just need to set the query off to run in there and it will recommend indexes and statistics it will also produce scripts to create them.
I have checked this, unfortunately I am not going to get the rights to use DTA because needs system admin (or some high rights), and in big corporation like the one I work, there is no chance for exception. But, colleagues from MSSQL Admin team told me that there are application similar to this one, and they can be installed on my local computer. The problem is that my computer does not have enough Disk space for the database to be copied so.... My question is, is it going to work, if I copy for example 10% of the tables and do the test on 10% of the records? How important is the size of the table for creation of the indexes?
Or other scenario, is it going to work same as compressed and not compressed tables? For example I can compress tables, move them to my local computer and test it, but I will have tables that are compressed, an in the production database, they won't be compressed. Is it going to affect somehow the index logic and testing it in general?
Also another question, can you recommend such an application which have similar functions/features as DTA?
Thank you in advance
Best Regards,
Martin
-
I would guess that it would give the same recommendation in your scenario of moving it to a local machine compressing the tables.
If you just run the query with the execution plan this might also show suggested indexes and if you look in the XML there might be some more suggested.

Viewing 15 posts - 1 through 15 (of 21 total)
You must be logged in to reply to this topic. Login to reply