how to speed this query up?
-
hi everyone
I have a query I use at work. I use percent_rank to rank sales by company for the last 50 days. For example, if I run the query today then I want to look at the last 50 days of data (including today) and then rank the sales for those 50 days. So tomorrow, if I run the query then the 50 day period drops the first day and adds tomorrows day so it is a rolling 50 day. Ideally, I want percent_rank to be a window function but this option is not available for percent_rank. So, I created a query that does the same thing but it is super inefficient. I have a test table with 25k records. the query took close to 10 minutes to run. not acceptable at all. I just don't know how to make it faster. How can I speed up this query?
Thank you
-
I'm not so good with abstract requirements.
Do you have some sample data? And the desired output
You didn't limit sales to the lookback period in CTE1, why is dat?
Is it about the top sales per company or the companies with the most sales
-
sure thing no problem.
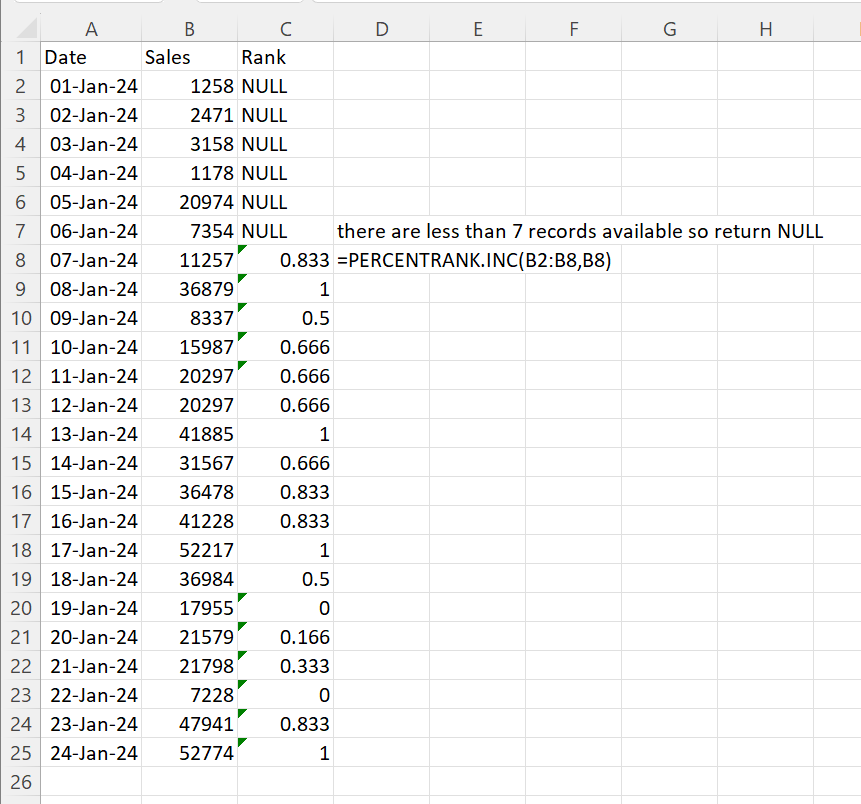
I have attached an Excel sheet with sample data and expected outcome. In case you prefer to not download file then here is a screenshot with description. Let's look at an example where the lookback period is 7 days. It is easier to show this than 50 but the concepts are the same.
Screenshot:

Sample data:
CREATE TABLE [dbo].[SampleCalculation](
[Date] [date] NOT NULL,
[Sales] [int] NOT NULL
) ON [PRIMARY]
GO
INSERT [dbo].[SampleCalculation] ([Date], [Sales]) VALUES (CAST(N'2024-01-01' AS Date), 1258)
GO
INSERT [dbo].[SampleCalculation] ([Date], [Sales]) VALUES (CAST(N'2024-01-02' AS Date), 2471)
GO
INSERT [dbo].[SampleCalculation] ([Date], [Sales]) VALUES (CAST(N'2024-01-03' AS Date), 3158)
GO
INSERT [dbo].[SampleCalculation] ([Date], [Sales]) VALUES (CAST(N'2024-01-04' AS Date), 1178)
GO
INSERT [dbo].[SampleCalculation] ([Date], [Sales]) VALUES (CAST(N'2024-01-05' AS Date), 20974)
GO
INSERT [dbo].[SampleCalculation] ([Date], [Sales]) VALUES (CAST(N'2024-01-06' AS Date), 7354)
GO
INSERT [dbo].[SampleCalculation] ([Date], [Sales]) VALUES (CAST(N'2024-01-07' AS Date), 11257)
GO
INSERT [dbo].[SampleCalculation] ([Date], [Sales]) VALUES (CAST(N'2024-01-08' AS Date), 36879)
GO
INSERT [dbo].[SampleCalculation] ([Date], [Sales]) VALUES (CAST(N'2024-01-09' AS Date), 8337)
GO
INSERT [dbo].[SampleCalculation] ([Date], [Sales]) VALUES (CAST(N'2024-01-10' AS Date), 15987)
GO
INSERT [dbo].[SampleCalculation] ([Date], [Sales]) VALUES (CAST(N'2024-01-11' AS Date), 20297)
GO
INSERT [dbo].[SampleCalculation] ([Date], [Sales]) VALUES (CAST(N'2024-01-12' AS Date), 20297)
GO
INSERT [dbo].[SampleCalculation] ([Date], [Sales]) VALUES (CAST(N'2024-01-13' AS Date), 41885)
GO
INSERT [dbo].[SampleCalculation] ([Date], [Sales]) VALUES (CAST(N'2024-01-14' AS Date), 31567)
GO
INSERT [dbo].[SampleCalculation] ([Date], [Sales]) VALUES (CAST(N'2024-01-15' AS Date), 36478)
GO
INSERT [dbo].[SampleCalculation] ([Date], [Sales]) VALUES (CAST(N'2024-01-16' AS Date), 41228)
GO
INSERT [dbo].[SampleCalculation] ([Date], [Sales]) VALUES (CAST(N'2024-01-17' AS Date), 52217)
GO
INSERT [dbo].[SampleCalculation] ([Date], [Sales]) VALUES (CAST(N'2024-01-18' AS Date), 36984)
GO
INSERT [dbo].[SampleCalculation] ([Date], [Sales]) VALUES (CAST(N'2024-01-19' AS Date), 17955)
GO
INSERT [dbo].[SampleCalculation] ([Date], [Sales]) VALUES (CAST(N'2024-01-20' AS Date), 21579)
GO
INSERT [dbo].[SampleCalculation] ([Date], [Sales]) VALUES (CAST(N'2024-01-21' AS Date), 21798)
GO
INSERT [dbo].[SampleCalculation] ([Date], [Sales]) VALUES (CAST(N'2024-01-22' AS Date), 7228)
GO
INSERT [dbo].[SampleCalculation] ([Date], [Sales]) VALUES (CAST(N'2024-01-23' AS Date), 47941)
GO
INSERT [dbo].[SampleCalculation] ([Date], [Sales]) VALUES (CAST(N'2024-01-24' AS Date), 52774)
GOExplanation:
- If there are less than 7 days available to do the calculation then return NULL.
- If there are at least 7 days available then the calculation can be done. On Jan 15, find the rank of 36478 relative to sales from Jan 9 to Jan 15. On Jan 16, find the rank of 41228 relative to sales from Jan 10 to Jan 16. Excel has the function PERCENTRANK.INC which does the calculation I want.
-
Need the DDL for the table to sure of more specific recommendations for best speed, but, assuming you will keep a long history in this table:
(1) Either:
(A) cluster the table by TXN_DATE and COMPANY (which is hopefully unique); it's possible that if the table has an identity column, using TXN_DATE, $IDENTITY will be a better clustering key
(B) create a covering index for the query: key columns: TXN_DATE, COMPANY /*or possibly $IDENTITY, as above*/; nonkey column(s): SALES
(2) Add a min TXN_DATE as a WHERE condition in the initial query:
WHERE TXN_DATE >= DATEADD(DAY,@LOOK_BACK_PERIOD * 2, CAST(GETDATE() AS day))
It's possible that an index on COMPANY, TXN_DATE would perform better for the query (by avoiding a sort), but it would almost certainly be less efficient when inserting rows.
I don't see the need for two ROW_NUMs since both will always have the same value.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ScottPletcher wrote:
Need the DDL for the table to sure of more specific recommendations for best speed, but, assuming you will keep a long history in this table:
(1) Either: (A) cluster the table by TXN_DATE and COMPANY (which is hopefully unique); it's possible that if the table has an identity column, using TXN_DATE, $IDENTITY will be a better clustering key (B) create a covering index for the query: key columns: TXN_DATE, COMPANY /*or possibly $IDENTITY, as above*/; nonkey column(s): SALES
(2) Add a min TXN_DATE as a WHERE condition in the initial query: WHERE TXN_DATE >= DATEADD(DAY,@LOOK_BACK_PERIOD * 2, CAST(GETDATE() AS day))
It's possible that an index on COMPANY, TXN_DATE would perform better for the query (by avoiding a sort), but it would almost certainly be less efficient when inserting rows.
I don't see the need for two ROW_NUMs since both will always have the same value.
there is a clustered columnstore index on DBO.COMPANY_TABLE. Should I try a different type of index?
- water490 wrote:ScottPletcher wrote:
Need the DDL for the table to sure of more specific recommendations for best speed, but, assuming you will keep a long history in this table:
(1) Either: (A) cluster the table by TXN_DATE and COMPANY (which is hopefully unique); it's possible that if the table has an identity column, using TXN_DATE, $IDENTITY will be a better clustering key (B) create a covering index for the query: key columns: TXN_DATE, COMPANY /*or possibly $IDENTITY, as above*/; nonkey column(s): SALES
(2) Add a min TXN_DATE as a WHERE condition in the initial query: WHERE TXN_DATE >= DATEADD(DAY,@LOOK_BACK_PERIOD * 2, CAST(GETDATE() AS day))
It's possible that an index on COMPANY, TXN_DATE would perform better for the query (by avoiding a sort), but it would almost certainly be less efficient when inserting rows.
I don't see the need for two ROW_NUMs since both will always have the same value.
there is a clustered columnstore index on DBO.COMPANY_TABLE. Should I try a different type of index?
Yes, add a nonclustered index.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ScottPletcher wrote:water490 wrote:ScottPletcher wrote:
Need the DDL for the table to sure of more specific recommendations for best speed, but, assuming you will keep a long history in this table:
(1) Either: (A) cluster the table by TXN_DATE and COMPANY (which is hopefully unique); it's possible that if the table has an identity column, using TXN_DATE, $IDENTITY will be a better clustering key (B) create a covering index for the query: key columns: TXN_DATE, COMPANY /*or possibly $IDENTITY, as above*/; nonkey column(s): SALES
(2) Add a min TXN_DATE as a WHERE condition in the initial query: WHERE TXN_DATE >= DATEADD(DAY,@LOOK_BACK_PERIOD * 2, CAST(GETDATE() AS day))
It's possible that an index on COMPANY, TXN_DATE would perform better for the query (by avoiding a sort), but it would almost certainly be less efficient when inserting rows.
I don't see the need for two ROW_NUMs since both will always have the same value.
there is a clustered columnstore index on DBO.COMPANY_TABLE. Should I try a different type of index?
Yes, add a nonclustered index.
i added the nonclustered unique index on company and txn_date. the run time is now close to 30 seconds. way better than the original 10 minutes! but 30 seconds is still too long. i think the query needs to be redone so its more efficient. any suggestions on how i can fix my code?
-
Did you add the WHERE condition for the TXN_DATE? If you have a long history in the table, that would help the most.
Then try an index on (txn_date, company) include ( sales).
Being a DBA, I use only CREATE INDEX statements to create indexes, not the gui:
CREATE UNIQUE NONCLUSTERED INDEX [your_index_name_here] ON dbo.your_table_name_here ( txn_date, company ) INCLUDE ( sales ) /*this is critical!*/ WITH ( FILLFACTOR = 96, SORT_IN_TEMPDB = ON );
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ScottPletcher wrote:
Did you add the WHERE condition for the TXN_DATE? If you have a long history in the table, that would help the most.
Then try an index on (txn_date, company) include ( sales).
Being a DBA, I use only CREATE INDEX statements to create indexes, not the gui:
CREATE UNIQUE NONCLUSTERED INDEX [your_index_name_here] ON dbo.your_table_name_here ( txn_date, company ) INCLUDE ( sales ) /*this is critical!*/ WITH ( FILLFACTOR = 96, SORT_IN_TEMPDB = ON );
thanks for this. i used the gui to create it. i noticed that the fillfactor is not selected and the sort_in_tempdb = off for mine. should i update my index parameters so it matches the arguments you have?
there are instances where the accounting team does back-dated entries that could be past the 50 day mark. it is hard to say exactly how far back they can go so i assume that the data i am working with is not 100% static hence re-calc on the entire dataset to be safe. is it efficient no but it is safer b/c that way i know i am not missing any records.
is the query i have written efficient? i am thinking no b/c i had to use self joins and i never really like doing this. my experience has been doing self joins like how i did are never efficient but they get the right answer (eventually). i am open to all ideas.
-
duplicate post by accident
-
You've already got restrictions based on @LOOK_BACK_PERIOD in the WHEREs, it would just be more efficient to pre-filter rather than waiting until some processing has been done on all the rows.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ScottPletcher wrote:
You've already got restrictions based on @LOOK_BACK_PERIOD in the WHEREs, it would just be more efficient to pre-filter rather than waiting until some processing has been done on all the rows.
i see your point. i added the code. i am getting an error.
code:
DATEADD(DAY,@LOOK_BACK_PERIOD * 2, CAST(GETDATE() AS day))
error:
Msg 243, Level 16, State 1, Line 20
Type day is not a defined system type. -
D'OH, sorry, that should be:
CAST(GETDATE() AS date)
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
I know a lot of discussion has already happened on this, but I wanted to point out that it would be nice to see the actual vs estimated execution plan. This will give everyone a rough idea on what the "slow" points in the query are. It will not give a full picture, but a rough idea. Things that it won't really tell us is if your system is under-provisioned (not enough RAM, not enough CPU, disk too slow, network too slow, etc) or if there are performance problems elsewhere (misconfigured system such as maxdop at default, max memory at default, etc). Execution plan helps ensure you are looking in the correct place to try to resolve the problem.
I can't see the original query, but if, for example, you are trying to tune one part of your query in a CTE that is returning 10 rows and completes in 0.1 seconds, then tuning that is likely wasted effort. I say "likely" as if you are calling that portion of code 100, that will eat up to 10 seconds. I know the math for that isn't going to be EXACTLY 10 seconds as there are other factors that can impact run time of queries, but just using that as an example.
I am also curious where you are pushing the results. Are they coming to screen in SSMS in the graph, are they going to SSRS, are they going to Excel, are they going to another table? The reason I ask is if you are tuning the query in SSMS but plan to use the results in SSRS, I would recommend tuning it in SSMS with "results to text" selected and testing the tuning in SSRS. The reason being that results to grid (I think that is what it is called... whatever is default in SSMS) does take some time to process large data volumes. SOMETIMES the slowdown is due to the tool and if that is the case here, then you may get better performance from SSRS than SSMS and the performance may be acceptable (ie under 30 seconds).
Also, I would be careful about adding indexes as it will impact performance of insert, update, and delete operations. So making your one query faster MAY result in other queries being slower. Adding 1 index likely isn't going to impact things too badly, but I try to do some testing of other queries that may be impacted by my change if possible.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system.
Viewing 14 posts - 1 through 14 (of 14 total)
You must be logged in to reply to this topic. Login to reply