


This image is generated by Google Gemini
Introduction
The way we work is about to change drastically. Generative AI tools like Gemini, ChatGPT and their underlying large language models (LLMs) have reached unprecedented levels of sophistication. From marketing copy to legal documents, these AI systems promise to automate and augment tasks previously believed to require uniquely human skills. A recent McKinsey report suggests that generative AI could disrupt 80% of knowledge-based work in the near future. While the potential benefits are vast, this revolution also raises challenges for businesses, particularly when it comes to understanding how existing job roles must adapt.
At the forefront of this transformation stands the modern data professional. For data professionals, this evolution presents a pivotal moment – a landscape demanding adaptation, new skill acquisition, and the potential to play a central role in shaping an organization's AI-driven future. Large language models (LLMs) are fundamentally changing how we interact with data. The emphasis on high-quality data for LLM training and fine-tuning is undeniable. Data professionals must prioritize data cleansing, bias mitigation, and ensuring representativeness within datasets. Additionally, ethical sourcing and labeling practices remain paramount.
As the nature of data expands to encompass vast amounts of unstructured text, images, audio, and video, the core principles of data management become even more critical. Organizing and securing this information, along with robust metadata practices, will facilitate effective analysis. Collaboration and clear communication between data professionals, AI engineers, and domain experts will undoubtedly be essential for successful LLM deployment and integration.
The Changing Landscape of Data
While the rise of generative AI highlights the growing prominence of unstructured data (pdf, images, audio, video, etc), the fundamental principles that have shaped the management of structured data remain surprisingly relevant. Organizations will grapple with a complex data environment, and data professionals hold the key to understanding these evolving dynamics and ensuring success.
Metadata is the backbone of data analysis in natural language
Metadata that has long been essential for understanding and utilizing structured data. Rich metadata is going to play a pivotal role in enabling natural language queries over the information stored in databases. The need for pristine data catalogs and metadata cannot be underestimated. Just as structured data is organized as fields, tables, and relationships, unstructured data demands a comprehensive metadata framework as well. This includes details like the source, format, content description, and any relevant contextual information. With LLMs capable of understanding and responding to natural language, metadata becomes the bridge that enables machines to "read" and make sense of the vast sea of unstructured data.
The New Frontier: organizing the unstructured
The need to organize unstructured data in a systematic and searchable way mirrors the practices established for structured data. Applying proven database concepts like indexing, cataloging, and taxonomy creation allows organizations to effectively query and utilize diverse data sources. Data professionals also need to start gaining expertise with the new types of data - embeddings. Embeddings are vector representations of words, sentences, or even entire documents. These vectors are created using algorithms that capture patterns and relationships from large corpus of data. In other words, words or concepts that are similar in meaning will have vector representations that are close to each other in the high-dimensional vector space. Most data and metadata that is to be analyzed by LLMs has to be converted into embeddings are stored in a vector database. The diagram below shows the simplistic flow of data in a generative AI application.
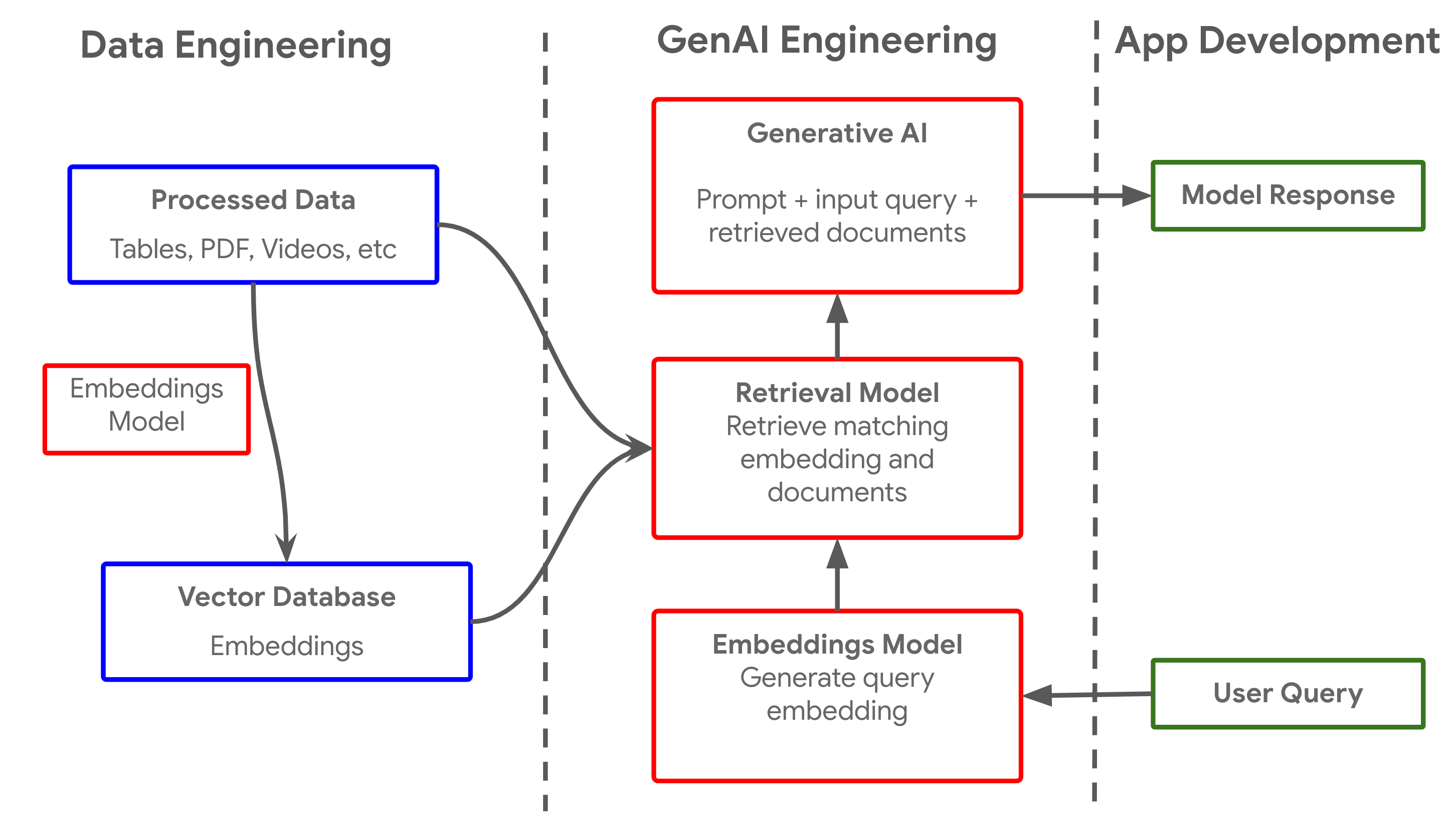
A simplistic view of data retrieval based generative AI pipeline
While the data engineering is oversimplified in this diagram, it is arguably the most complex and critical process in the entire flow. Data professionals must spearhead this effort, developing innovative approaches to organize massive amounts of unstructured data with the goal of LLM-powered analysis.
Governance and security
Just as governance and security protocols are paramount for safeguarding structured data, they are equally crucial in the era of generative AI. As LLMs access a wider range of data, including potentially sensitive or confidential information, data professionals must uphold the highest standards of data privacy and protection. Establishing and enforcing clear governance policies concerning data access, usage, and retention will ensure that organizations are meeting compliance requirements and mitigating potential risks. Similarly, robust security measures are essential to prevent data breaches and unauthorized access that could compromise an organization's intellectual property or customer trust.
Bridging the past and the future
Data evolution demands adaptability from data professionals. While embracing the opportunities presented by unstructured data and generative AI, their expertise in the core principles of data management serves as an invaluable foundation. By understanding the parallels between structured and unstructured data, data professionals become the crucial link between established practices and the emerging frontiers of AI-powered innovation.
Data Preparation and Curation Take Center Stage
The adage "garbage in, garbage out" becomes a stark reality when working with large language models (LLMs). High-quality, meticulously curated data is the lifeblood upon which effective LLM training and fine-tuning depend. Data professionals find themselves at the forefront of this endeavor, their expertise more crucial than ever to deliver the outcomes executives expect from their AI investments.
The Imperative of Clean and Unbiased Datasets
Data cleaning takes on heightened importance. Inaccuracies, inconsistencies, and ambiguity can severely undermine the quality of LLM output. Data professionals must rigorously apply established cleaning techniques along with developing new methods specifically tailored to the nuances of LLM use. Detecting and mitigating biases within datasets is another important responsibility. LLMs trained on biased data risk perpetuating those biases, potentially leading to discriminatory or harmful outputs. Ensuring diverse representation throughout data collection and actively seeking out ways to counterbalance existing biases are essential for building trustworthy and equitable AI systems.
Ethical considerations in sourcing and labeling data
The ethical implications of data practices extend beyond bias mitigation. These are the early days for Generative AI and businesses are moving rapidly to gain a competitive edge. Data professionals must become conscientious stewards, prioritizing the ethical sourcing of data. This includes respecting privacy, obtaining explicit consent when applicable, and scrutinizing third-party datasets to avoid reinforcing harmful stereotypes or perpetuating systemic imbalances. Additionally, clear and comprehensive labeling takes on a heightened significance. Detailed metadata that describes the context, provenance, and intended use of data becomes indispensable for use with LLM and responsible deployment of fine-tuned models.
Gathering User Feedback
As LLM-powered applications are deployed throughout an organization, gathering and organizing user feedback becomes a crucial new data source. This feedback loop allows data professionals to iterate on the data used to fine-tune models. By systematically analyzing user interactions, successes, and failures, they can target areas where data quality improvements would boost LLM performance and overall user satisfaction. Do keep ethical considerations in mind when collecting the user data, though.
LLMs as Data Engineering Tools
The integration of large language models (LLMs) has potential to revolutionize data transformation processes within organizations, providing data professionals with unprecedented opportunities to enhance productivity and unveil new insights. LLMs empower data professionals to streamline workflows by automating repetitive tasks and generating code efficiently. This will enable them to focus on high-value activities, such as data analysis and decision-making. Furthermore, LLMs can alleviate data scarcity challenges by generating synthetic data, augmenting existing datasets, and improving the accuracy of machine-learning models. By leveraging LLMs' capabilities, data professionals can unlock the full potential of data-driven decision-making, driving innovation and gaining a competitive edge in today's data-centric landscape.
Accelerating Development with AI-Assisted Coding
Tools like DuetAI and GitHub Copilot have become powerful assistants for data engineers. Powered by LLMs, they leverage natural language descriptions to offer code suggestions, complete code snippets, and even write entire functions. This not only saves time for data engineers but can also help them explore different approaches to solve engineering problems. By offloading routine coding tasks, data engineers gain the bandwidth to focus on architecting complex pipelines, optimizing data models, and addressing performance bottlenecks.
Streamlining Data Preparation
Similar to their role in data transformation for data professionals at large, LLMs empower data engineers specifically to expedite the cleaning and preparation processes. Tasks like identifying and correcting errors within data, standardizing formats, and enriching datasets with additional context can be partially automated using LLM-powered solutions. This minimizes manual labor and frees up data engineers to concentrate on ensuring the overall integrity and quality of the data infrastructure.
Data Augmentation, Synthetic Data, and Monitoring with LLMs
Data engineers often face the challenges of sparse or unbalanced datasets. LLMs offer solutions for data augmentation, where variations of existing data are generated to improve the robustness of machine learning models. In scenarios where sensitive data cannot be used directly, the generation of synthetic data by LLMs provides a valuable alternative for development and testing purposes. Additionally, LLMs can be integrated into data monitoring pipelines, facilitating the detection of data anomalies, quality issues, or unexpected shifts in data distributions. Timely alerts from such systems enable data engineers to act quickly and preserve the health of data systems.
Prompt Engineering is a Critical Data Engineering Skill
Data engineers, like other data professionals, will reap the most significant benefits from LLMs by mastering the skill of prompt engineering. The ability to clearly articulate data requirements, cleaning instructions, or desired code functionality in natural language plays a crucial role in effective LLM utilization. Investing in prompt engineering techniques empowers data engineers to translate business requirements into actionable LLM prompts, driving efficiencies and innovation throughout the data engineering process.
Conclusion
Generative AI undeniably transforms the landscape of data careers. Data professionals must adapt—traditional skills like data preparation and curation remain crucial, but with an increased focus on AI-specific requirements. New competencies, like prompt engineering and understanding LLM capabilities, are vital for maximizing the value of these powerful tools.
Collaboration and communication are key to successful LLM integration. Data professionals must work alongside AI engineers and business stakeholders, translating complex AI concepts for non-technical audiences and business needs into effective prompts.
This evolution demands continuous learning and a willingness to embrace new tools. By focusing on value-added activities such as ensuring data quality, mitigating bias, adopting vector databases, and mastering AI interaction, data professionals will remain highly relevant within their organizations.
Generative AI is a catalyst for innovation. Data professionals who approach this transformation with adaptability and a thirst for knowledge will position themselves as key players in the AI revolution. By honing their expertise, embracing collaboration, and mastering communication with AI systems, they will secure not only their future relevance but also a leadership role in the exciting world of AI-powered possibilities.
