

Cosmos DB is an awesome product that is mainly used for large-scale OLTP solutions. Any web, mobile, gaming, and IoT application that needs to handle massive amounts of data, reads, and writes at a globally distributed scale with near-real response times for a variety of data are great use cases (It can be scaled-out to support many millions of transactions per second). Because it fits in the NoSQL category and is a scale-out solution, it can be difficult to wrap your head around how it works if you come from the relational world (i.e. SQL Server). So this blog will be out the differences in how Cosmos DB works.
First, a quick comparison of terminology to help you understand the difference:
| RDBMS | Cosmos DB (Document Model) | Cosmos DB (Graph Model |
| Database | Database | Database |
| Table, view | Collection | Graph |
| Row | Document (JSON) | Vertex |
| Column | Property | Property |
| Foreign Key | Reference | Edge |
| Join | Embedded document | .out() |
| Partition Key/Sharding Key | Partition Key | Partition Key |
From Welcome to Azure Cosmos DB and other documentation, here are some key points to understand:
- You can distribute your data to any number of Azure regions, with the click of a button. This enables you to put your data where your users are, ensuring the lowest possible latency to your customers
- When a new region gets added, it is available for operations within 30 minutes anywhere in the world (assuming your data is 100 TBs or less).
- To control exact sequence of regional failovers in cases of an outage, Azure Cosmos DB enables you to associate a priority with various regions associated with the database account
- Azure Cosmos DB enables you to configure the regions (associated with the database) for “read”, “write” or “read/write” regions.
- For Cosmos DB to offer strong consistency in a globally distributed setup, it needs to synchronously replicate the writes or to synchronously perform cross-region reads. The speed of light and the wide area network reliability dictates that strong consistency will result in higher latencies and reduced availability of database operations. Hence, in order to offer guaranteed low latencies at the 99th percentile and 99.99% availability for all single region accounts and all multi-region accounts with relaxed consistency, and 99.999% availability on all multi-region database accounts, it must employ asynchronous replication. This in-turn requires that it must also offer well-defined, relaxed consistency model(s) – weaker than strong (to offer low latency and availability guarantees) and ideally stronger than “eventual” consistency (with an intuitive programming model)
- Using Azure Cosmos DB’s multi-homing APIs, an app always knows where the nearest region is and sends requests to the nearest data center. All of this is possible with no config changes. You set your write-region and as many read-regions as you want, and the rest is handled for you
- As you add and remove regions to your Azure Cosmos DB database, your application does not need to be redeployed and continues to be highly available thanks to the multi-homing API capability
- It supports multiple data models, including but not limited to document, graph, key-value, table, and column-family data models
- APIs for the following data models are supported with SDKs available in multiple languages: SQL API, MongoDB API, Cassandra API, Gremlin API, Table API
- 99.99% availability SLA for all single region database accounts, and all 99.999% read availability on all multi-region database accounts. Deploy to any number of Azure regions for higher availability and better performance
- For a typical 1KB item, Cosmos DB guarantees end-to-end latency of reads under 10 ms and indexed writes under 15 ms at the 99th percentile within the same Azure region. The median latencies are significantly lower (under 5 ms). So you will want to deploy your app and your database to multiple regions to have users all over the world have the same low latency. If you have an app in one region but the Cosmos DB database in another, then you will have additional latency between the regions (see Azure Latency Test to determine what that latency would be, or go to see existing latency via the Azure Portal and choose Azure Cosmos DB then choose your database then choose Metrics -> Consistency -> SLA -> Replication latency)
- Developers reserve throughput of the service according to the application’s varying load. Behind the scenes, Cosmos DB will scale up resources (memory, processor, partitions, replicas, etc.) to achieve that requested throughput while maintaining the 99th percentile of latency for reads to under 10 ms and for writes to under 15 ms. Throughput is specified in request units (RUs) per second. The number of RUs consumed for a particular operation varies based upon a number of factors, but the fetching of a single 1KB document by id spends roughly 1 RU. Delete, update, and insert operations consume roughly 5 RUs assuming 1 KB documents. Big queries and stored procedure executions can consume 100s or 1000s of RUs based upon the complexity of the operations needed. For each collection (bucket of documents), you specify the RUs
- Throughput directly affects how much the user is charged but can be tuned up dynamically to handle peak load and down to save costs when more lightly loaded by using the Azure Portal, one of the supported SDKs, or the REST API
- Request Units (RU) are used to guarantee throughput in Cosmos DB. You will pay for what you reserve, not what you use. RUs are provisioned by region and can vary by region as a result. But they are not shared between regions. This will require you to understand usage patterns in each region you have a replica
- For applications that exceed the provisioned request unit rate for a container, requests to that collection are throttled until the rate drops below the reserved level. When a throttle occurs, the server preemptively ends the request with RequestRateTooLargeException (HTTP status code 429) and returns the x-ms-retry-after-ms header indicating the amount of time, in milliseconds, that the user must wait before reattempting the request. So, you will get 10ms reads as long as requests stay under the set RU’s
- Cosmos DB provides five consistency levels: strong, bounded-staleness, session, consistent prefix, and eventual. The further to the left in this list, the greater the consistency but the higher the RU cost which essentially lowers available throughput for the same RU setting. Session level consistency is the default. Even when set to lower consistency level, any arbitrary set of operations can be executed in an ACID-compliant transaction by performing those operations from within a stored procedure. You can also change the consistency level for each request using the x-ms-consistency-level request header or the equivalent option in your SDK
- Azure Cosmos DB accounts that are configured to use strong consistency cannot associate more than one Azure region with their Azure Cosmos DB account
- There is not support for GROUP BY or other aggregation functionality found in database systems (workaround is to use Spark to Cosmos DB connector)
- No database schema/index management – it automatically indexes all the data it ingests without requiring any schema or indexes and serves blazing fast queries. By default, every field in each document is automatically indexed generally providing good performance without tuning to specific query patterns. These defaults can be modified by setting an indexing policy which can vary per field.
- Industry-leading, financially backed, comprehensive service level agreements (SLAs) for availability, latency, throughput, and consistency for your mission-critical data
- There is a local emulator running under MS Windows for developer desktop use (was added in the fall of 2016)
- Capacity options for a collection: Fixed (max of 10GB and 400 – 10,000 RU/s), Unlimited (1,000 – 100,000 RU/s). You can contact support if you need more than 100,000 RU/s. There is no limit to the total amount of data or throughput that a container can store in Azure Cosmos DB
- Costs: SSD Storage (per GB): $0.25 GB/month; Reserved RUs/second (per 100 RUs, 400 RUs minimum): $0.008/hour (for all regions except Japan and Brazil which are more)
- Global distribution (also known as global replication/geo-redundancy/geo-replication) is for delivering low-latency access to data to end users no matter where they are located around the globe and for adding regional resiliency for business continuity and disaster recovery (BCDR). When you choose to make containers span across geographic regions, you are billed for the throughput and storage for each container in every region and the data transfer between regions
- Cosmos DB implements optimistic concurrency so there are no locks or blocks but instead, if two transactions collide on the same data, one of them will fail and will be asked to retry
- Because there is currently no concept of a constraint, foreign-key or otherwise, any inter-document relationships that you have in documents are effectively “weak links” and will not be verified by the database itself. If you want to ensure that the data a document is referring to actually exists, then you need to do this in your application, or through the use of server-side triggers or stored procedures on Azure Cosmos DB.
- You can set up a policy to geo-fence a database to specific regions. This geo-fencing capability is especially useful when dealing with data sovereignty compliance that requires data to never leave a specific geographical boundary
- Backups are taken every four hours and two are kept at all times. Also, in the event of database deletion, the backups will be kept for thirty days before being discarded. With these rules in place, the client knows that in the event of some unintended data modification, they have an eight-hour window to get support involved and start the restore process
- Cosmos DB is an Azure data storage solution which means that the data at rest is encrypted by default and data is encrypted in transit. If you need Role-Based Access Control (RBAC), Azure Active Directory (AAD) is supported in Cosmos DB
- Within Cosmos DB, partitions are used to distribute your data for optimal read and write operations. It is recommended to create a granular key with highly distinct values. The partitions are managed for you. Cosmos DB will split or merge partitions to keep the data properly distributed. Keep in mind your key needs to support distributed writes and distributed reads
- Until recently, writes could only be made to one region. But now in private preview is writes to multi regions. See Multi-master at global scale with Azure Cosmos DB. With Azure Cosmos DB multi-master support, you can perform writes on containers of data (for example, collections, graphs, tables) distributed anywhere in the world. You can update data in any region that is associated with your database account. These data updates can propagate asynchronously. In addition to providing fast access and write latency to your data, multi-master also provides a practical solution for failover and load-balancing issues.
Azure Cosmos DB allows you to scale throughput (as well as, storage), elastically across any number of regions depending on your needs or demand.
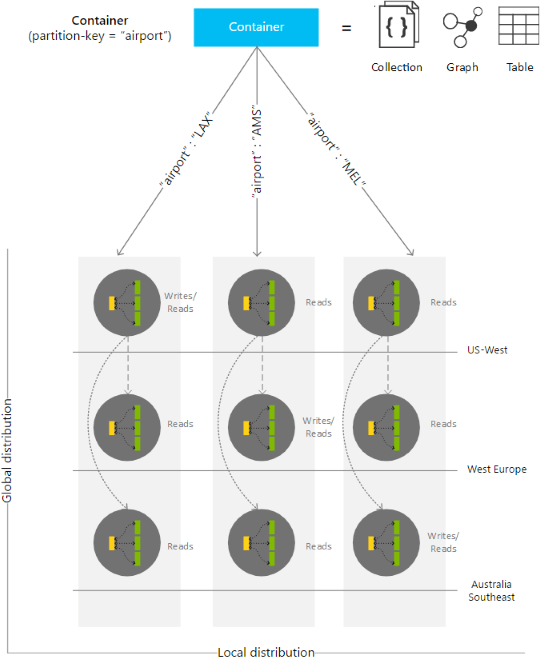
The above pictures shows a single Azure Cosmos DB container horizontally partitioned (across three resource partitions within a region) and then globally distributed across three Azure regions
An Azure Cosmos DB container gets distributed in two dimensions (i) within a region and (ii) across regions. Here’s how (see Partition and scale in Azure Cosmos DB for more info):
- Local distribution: Within a single region, an Azure Cosmos DB container is horizontally scaled out in terms of resource partitions. Each resource partition manages a set of keys and is strongly consistent and highly available being physically represented by four replicas also called a replica-set and state machine replication among those replicas. Azure Cosmos DB is a fully resource-governed system, where a resource partition is responsible to deliver its share of throughput for the budget of system resources allocated to it. The scaling of an Azure Cosmos DB container is transparent to the users. Azure Cosmos DB manages the resource partitions and splits and merges them as needed as storage and throughput requirements change
- Global distribution: If it is a multi-region database, each of the resource partitions is then distributed across those regions. Resource partitions owning the same set of keys across various regions form a partition set (see preceding figure). Resource partitions within a partition set are coordinated using state machine replication across multiple regions associated with the database. Depending on the consistency level configured, the resource partitions within a partition set are configured dynamically using different topologies (for example, star, daisy-chain, tree etc.)
The following links can help with understanding the core concepts better: Request units in Azure Cosmos DB, Performance tips for Azure Cosmos DB and .NET, Tuning query performance with Azure Cosmos DB, Partitioning in Azure Cosmos DB using the SQL API, Leverage Azure CosmosDB metrics to find issues.
You can Try Azure Cosmos DB for Free without an Azure subscription, free of charge and commitments. For a good training course on Cosmos DB check out Developing Planet-Scale Applications in Azure Cosmos DB.
More info:
Relational databases vs Non-relational databases
A technical overview of Azure Cosmos DB

![]()
