How to extract number that is greater than or equal to 16 digits
-
Good Morning,
I am using sql server 2022, I have a table I would like to extract 16 Digits or more numbers (if any exist)
Please kindly help. Thank you in advance
Create Table #Payments (ID int, Comment Text)
INSERT INTO #payments values (1, '65607 Processed via? DISC Last 4 digits of credit card:7144 Last 4 digits of checking account: Confirmation number: 8787082513313224314 Receipt sent? No CSR: Charlett')
INSERT INTO #payments values (2, 'HO_QuoteOutput_11131_0.5509311349467635_1.pdf Category: QUOTE SubCategory: Card is 3412123412341234')
INSERT INTO #payments values (3, '11/28/12 auto rnwl /// paid in full #4482501239835011 x 5/14 paid in full emld receipt')
INSERT INTO #payments values (4, 'Processed CC payment of $514.24 per webiste Confirmation number: 08748C 3482568639165011 Processed check of $64 per feat website Confirmation Number: 9019991201')
INSERT INTO #payments values (5, '2/26 left a message for william. 3295531151201648 x 12/17 121 begin march 1st. email to isnd nat gen 25/50 11.65 down and 18.53 monthly. Natl Gen - 6 mo, $101 Allied - 6 mo, $11.06 Foremost - 6 mo, $15 william: 4dob 1/4/2011, L522-121-59-094-0 2015 Ford Fiesta 2 accident. POI w/ Direct General paying 181. Assume 11/150/10, quote 30/60')
INSERT INTO #payments values (6, 'need to rit 5010440064321111 11/18 385')
select * from #paymentsexpected numbers from above is 16 digits or more (continuous numeric value) spaces ok but no other characters
8787082513313224314
please Ignore any number with *.pdf or *.jpg so it has to get the next 16 digit number if any so here 3412123412341234
4482501239835011
3482568639165011
3295531151201648
5010440064321111
just would like to extract any continuous number that is 16 Digits or more (continuous number) other wise ignore. the first occurance of 16 Digits or more.
Thank you,
Milan
-
I tried and generated code this far.
SELECT Comment,
(CASE WHEN Comment LIKE '%[0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9]%'
THEN substring(Comment, patindex('%[0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9]%', Comment), 17)
WHEN Comment LIKE '%[0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9]%'
THEN substring(Comment, patindex('%[0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9]%', Comment), 16)
END) AS NumberOnly
into #a1
FROM #Paymentsplease help if I am missing anything here. Thanks
Thanks
-
In this case I would start splitting the comment based on a space.
check "Tally OH! An Improved SQL 8K “CSV Splitter” Function"
and process the spliter results for the number of digits you want.
This is a typical column that should be implemented using xml of json because now you are just searching for a number in a string. That number may not even be the identifier you are looking for.
Johan
Learn to play, play to learn !Dont drive faster than your guardian angel can fly ...
but keeping both feet on the ground wont get you anywhere :w00t:- How to post Performance Problems
- How to post data and code to get the best help- How to prevent a sore throat after hours of presenting ppt
press F1 for solution, press shift+F1 for urgent solution 😀
Who am I ? Sometimes this is me but most of the time this is me
- Johan Bijnens wrote:
In this case I would start splitting the comment based on a space.
check "Tally OH! An Improved SQL 8K “CSV Splitter” Function"
and process the spliter results for the number of digits you want.
This is a typical column that should be implemented using xml of json because now you are just searching for a number in a string. That number may not even be the identifier you are looking for.
I agree that this is a good starting point, but as this is a 2022 forum, the native STRING_SPLIT() function will also do the job.
- Phil Parkin wrote:Johan Bijnens wrote:
In this case I would start splitting the comment based on a space.
check "Tally OH! An Improved SQL 8K “CSV Splitter” Function"
and process the spliter results for the number of digits you want.
This is a typical column that should be implemented using xml of json because now you are just searching for a number in a string. That number may not even be the identifier you are looking for.
I agree that this is a good starting point, but as this is a 2022 forum, the native STRING_SPLIT() function will also do the job.
Good point.
BTW, I didn't pay attention to it, but don't use data type TEXT !
Use varchar(max) as text has been deprecated for years ! ( and string_split doesn't accept data type text )
Johan
Learn to play, play to learn !Dont drive faster than your guardian angel can fly ...
but keeping both feet on the ground wont get you anywhere :w00t:- How to post Performance Problems
- How to post data and code to get the best help- How to prevent a sore throat after hours of presenting ppt
press F1 for solution, press shift+F1 for urgent solution 😀
Who am I ? Sometimes this is me but most of the time this is me
- Johan Bijnens wrote:Phil Parkin wrote:Johan Bijnens wrote:
In this case I would start splitting the comment based on a space.
check "Tally OH! An Improved SQL 8K “CSV Splitter” Function"
and process the spliter results for the number of digits you want.
This is a typical column that should be implemented using xml of json because now you are just searching for a number in a string. That number may not even be the identifier you are looking for.
I agree that this is a good starting point, but as this is a 2022 forum, the native STRING_SPLIT() function will also do the job.
Good point.
BTW, I didn't pay attention to it, but don't use data type TEXT ! Use varchar(max) as text has been deprecated for years ! ( and string_split doesn't accept data type text )
Heh... while I appreciate the functionality that the MAX datatypes brought to the table, they did so with a really nasty hidden fault... they default to "In Row". That is responsible for the likes of "Trapped Short Rows", Insert/Update pairs of operations that now produce "ExpAnsive" updates where they didn't used to, much slower Clustered Index Range Scans, and a wealth of other pains.
No... those are not reasons to use the TEXT, NTEXT, or IMAGE datatypes. They are reasons to be aware of the hidden joys that those datatypes provided and to design their "Default Out-of-Row" nature into your newer LOBs, including XML and, possibly, most variable length columns over 200 characters, and even some shorter variable width columns such as "Modified_BY" types of columns.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Possible solution to the original question...
Given the original example data...
Create Table #Payments (ID int, Comment Text)
INSERT INTO #payments values (1, '65607 Processed via? DISC Last 4 digits of credit card:7144 Last 4 digits of checking account: Confirmation number: 8787082513313224314 Receipt sent? No CSR: Charlett')
INSERT INTO #payments values (2, 'HO_QuoteOutput_11131_0.5509311349467635_1.pdf Category: QUOTE SubCategory: Card is 3412123412341234')
INSERT INTO #payments values (3, '11/28/12 auto rnwl /// paid in full #4482501239835011 x 5/14 paid in full emld receipt')
INSERT INTO #payments values (4, 'Processed CC payment of $514.24 per webiste Confirmation number: 08748C 3482568639165011 Processed check of $64 per feat website Confirmation Number: 9019991201')
INSERT INTO #payments values (5, '2/26 left a message for william. 3295531151201648 x 12/17 121 begin march 1st. email to isnd nat gen 25/50 11.65 down and 18.53 monthly. Natl Gen - 6 mo, $101 Allied - 6 mo, $11.06 Foremost - 6 mo, $15 william: 4dob 1/4/2011, L522-121-59-094-0 2015 Ford Fiesta 2 accident. POI w/ Direct General paying 181. Assume 11/150/10, quote 30/60')
INSERT INTO #payments values (6, 'need to rit 5010440064321111 11/18 385')
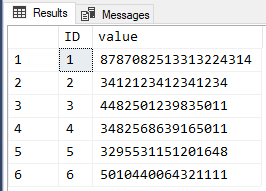
select * from #payments... the following code will work in SQL Server 2017 and up...
SELECT ID
,clean.value
FROM #Payments
CROSS APPLY STRING_SPLIT(CONVERT(VARCHAR(MAX),Comment),' ') split
CROSS APPLY (VALUES (TRIM('#' FROM split.value)))clean(value)
WHERE LEN(clean.value) >= 16
AND clean.value NOT LIKE '%[^0-9]%'
;... and returns the following results...

--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Nice. Thanks, Jeff, for reminding me that TRIM() could remove more than just beginning and trailing space characters
Viewing 8 posts - 1 through 8 (of 8 total)
You must be logged in to reply to this topic. Login to reply