Return
-
Self taught novice learning SQL and would welcome some help with the following code problem
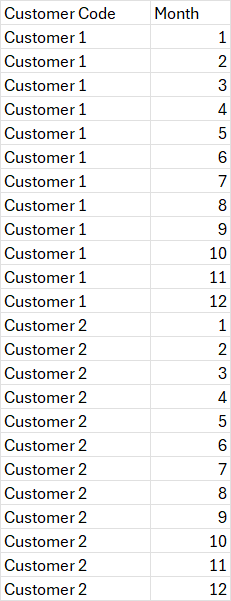
In my data set I have one record per customer but would like my select query to return 12 rows for each customer record in the data set. e.g. If I have 2 customers I would end up with 24 rows of data. I have mocked up an expected result below.
Is this possible?

-
Does this work?
SELECT a.CustomerCode,
b.MonthNum
FROM dbo.Customers AS A
CROSS JOIN (VALUES (1),(2),(3),(4),(5),(6),(7),(8),(9),(10),(11),(12)) AS b (MonthNum) -
I haven't explained very well - the second column isn't coming from another table, so there's nothing to join to - I am effectively wanting to create the second column within the query. My simple brain was assuming some form of loop? If this was Excel VBA I would probably use For/Next with 12 iterations to create the rows, but I don't know how to replicate that in SQL.
- Cybodz wrote:
but I don't know how to replicate that in SQL.
Run Ed B's code.
In future, provide a test rig and test answers before answering. If you do not know how to provide a test rig google 'How to ask a question on a SQL Forum'.
- Cybodz wrote:
I haven't explained very well - the second column isn't coming from another table
The second column is coming from a derived table. You could write a loop or use a recursive common table expression, but that's more effort, more code and less almost always efficient. T-SQL works best with sets so in this scenario we create a set to join to.
SELECT b.*
FROM (VALUES (1),(2),(3),(4),(5),(6),(7),(8),(9),(10),(11),(12)) AS b (MonthNum)CROSS APPLY also works.
DROP TABLE IF EXISTS #Customers
CREATE TABLE #Customers
(CustomerId INT,
CustomerCode VARCHAR(20)
)
INSERT #Customers VALUES (1, 'Customer1'), (2,'Customer2'), (3, 'Customer3'), (4,'Customer4');
SELECT a.CustomerCode,
b.MonthNum
FROM #Customers AS a
CROSS APPLY (VALUES (1),(2),(3),(4),(5),(6),(7),(8),(9),(10),(11),(12)) AS b (MonthNum) -
;WITH CTE AS
(
SELECT DISTINCT CustomerCode
FROM myTable
)
SELECT B.*
FROM CTE A
CROSS APPLY(SELECT TOP(12) *
FROM myTable
WHERE B.CustomerCode = A.CustomerCode
ORDER BY myColumn DESC -- Put whatever you want to order by
) B
ORDER BY B.CustomerCode, B.myColumn
; - Jonathan AC Roberts wrote:
;WITH CTE AS
(
SELECT DISTINCT CustomerCode
FROM myTable
)
SELECT B.*
FROM CTE A
CROSS APPLY(SELECT TOP(12) *
FROM myTable
WHERE B.CustomerCode = A.CustomerCode
ORDER BY myColumn DESC -- Put whatever you want to order by
) B
ORDER BY B.CustomerCode, B.myColumn
;I don't think that this is what the OP was looking for, but if it were, it's not the most efficient way. This way would be better:
;WITH CTE AS
(
SELECT *
, ROW_NUMBER() OVER(PARTITION BY CustomerCode ORDER BY myColumn) AS rn
FROM myTable
)
SELECT A.*
FROM CTE A
WHERE a.rn <= 12
;Drew
J. Drew Allen
Business Intelligence Analyst
Philadelphia, PA -
As it is in the 2022 forum there's always GENERATE_SERIES to come up with the Month numbers in the query. Assuming CustomerCode is not unique in the source table. I have never used generate_series before, but I think this works.
DROP TABLE IF EXISTS #Invoices
CREATE TABLE #Invoices
( InvoiceID INT,
CustomerCode VARCHAR(20),
InvoiceDate DATE
);
INSERT #Invoices VALUES (1, 'Customer1', '2023-12-01'), (2,'Customer1', '2023-12-02'), (3, 'Customer1', '2012-12-03'), (4,'Customer2', '2023-11-29');
SELECT a.CustomerCode,
b.[Value] AS 'Month'
FROM (SELECT DISTINCT CustomerCode FROM #Invoices) AS a
CROSS APPLY GENERATE_SERIES (1, 12, 1) AS b; - drew.allen wrote:Jonathan AC Roberts wrote:
;WITH CTE AS
(
SELECT DISTINCT CustomerCode
FROM myTable
)
SELECT B.*
FROM CTE A
CROSS APPLY(SELECT TOP(12) *
FROM myTable
WHERE B.CustomerCode = A.CustomerCode
ORDER BY myColumn DESC -- Put whatever you want to order by
) B
ORDER BY B.CustomerCode, B.myColumn
;I don't think that this is what the OP was looking for, but if it were, it's not the most efficient way. This way would be better:
;WITH CTE AS
(
SELECT *
, ROW_NUMBER() OVER(PARTITION BY CustomerCode ORDER BY myColumn) AS rn
FROM myTable
)
SELECT A.*
FROM CTE A
WHERE a.rn <= 12
;Drew
Yes, that's a bit shorter and generally more efficient. I'm wondering if there were a lot more that 12 items per customer and the right indexes on the table if my method would be more efficient though.
But re-looking at the question and the OP's other response there isn't a months column, the OP wants to generate the 12 items of each customer. So Ed B's answer is probably the best.
- Jonathan AC Roberts wrote:
Yes, that's a bit shorter and generally more efficient. I'm wondering if there were a lot more that 12 items per customer and the right indexes on the table if my method would be more efficient though.
I would be very surprised if it were. Your method requires two table/index scans, whereas mine only requires one. Any possible index that would improve your query, would also improve mine. I just don't see any way that your query can make up for the required extra scan.
Drew
J. Drew Allen
Business Intelligence Analyst
Philadelphia, PA - drew.allen wrote:Jonathan AC Roberts wrote:
Yes, that's a bit shorter and generally more efficient. I'm wondering if there were a lot more that 12 items per customer and the right indexes on the table if my method would be more efficient though.
I would be very surprised if it were. Your method requires two table/index scans, whereas mine only requires one. Any possible index that would improve your query, would also improve mine. I just don't see any way that your query can make up for the required extra scan.Drew
To set the data up I put 10,000 rows of myColumn for each customer code and created an appropriate index:
SET STATISTICS IO, TIME OFF
DROP TABLE IF EXISTS #myTable;
CREATE TABLE #myTable
(
CustomerCode varchar(20),
myColumn int
);
INSERT INTO #myTable(CustomerCode, myColumn)
SELECT CONCAT('Customer', right('000000' + a.value, 5)) CustomerCode,
b.value AS myColumn
FROM GENERATE_SERIES(1,1000) a
CROSS APPLY(SELECT b.value FROM GENERATE_SERIES(1,10000) b) b;
CREATE INDEX ix_#myTable_1 ON #myTable(CustomerCode, myColumn);
go
DROP TABLE IF EXISTS #R1;
DROP TABLE IF EXISTS #R2;
DROP TABLE IF EXISTS #R3;Then tested the two queries:
SET STATISTICS IO, TIME ON;
;WITH CTE AS
(
SELECT DISTINCT CustomerCode
FROM #myTable
)
SELECT B.*
INTO #R1
FROM CTE A
CROSS APPLY(SELECT TOP(12) *
FROM #myTable B
WHERE B.CustomerCode = A.CustomerCode
ORDER BY B.myColumn -- Put whatever you want to order by
) B
ORDER BY B.CustomerCode, B.myColumn
;
GO
;WITH CTE AS
(
SELECT *,
ROW_NUMBER() OVER(PARTITION BY CustomerCode ORDER BY myColumn) AS rn
FROM #myTable
)
SELECT A.CustomerCode, A.myColumn
INTO #R2
FROM CTE A
WHERE a.rn <= 12
;The timings on my machine for the methods are 736 ms for my method (cross apply) and 1141 ms for the ROW_NUMBER() method.
I also tried using a fast recursive CTE method for obtaining distinct CustomerCode then using cross apply which was 20 times faster at 36 ms:
WITH rCTE AS
(
-- Anchor
SELECT A.CustomerCode
FROM #myTable AS A
ORDER BY A.CustomerCode ASC OFFSET 0 ROWS FETCH FIRST 1 ROW ONLY
UNION ALL
-- Recursive
SELECT B.CustomerCode
FROM (SELECT A.CustomerCode,
ROW_NUMBER() OVER (ORDER BY A.CustomerCode ASC) rn
FROM rCTE
INNER JOIN #myTable AS A
ON A.CustomerCode > rCTE.CustomerCode) AS B
WHERE B.rn = 1
)
SELECT B.*
INTO #R3
FROM rCTE A
CROSS APPLY(SELECT TOP(12) *
FROM #myTable B
WHERE B.CustomerCode = A.CustomerCode
ORDER BY B.myColumn -- Put whatever you want to order by
) B
ORDER BY B.CustomerCode, B.myColumn
OPTION (MAXRECURSION 0)
; -
Thanks all for your responses and I can confirm Ed B's solution did what I needed.
Viewing 12 posts - 1 through 12 (of 12 total)
You must be logged in to reply to this topic. Login to reply