Query related issue
-
I have a small query that runs in 1 sec. See an example below.
Use DB1
GO
select EMPLD, FirstName, Lastname
from DB1..Employee
where dept = 'IT'But when I run the same query on the same server but in a different database, it takes 10x + more.
Use DB2
GO
select EMPLD, FirstName, Lastname
from DB1..Employee
where dept = 'IT'I am trying to learn and understand. Any feedback/comment is highly appreciated.
"He who learns for the sake of haughtiness, dies ignorant. He who learns only to talk, rather than to act, dies a hyprocite. He who learns for the mere sake of debating, dies irreligious. He who learns only to accumulate wealth, dies an atheist. And he who learns for the sake of action, dies a mystic."[/i]
-
I changed the Legacy cardinality Estimation setting to ON and now both queries are taking the same time.
"He who learns for the sake of haughtiness, dies ignorant. He who learns only to talk, rather than to act, dies a hyprocite. He who learns for the mere sake of debating, dies irreligious. He who learns only to accumulate wealth, dies an atheist. And he who learns for the sake of action, dies a mystic."[/i]
-
My opinion, turning on the legacy cardinality estimator is more of a band-aid solution and it will fail in a future upgrade to SQL server as Microsoft isn't going to maintain 2+ cardinality estimators forever.
If I had to guess as to why it was slow, it is because with the first query you are doing an in-database query. In the second, you are doing a cross database query. The second query has no access to the statistics in DB1, so performance is going to be worse. And if the settings on the databases are different, such as the compatibility level, that will impact performance as well. Depending on the SQL server version, the query optimizer will estimate the number of rows it will get back, but with a cross database query, that is just some hard-coded number. Older SQL versions use a value of 1, while newer versions use a larger number that I forget offhand.
I would start by making sure the legacy cardinality estimator is off on both databases and that both are at the same compatibility level and then have a look at the actual execution plan to see why it is slow. May want to check your MAXDOP settings too and your cost threshold for parallelism as it COULD be the query is going parallel and the table isn't supporting it resulting in a lot of self-blocking.
I would strongly encourage you NOT to turn on the legacy cardinality estimator. My opinion, that is more of a short term fix when you run into upgrade issues until you can correct your queries, and the query you provided I see no reason why you would want that to be a cross database query. I see no benefit in having it be cross database. If it needs to be cross database, I would look at pulling the entire table from DB1 into DB2 as a temporary object in your stored procedure (temp table or table variable) and running your queries against the temporary object.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
As a bit of a sidebar, I've not found any performance improvement that I can relate to the "new" CE but have a whole bunch of slowdowns that I can attribute to it.
Between things like that and the massive slowdowns encountered when we migrated to 2022 from 2016, and other code that breaks stuff like not being even to temporarily disable the "TF1117" functionality that was built into SQL, I'm losing a whole lot more faith in MS than I ever have before.
And, on the Legacy CE thing... we had to turn it on when we migrated to 2016 in 2017 because there's just not enough time to rework nearly every bloody bit of SQL that had been running quite nicely for almost a decade before that. 7 Years later, we still don't have time but it no longer helps in 2022 because of the "improvements" that they made.
And, sorry... all that automatic tuning stuff seems to be for the birds.
And, yep... we did some testing with other folks and this all actually started in 2019... and they still haven't fixed the performance issues.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
I'd need to see the execution plans to understand what's going on. Further, two different databases means, possibly, two different sets of data, two different sets of statistics, two different structures, and even as you're implying, two different sets of database settings. When things are not absolutely identical in every regard, comparing performance becomes problematic. Look to the execution plan to understand how the query is being resolved.
"The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood"
- Theodore RooseveltAuthor of:
SQL Server Execution Plans
SQL Server Query Performance Tuning -
@Grant Fritchey - pretty sure it is a cross database query (use db2, select from db1), so it should be using the same set of data and data structure, but if memory serves, cross database queries can't use statistics on the remote database. And, like you said, different database settings can cause problems too.
In general, I try to avoid cross database queries if possible. If not possible, then things can get messy trying to tune it. SOMETIMES pulling all the data into a temporary object is faster than querying across databases; sometimes openquery is faster than directly referencing the table; sometimes it may be easier to handle it application side and just have 2 query calls (one to each database) then let the application do what it needs to with the data.
But yes, actual execution plan is the best starting point to see why things are slow. My GUESS is that due to a bad estimated number of rows it had a bad estimated memory required and needed to request more memory repeatedly causing the slowdown. BUT that is just a guess...
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. - Mr. Brian Gale wrote:
@Grant Fritchey - pretty sure it is a cross database query (use db2, select from db1), so it should be using the same set of data and data structure, but if memory serves, cross database queries can't use statistics on the remote database. And, like you said, different database settings can cause problems too.
that is true for remote server queries - but for db's on same instance I do not believe it applies as I do heavily query cross db's in some of the work I do and statistics are used from all tables involved on the query, from both the db where query is executed and the remaining db's
-
Connection settings, others. It's something.
"The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood"
- Theodore RooseveltAuthor of:
SQL Server Execution Plans
SQL Server Query Performance Tuning -
Compatibility mode?
Sidebar: stop using DB..Table - specify the schema instead of expecting SQL Server to find the correct schema for the table. That is dependent on the default schema setting for the user - which may or may not be set in each database. It can also cause multiple execution plans to be generated - based on the default schema of the user executing the query.
Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs - Jeffrey Williams wrote:
Compatibility mode?
Sidebar: stop using DB..Table - specify the schema instead of expecting SQL Server to find the correct schema for the table. That is dependent on the default schema setting for the user - which may or may not be set in each database. It can also cause multiple execution plans to be generated - based on the default schema of the user executing the query.
I can't give this the thousand likes it deserves.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Grant Fritchey wrote:
I'd need to see the execution plans to understand what's going on. Further, two different databases means, possibly, two different sets of data, two different sets of statistics, two different structures, and even as you're implying, two different sets of database settings. When things are not absolutely identical in every regard, comparing performance becomes problematic. Look to the execution plan to understand how the query is being resolved.
How about a single piece of code? This is part of the package I'm working on to submit to Mr. Ward. It's some of the simplest code possible that clearly demonstrates the problem. Both the 2017 and 2022 instances of the Developer Edition live on the same laptop and use exactly the same SSDs for "disks" and there's no network involved or any of the other "excuses" that people try to blame us users for. 😉
Here's the code that was executed on both the 2017 and 2022 instances:
CHECKPOINT;
DBCC FREEPROCCACHE;
DBCC DROPCLEANBUFFERS;
CHECKPOINT;
GO
DECLARE @BitBucket BIGINT
;
SET STATISTICS TIME ON;
WITH
H1(N) AS (SELECT 1 FROM (VALUES (1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1))H0(N)) --Up to 16 rows
,Tally(N) AS (
SELECT TOP(100000000) --Change this number
N = ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
FROM H1 a,H1 b,H1 c,H1 d,H1 e,H1 f,H1 g,H1 h --1 to 16^8 or 4,294,967,296 rows max
)
SELECT @BitBucket = N FROM Tally
OPTION (MAXDOP 4); --Change the MAXDOP as you see fit. This is the default on my server.
SET STATISTICS TIME OFF;
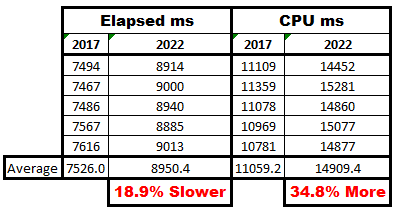
GO 5Here are the cleaned up statistics from the output as well as a super simple analysis:
With the help of another individual who has servers from 2012 through 2022, similar results have been found. For all servers prior to 2019, the results beat the 2019/2022 instances with similar percentages. And I get nearly identical numbers to the 2022 numbers when I switched the database to the 2017 comparability level. Even if that had helped, though, it would be totally unacceptable because we want to use the new functionality offered in 2022!
I'm working on a comparison of job durations (all of them) between SQL Server 2016 (from a copy of the MSDB still stored in the old backups for 2016) and SQL Server 2022 because a lot of our production jobs now take a lot longer and now continue into the "normal operational hours", which is totally unsatisfactory. We have similar issues with the daily online code but I didn't track that as carefully on 2016. AND, changing the databases to the 2016 comparability only solved the massive blocking that we were getting... it didn't solve the performance issues.
And, no... I'm not looking forward to redacting more than a decade of a lot of old code that has survived upgrades to 2012 and 2016.
We're setting up to apply CU 9 or 10 (if the latter comes out in time) during next month's Windows Updates. We're currently at CU3 but have been putting off all CUs because of the things serious issues that came to light with CU4 and appeared to have continued issues with CU5 and CU6. I seriously hope a good number of the performance issues are fixed but, even if they are...
IMHO, Microsoft has seriously violated Rule #1 when it comes to supposed "improvements and new features"... "Above all else, cause no harm".
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
 I
I Viewing 11 posts - 1 through 11 (of 11 total)
You must be logged in to reply to this topic. Login to reply