Select a distinct list of values from tables, return the dataset
-
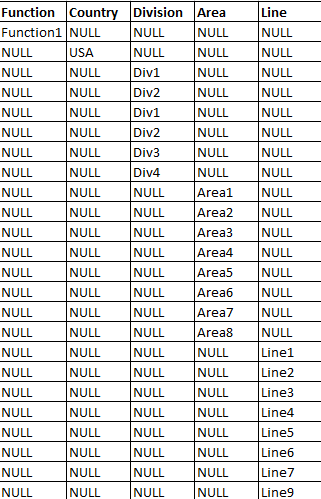
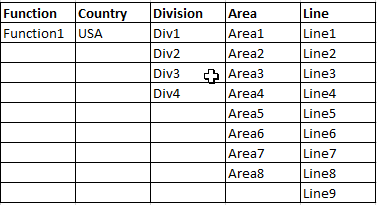
I am trying to select a distinct list of values from multiple tables, combine them into a single table with all data starting in row one instead of the data being returned on new rows for each distinct data set.
This is what I am current getting by using a union:

This is how I need the data to be presented:
Any help anyone could give would be greatly appreciated.
Thanks
-
I assume you could have a Function2 and then data for it. If so, there needs to be something to order the rows: an identity column, a datetime, etc.. Do you have such a column, and what's its name?
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
Here is a cut-down example, which you should be able to expand to do what you want. There is much that can be done to refine it, but as it stands, it assumes that you know in advance which of the columns has the most distinct items ('Line' in your example, but 'Division' in mine).
DROP TABLE IF EXISTS #Fn;
CREATE TABLE #Fn
(
Fn VARCHAR(20)
,Country VARCHAR(20)
,Division VARCHAR(20)
);
INSERT #Fn
(
Fn
,Country
,Division
)
VALUES
('Function1', NULL, NULL)
,('Function2', NULL, NULL)
,('Function2', NULL, NULL)
,('Function3', NULL, NULL)
,(NULL, 'USA', NULL)
,(NULL, 'UK', NULL)
,(NULL, 'Eswatini', NULL)
,(NULL, NULL, 'Div1')
,(NULL, NULL, 'Div2')
,(NULL, NULL, 'Div2')
,(NULL, NULL, 'Div4')
,(NULL, NULL, 'Div5')
,(NULL, NULL, 'Div6')
,(NULL, NULL, 'Div3')
,(NULL, NULL, 'Div8')
,(NULL, NULL, 'Div9');
DROP TABLE IF EXISTS #Fn2;
CREATE TABLE #Fn2
(
Id INT IDENTITY(1, 1)
,Fn VARCHAR(20)
,Country VARCHAR(20)
,Division VARCHAR(20)
);
INSERT #Fn2
(
Division
)
SELECT DISTINCT
f.Division
FROM #Fn f
WHERE f.Division IS NOT NULL;
WITH Ordered1
AS (SELECT rn = ROW_NUMBER () OVER (ORDER BY F.Fn)
,F.Fn
FROM
(SELECT DISTINCT f2.Fn FROM #Fn f2) F
WHERE F.Fn IS NOT NULL)
,Ordered2
AS (SELECT rn = ROW_NUMBER () OVER (ORDER BY F.Country)
,F.Country
FROM
(SELECT DISTINCT f2.Country FROM #Fn f2) F
WHERE F.Country IS NOT NULL)
UPDATE f2
SET f2.Fn = Ordered1.Fn
,f2.Country = Ordered2.Country
FROM #Fn2 f2
LEFT JOIN Ordered1
ON Ordered1.rn = f2.Id
LEFT JOIN Ordered2
ON Ordered2.rn = f2.Id;
SELECT Fn = ISNULL (f.Fn, '')
,Country = ISNULL (f.Country, '')
,Division = ISNULL (f.Division, '')
FROM #Fn2 f
ORDER BY f.Id; - Phil Parkin wrote:
... it assumes that you know in advance which of the columns has the most distinct items ('Line' in your example, but 'Division' in mine).
One way to generalize the query could be to generate the base sequence using a numbers table or tally function. Then LEFT JOIN each of the categorical tables on row number
/* with a numbers table */
with
nums_cte(n) as (
select *
from (values (1),(2),(3),(4),(5),(6),(7),(8),(9),(10),(11),(12)) v(n)),
fn_cte(Fn, rn) as (
select distinct Fn, row_number() over (order by Fn)
from #Fn
where Fn is not null),
cnty_cte(Country, rn) as (
select distinct Country, row_number() over (order by Country)
from #Fn
where Country is not null),
div_cte(Division, rn) as (
select distinct Division, row_number() over (order by Division)
from #Fn
where Division is not null),
max_rn_cte(max_rn) as (
select max(cat.rn)
from (select max(rn) from fn_cte
union all
select max(rn) from cnty_cte
union all
select max(rn) from div_cte) cat(rn))
select base_seq.N,
isnull(fn.Fn, '') Fn,
isnull(cnty.Country, '') Country,
isnull(div.Division, '') Division
from max_rn_cte mx
cross apply (select top(mx.max_rn) n
from nums_cte) base_seq(n)
left join fn_cte fn on base_seq.N=fn.rn
left join cnty_cte cnty on base_seq.N=cnty.rn
left join div_cte div on base_seq.N=div.rn;
/* with a tally function or GENERATE_SERIES */
with
fn_cte(Fn, rn) as (
select distinct Fn, row_number() over (order by Fn)
from #Fn
where Fn is not null),
cnty_cte(Country, rn) as (
select distinct Country, row_number() over (order by Country)
from #Fn
where Country is not null),
div_cte(Division, rn) as (
select distinct Division, row_number() over (order by Division)
from #Fn
where Division is not null),
max_rn_cte(max_rn) as (
select max(cat.rn)
from (select max(rn) from fn_cte
union all
select max(rn) from cnty_cte
union all
select max(rn) from div_cte) cat(rn))
select base_seq.N,
isnull(fn.Fn, '') Fn,
isnull(cnty.Country, '') Country,
isnull(div.Division, '') Division
from max_rn_cte mx
cross apply dbo.fnTally(1, mx.max_rn) base_seq
left join fn_cte fn on base_seq.N=fn.rn
left join cnty_cte cnty on base_seq.N=cnty.rn
left join div_cte div on base_seq.N=div.rn;Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
-
For over 30 years, the convention on SQL forums has been to post DDL (so we know what the keys are the datatypes of columns, any important constraints, etc.) and in the effort. The poster made on their own to solve their own problem. What you posted. It really isn't even SQL ! Did you know the table has to have a key? This is not an option, but a fundamental definition of a table.
Then after you get that stuff correct, you don't seem to understand that SQL was never intended to be used for formatting. That's why we have a tiered architecture and a presentation layer. What you did post looks strangely like some of the report options in COBOL! Especially the blank ed cells on your spreadsheet. Those are straight out of the COBOL report writer.
Would you like to start over and do it correctly?
Please post DDL and follow ANSI/ISO standards when asking for help.
-
This produces the same results as Phil's. I made some assumptions that may not be warranted.
- Assumed that all fields were VARCHAR (or NVARCHAR)
- It will work (with modifications) as long as they are all the same data type.
- Assumed that only one field in each record contains data.
- A slight modification will handle it if multiple fields contain data.
WITH Categories AS
(
SELECT *, DENSE_RANK() OVER(PARTITION BY cat.category ORDER BY COALESCE(f.Fn, f.Country, f.Division, CHAR(255))) AS rn
FROM #Fn AS f
CROSS APPLY (VALUES(CASE WHEN f.Fn IS NOT NULL THEN 'Function'
WHEN f.Country IS NOT NULL THEN 'Country'
WHEN f.Division IS NOT NULL THEN 'Division'
END
)
) cat(category)
)
SELECT c.rn, MIN(c.fn) AS Fn, MIN(c.Country) AS Country, MIN(c.Division) AS Division
FROM Categories AS c
GROUP BY c.rn
ORDER BY c.rnDrew
J. Drew Allen
Business Intelligence Analyst
Philadelphia, PA - Assumed that all fields were VARCHAR (or NVARCHAR)
Viewing 6 posts - 1 through 6 (of 6 total)
You must be logged in to reply to this topic. Login to reply