Data file shrink taking long time
-
Hi All,
I am trying shrink a 10TB data file. During the weekend patching window we have planned to shrink the file as it filled up the entire 11TB drive.
We have purged some data and we are trying to shrink the file. Doing so, it is taking more time. (i.e. > 9 hours).
This is db is in synchronous AG and has some open connections as well now and then.
Couple of questions I have.
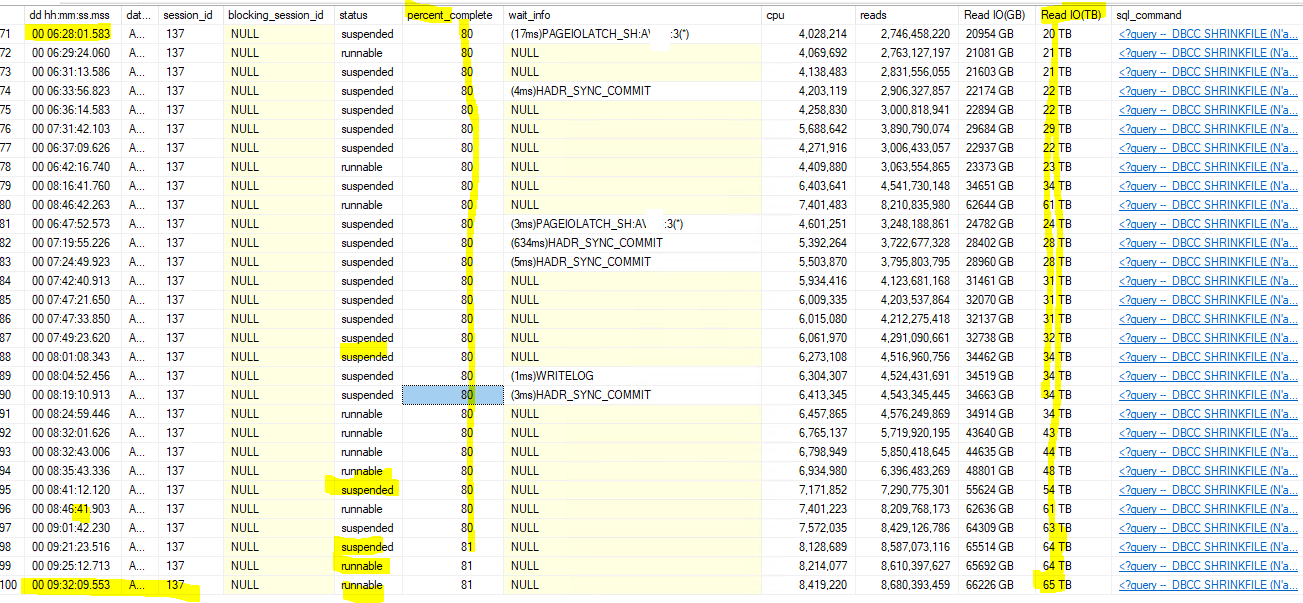
1. the total database is 10TB but why it is doing 65TB IO. PFA sp_whoisactive screenshot which i collected like every 5 mins.
2. The progress started at 80% but it took 9 hours to move 1% . Dont know why?
3. What is the best way to shrink the file? take full backup, remove it from AG, change it simple recovery model, shrink the file, once shrink is done, change recovery model to full, take a full backup, restore it all the secondary with norecovery and at it back to AG. Is this a good idea or any other better approaches to handle this.
--Shrink command we have run.
<?query --
DBCC SHRINKFILE (N'db2_dat' , 8388608)
--?>

Regards,
Sam
-
There are a couple of options:
- Add a new file to the filegroup sized at 1TB with a large auto growth setting (20GB or more). Issue a DBCC SHRINKFILE on the existing file with the EMPTYFILE option. Once the system has moved all of the existing data over to the new file - remove the old file.
- Create a new filegroup and file for that database and start it at 1TB with a large auto growth setting. Recreate the tables and indexes on this new filegroup using CREATE with DROP_EXISTING. Once all tables and objects have been moved - shrink the original file in the original PRIMARY filegroup to as small as it will allow (which should now be an easy process since the file will be empty or mostly empty).
The reason I would start at around 1TB is because it is likely that the tables/indexes are highly fragmented - and moving the data should compress the data on the pages. If you know that this will result in 2TB of data - then you could size the new file at 2.5TB which would allow for future growth.
Option 2 opens up the possibility of moving the largest tables to a separate filegroup - which can be created on a dedicated volume (disk or mount point). That would allow more flexibility in the future for managing the growth for those specific tables - where you could then create another filegroup and file and 'swap' the table(s) using a CREATE with DROP_EXISTING method. That would rebuild the indexes onto the new filegroup instead of trying to rebuild the indexes within the existing file.
Option 1 basically leaves the database in the same state - just with a new file name. This option also allows for 'moving' the data to a new volume (drive or mount point) which could be a dedicated volume specific to this one database.
Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs -
It took 14 hours to complete.
- Jeffrey Williams wrote:
There are a couple of options:
- Add a new file to the filegroup sized at 1TB with a large auto growth setting (20GB or more). Issue a DBCC SHRINKFILE on the existing file with the EMPTYFILE option. Once the system has moved all of the existing data over to the new file - remove the old file.
- Create a new filegroup and file for that database and start it at 1TB with a large auto growth setting. Recreate the tables and indexes on this new filegroup using CREATE with DROP_EXISTING. Once all tables and objects have been moved - shrink the original file in the original PRIMARY filegroup to as small as it will allow (which should now be an easy process since the file will be empty or mostly empty).
The reason I would start at around 1TB is because it is likely that the tables/indexes are highly fragmented - and moving the data should compress the data on the pages. If you know that this will result in 2TB of data - then you could size the new file at 2.5TB which would allow for future growth.
Option 2 opens up the possibility of moving the largest tables to a separate filegroup - which can be created on a dedicated volume (disk or mount point). That would allow more flexibility in the future for managing the growth for those specific tables - where you could then create another filegroup and file and 'swap' the table(s) using a CREATE with DROP_EXISTING method. That would rebuild the indexes onto the new filegroup instead of trying to rebuild the indexes within the existing file.
Option 1 basically leaves the database in the same state - just with a new file name. This option also allows for 'moving' the data to a new volume (drive or mount point) which could be a dedicated volume specific to this one database.
Thank you Jeff.
-
Another thing to add to your list is a nightly file usage check. That should also include a "Page Density" check on your indexes and heaps. Your infrastructure guys should also be doing this as a matter of rote. If you actually did run out of space, then they're obviously not checking and the puts the onus on you, Sam.
Actually, that onus has always been on you, Sam. Like having a restore plan, every DBA should make sure that they're not going to run out of space sometime in the next 3-6 months.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)

Viewing 5 posts - 1 through 5 (of 5 total)
You must be logged in to reply to this topic. Login to reply