extracting data from JSON with TSQL
-
Hi,
I need help extracting data from the below JSON.
What I need is the data from the "frequencyData" array.
on the
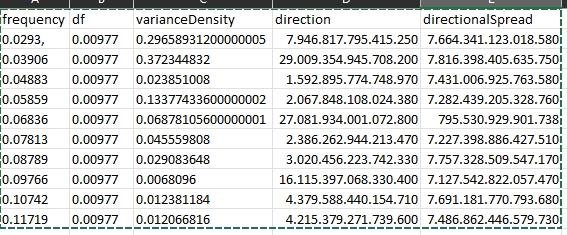
first row of the resultset I would like the first column to contain the first data sample of the "frequency"child array,
the second column should contain the first data sample of the "df" child array,
the third column should contain the first data sample of the "varianceDensity" child array,
the fourth column should contain the first data sample of the "direction" child array,
the fifth column should contain the first data sample of the "directionalSpread" child array
The second row should contain the second datasamples from the same arrays as mentioned above
The TSQL that I am trying to write should return a table like this:

declare @json nvarchar(max)
set @json = '
{
"data": {
"spotterId": "SPOT-31092C",
"spotterName": "",
"payloadType": "full",
"batteryVoltage": 3.18,
"batteryPower": -0.22,
"solarVoltage": 3.21,
"humidity": 19.05,
"track": [
{
"latitude": 27.8570935,
"longitude": -15.3972193,
"timestamp": "2023-08-27T08:35:00.000Z"
},
{
"latitude": 27.8570858,
"longitude": -15.3972307,
"timestamp": "2023-08-27T08:40:00.000Z"
},
{
"latitude": 27.8570303,
"longitude": -15.3972705,
"timestamp": "2023-08-27T08:45:00.000Z"
},
{
"latitude": 27.857188,
"longitude": -15.3971523,
"timestamp": "2023-08-27T08:50:00.000Z"
},
{
"latitude": 27.857077,
"longitude": -15.3972452,
"timestamp": "2023-08-27T08:55:00.000Z"
},
{
"latitude": 27.8570332,
"longitude": -15.3972945,
"timestamp": "2023-08-27T09:00:00.000Z"
}
],
"waves": [
{
"significantWaveHeight": 0.44,
"peakPeriod": 25.602,
"meanPeriod": 12.151,
"peakDirection": 290.094,
"peakDirectionalSpread": 78.164,
"meanDirection": 15.1,
"meanDirectionalSpread": 77.209,
"timestamp": "2023-08-27T09:00:00.000Z",
"latitude": 27.85703,
"longitude": -15.39729
}
],
"frequencyData": [
{
"frequency": [
0.0293,
0.03906,
0.04883,
0.05859,
0.06836,
0.07813,
0.08789,
0.09766,
0.10742,
0.11719
],
"df": [
0.00977,
0.00977,
0.00977,
0.00977,
0.00977,
0.00977,
0.00977,
0.00977,
0.00977,
0.00977
],
"varianceDensity": [
0.29658931200000005,
0.372344832,
0.023851008,
0.13377433600000002,
0.06878105600000001,
0.045559808,
0.029083648,
0.0068096,
0.012381184,
0.012066816
],
"direction": [
7.946817795415257,
290.09354945708253,
15.92895774748979,
20.67848108024384,
270.81934001072847,
238.6262944213475,
302.0456223742334,
16.115397068330424,
43.79588440154714,
42.15379271739607
],
"directionalSpread": [
76.64341123018586,
78.16398405635755,
74.31006925763587,
72.82439205328765,
79.5530929901738,
72.27398886427513,
77.57328509547172,
71.27542822057472,
76.91181770793688,
74.86862446579735
],
"timestamp": "2023-08-27T09:00:00.000Z",
"latitude": 27.85703,
"longitude": -15.39729
}
]
}
}';
SELECT *
FROM OPENJSON (@JSON, '$.data')
WITH (
spotterId nvarchar(25),
frequencyData nvarchar(max) AS JSON
) AS [data]
CROSS APPLY OPENJSON([data].frequencyData)
WITH (
frequency decimal(6,4) '$'
--,ISJSON([data].frequencyData)
-- ,df decimal(10, 5)
-- ,varianceDensity decimal(10, 5)
--,direction decimal(10, 5)
-- ,directionalSpread decimal(10, 5)
) AS [freq]The above code is how for a got before my googling did not get me further.
Thank you for any assistance 🙂
-
There is probably a better method:
SELECT J.spotterId, FD.indexKey, FD.frequency, FD.df, FD.varianceDensity, FD.direction, FD.directionalSpread
FROM OPENJSON (@JSON, '$.data')
WITH (
spotterId nvarchar(25)
,frequencyData nvarchar(max) AS JSON
) AS J
CROSS APPLY OPENJSON(J.frequencyData)
WITH (
frequency nvarchar(max) AS JSON
,df nvarchar(max) AS JSON
,varianceDensity nvarchar(max) AS JSON
,direction nvarchar(max) AS JSON
,directionalSpread nvarchar(max) AS JSON
) D
CROSS APPLY
(
/* Cast to correct datatypes */
SELECT F.[key] AS indexKey
,CAST(F.[Value] AS decimal(7,5)) AS frequency
,CAST(DF.[Value] AS decimal(10,5)) AS df
,VD.[Value] AS varianceDensity
,DN.[Value] AS direction
,DS.[Value] AS directionalSpread
FROM OPENJSON(D.frequency) F
JOIN OPENJSON(df) DF
ON F.[key] = DF.[key]
JOIN OPENJSON(VarianceDensity) VD
ON F.[key] = VD.[key]
JOIN OPENJSON(direction) DN
ON F.[key] = DN.[key]
JOIN OPENJSON(directionalSpread) DS
ON F.[key] = DS.[key]
) FD; -
Thank you. That gives exactly the result that I need
- Ken McKelvey wrote:
There is probably a better method:
Well I came up with pretty much the identical query. Joining the rows back together using the array keys seems unavoidable. In SQL Server 2022 there's the new JSON_ARRAY function which might permit getting rid of the CTE. Without that tho OPENJSON and a defined schema also seems unavoidable. Query aside the serialization for the expected output could be improved
Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
Viewing 4 posts - 1 through 4 (of 4 total)
You must be logged in to reply to this topic. Login to reply