

Awhile back, if you are on Twitter, you can probably recall my ranting about the 949 indexes I was reviewing. The process was to determine duplicate indexes and consolidate them or discard the unneeded ones. My ranting was not about the duplicates per se it was about the index names. It only takes a second to name an object with some name that tells what the thing is. Below I will show you some examples and give you an easy script that will help you generate your index names. Taking a little time to name things appropriately can go a long way, it can not only be time saving but can help to reduce redundancy.
The DONT’s
As you can see from above, none of the names gave a complete indication of what the index encompassed. The first one did indicate it was a Non Clustered Index so that was good, but includes the date which to me is not needed. At least I knew it was not a Clustered Index. The second index did note it is a “Covering Index” which gave some indication that many columns could be included I also know it was created with the Data Tuning Advisor due to the dta prefix. The third index was also created with dta but it was left with the default dta naming convention. Like the first one I know the date it was created but instead of the word Cover2, I know there are 16 key columns are noted by the “K#” and regular numbers tell me those are included columns. However, I still have no idea exactly what these numbers denote without looking deeper into the index. The last index is closer to what I like however the name only tells me one column name when in fact it encompasses five key columns and two included columns.
The DO’s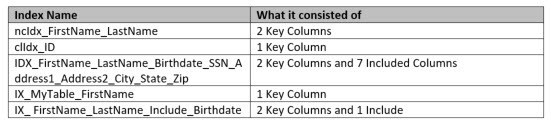
Above we see a few good examples with varying naming conventions, but each tell me a much more than what we saw in the “Donts” list. The first one I know right away is a non-clustered index with two fields. The second is a clustered index with one field. The third is an index that has 9 fields, probably a covering index of some sort, which tells me that it is probably important to a specific query or procedure. Index four uses the name of the table and the field, which does give me more information but given the name of indexes are limited to 128 characters I prefer to leave that out. The last one closer to one of my favorites, because it does give more information. The name lets us know that it has an included column of Birthdate.
The Script
Here is the script I use when creating indexes. It will go thru and identify a missing index and create Index statement using a standard name convention.
NOTE: This modified version of what we use at DCAC is for just showing you how I include and create a standard statement in my code, this is not to be used to identify missing indexes, as it is not the purpose of my post. I have removed pieces of that from this script.
SELECT DB_NAME(c.database_id) as DatabaseName,
OBJECT_NAME(c.object_id, c.database_id) as TableName ,
c.equality_columns as EqualityColumns ,
c.inequality_columns as InequalityColumns ,
c.included_columns as IncludedColumns ,
'USE [' + DB_NAME(c.database_id) + '];
CREATE INDEX IDX_'
+ REPLACE(REPLACE(REPLACE(REPLACE(ISNULL(equality_columns, '')
+ ISNULL(c.inequality_columns, ''),
', ', '_'), '[', ''), ']', ''), ' ',
'') + ' ON [' + SCHEMA_NAME(d.schema_id) + '].['
+ OBJECT_NAME(c.object_id, c.database_id) + ']
(' + ISNULL(equality_columns, '')
+ CASE WHEN c.equality_columns IS NOT NULL
AND c.inequality_columns IS NOT NULL THEN ', '
ELSE ''
END + ISNULL(c.inequality_columns, '') + ')
' + CASE WHEN included_columns IS NOT NULL
THEN 'INCLUDE (' + included_columns + ')'
ELSE ''
END + '
WITH (FILLFACTOR=90, ONLINE=ON)' as CreateIndexStmt
FROM sys.dm_db_missing_index_group_stats a
JOIN sys.dm_db_missing_index_groups b ON a.group_handle = b.index_group_handle
JOIN sys.dm_db_missing_index_details c ON b.index_handle = c.index_handle
JOIN sys.objects d ON c.object_id = d.object_id
WHERE c.database_id = DB_ID()
ORDER BY DB_NAME(c.database_id) ,
OBJECT_NAME(c.object_id, c.database_id) ,
ISNULL(equality_columns, '') + ISNULL(c.inequality_columns, '') ;
GOCreate Statement Output
USE [My_Reporting]; CREATE INDEX IDX_ID_StartTime_EndTime ON [dbo].[Shift] ([ID], [StartTime], [EndTime]) INCLUDE ([Notes], [EmployeeID]) WITH (FILLFACTOR=90, ONLINE=ON)
This statement gives the proper database context and create statement syntax, it adds all the needed key columns within the () and separated by commas. In addition, it adds the word INCLUDE and encompasses the included columns also in () and comma separated. Note the index name only includes the Key columns, which is just my preference.
Summary
Now everyone has their own naming conventions. You do you, however should stay consistent and give some meaning to it. When others look at the objects we should be able to know what it’s doing or be given a good clue as to what it’s for. This not only helps to quickly identity its definition but also keep you from creating duplicates. By looking at names you can tell with columns you need are already included in other indexes. Naturally you can’t just trust the name you have to dig deeper while examining your indexes but it at least will give you a realistic starting point.
