I have string data in a column and i need to strip out parts of it.
-
I have a column in a table that is a string and i need to strip out the parts of it, i have been banging my head for a day or so and now am asking for help.
The data Looks like this:
UIMth: 07/01/23 UISeq: 444 Header Reviewer: DN
UIMth: 07/01/23 UISeq: 3577 Line: 1 Reviewer: GDJ
I need to put the date in a column and then the UISeg in a Column and then the Header reviewer in a column and the Line in its own column if present and then the reviewer in a column.
Thanks for all you guys helps
-
Here is a start:
SELECT UIMth = substring(t.yourcolumn, 8, 8)
, UISeq = substring(t.yourcolumn, 24, charindex(' ', t.yourcolumn, 24) - 24)
, Reviewer = substring(t.yourcolumn, charindex('Reviewer: ', t.yourcolumn) + 10, 99)If there is other data to the right of the Reviewer - then you would need another CHARINDEX to find the position of the space following the data - and use that to determine the length for the SUBSTRING.
Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs -
Thank you, that helped allot.
Jim
-
How can i adjust the substring to grab from 1 to 4 numbers in the UISeq?
SELECT UIMth = substring(t.yourcolumn, 8, 8)
, UISeq = substring(t.yourcolumn, 24, charindex(' ', t.yourcolumn, 24) - 24)
, Reviewer = substring(t.yourcolumn, charindex('Reviewer: ', t.yourcolumn) + 10, 99)
-
Personally for something this involved / complex, I'd use a custom function that parsed with pre-determination. That is, the code doesn't look only for specific names (tags) in the data, it would find all of them. It would return pre-determined labels in specific columns, but could also return other values in "other" columns (such as other1 / other2 / other3). I believe this will be easier to enhance in the future when needing to add new tags to be pulled from the data.
For example, here's sample code that does the parsing. Let me know if you want me to adjust it for specific tags.
/* run these after creating the function::
SELECT * FROM dbo.parse_string_values('UIMth: 07/01/23 UISeq: 444 Header Reviewer: DN')
SELECT * FROM dbo.parse_string_values('UIMth: 07/01/23 UISeq: 3577 Line: 1 Reviewer: GDJ')
SELECT * FROM dbo.parse_string_values('xx: abc yyy: 123-456 aab: qxrl1 cc1: 75R14')
*/SET ANSI_NULLS ON;
SET QUOTED_IDENTIFIER ON;
GO
CREATE FUNCTION dbo.parse_string_values
(
@string varchar(1000)
)
RETURNS @values TABLE ( id int NOT NULL IDENTITY(1, 1), /*optional, of course*/ label varchar(30) NOT NULL, value varchar(100) NULL )
AS
BEGIN
DECLARE @end_byte int;
DECLARE @label varchar(50);
DECLARE @start_byte int;
DECLARE @value varchar(100);
SET @string = RTRIM(@string);
SET @start_byte = 1;
SET @end_byte = 1;
WHILE @end_byte < LEN(@string)
BEGIN
SET @string = LTRIM(@string);
WHILE SUBSTRING(@string, @end_byte, 1) <> ':'
SET @end_byte = @end_byte + 1;
IF @end_byte >= LEN(@string)
BREAK;
SET @label = SUBSTRING(@string, @start_byte, @end_byte - @start_byte)
/* PRINT 'label = ' + @label */ SET @start_byte = @end_byte + 1;
IF SUBSTRING(@string, @start_byte, 1) = ' '
SET @start_byte = @start_byte + 1;
SET @end_byte = @start_byte + 1;
WHILE SUBSTRING(@string, @end_byte, 1) <> ' '
SET @end_byte = @end_byte + 1;
SET @value = SUBSTRING(@string, @start_byte, @end_byte - @start_byte)
/* PRINT 'value = ' + @value */ INSERT INTO @values VALUES( @label, @value )
SET @start_byte = @end_byte + 1;
END /*IF*/RETURN
END /*FUNCTION*/GOSQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
DROP TABLE IF EXISTS #T
GO
CREATE TABLE #T (Col1 VARCHAR(100));
INSERT INTO #T(Col1)
VALUES ('UIMth: 07/01/23 UISeq: 444 Header Reviewer: DN'),
('UIMth: 07/01/23 UISeq: 3577 Line: 1 Reviewer: GDJ'),
('UIMth: 07/01/23 UISeq: 3218 Line: 1 Reviewer: MAH'),
('UIMth: 07/01/23 UISeq: 3218 Header Reviewer: MAH'),
('UIMth: 07/01/23 UISeq: 493 Line: 1 Reviewer: MAH'),
('UIMth: 07/01/23 UISeq: 493 Header Reviewer: MAH'),
('UIMth: 07/01/23 UISeq: 62 Line: 1 Reviewer: JTJ'),
('UIMth: 07/01/23 UISeq: 62 Header Reviewer: JTJ'),
('UIMth: 07/01/23 UISeq: 1 Line: 1 Reviewer: JTJ'),
('UIMth: 07/01/23 UISeq: 1 Header Reviewer: JTJ')
;
SELECT SUBSTRING(Col1, PATINDEX('%[0-3][0-9]/[0-1][0-9]/[0-9][0-9]%',Col1), 8) UIMth,
SUBSTRING(Col1,T.USeqPosStart, T2.USeqPosEnd - T.USeqPosStart) UISeq,
CASE WHEN T.LinePosStart > LEN('Line: ')+1 THEN 'Line: ' + SUBSTRING(Col1,T.LinePosStart, T2.LinePosEnd - T.LinePosStart) ELSE 'Header' END HD_LI,
SUBSTRING(Col1,T.ReviewerPosStart, T2.ReviewerPosEnd - T.ReviewerPosStart) Reviewer
FROM #T
CROSS APPLY(VALUES (CHARINDEX('UISeq: ', Col1+ ' ')+LEN('UISeq: ')+1,
CHARINDEX('Reviewer: ', Col1+ ' ')+LEN('Reviewer: ')+1,
CHARINDEX('Line: ', Col1+ ' ')+LEN('Line: ')+1
)) AS T(USeqPosStart,ReviewerPosStart,LinePosStart)
CROSS APPLY(VALUES (CHARINDEX(' ', Col1+ ' ', T.USeqPosStart+1),
CHARINDEX(' ', Col1+ ' ', T.ReviewerPosStart+1),
CHARINDEX(' ', Col1+ ' ', T.LinePosStart+1)
)) T2(USeqPosEnd,ReviewerPosEnd, LinePosEnd)
;
- James Reed wrote:
How can i adjust the substring to grab from 1 to 4 numbers in the UISeq?
SELECT UIMth = substring(t.yourcolumn, 8, 8) , UISeq = substring(t.yourcolumn, 24, charindex(' ', t.yourcolumn, 24) - 24) , Reviewer = substring(t.yourcolumn, charindex('Reviewer: ', t.yourcolumn) + 10, 99)
Instead of posting code, could you post some examples of the strings, please?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Sorry Jeff, I had posted it before...but here is a better view of the strings i am dealing with.
UIMth: 07/01/23 UISeq: 3218 Line: 1 Reviewer: MAH
UIMth: 07/01/23 UISeq: 3218 Header Reviewer: MAH
UIMth: 07/01/23 UISeq: 493 Line: 1 Reviewer: MAH
UIMth: 07/01/23 UISeq: 493 Header Reviewer: MAH
UIMth: 07/01/23 UISeq: 62 Line: 1 Reviewer: JTJ
UIMth: 07/01/23 UISeq: 62 Header Reviewer: JTJ
UIMth: 07/01/23 UISeq: 1 Line: 1 Reviewer: JTJ
UIMth: 07/01/23 UISeq: 1 Header Reviewer: JTJ
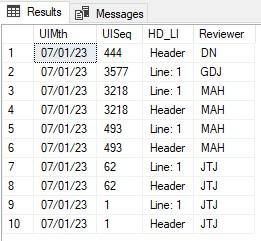
So my goal is to strip out the date after UIMth, then strip out the number after UISeq, then the next part is either Line: X or Header and then the last column is after the Reviewer:
I have all working well except the UISeq because of the varied length to causes the Line or Header to be cut off.
-
Ah... my apologies, James. Based on your request (repeated below), I interpreted it as there would be 1 to 4 "numbers" in a single row. What you meant was "one number per row with 1 to 4 digits", correct?
James Reed wrote:How can i adjust the substring to grab from 1 to 4 numbers in the UISeq?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Yes Jeff you are correct.
in the picture attached is what i am trying to achieve but with only a single digit it is throwing off the next record set.
-
Preamble:
I know Jonathan posted test code and solution code but his code returns the word "Header" for the "Edge Case" of the "LineType" (my name for the "field") not being present, which is a possibility according to what you said in your original post. I'm not sure what you wanted to happen with such an eventuality but I'm making the possible bad assumption that you wanted nothing returned if nothing was present for the "LineType". That's also a reason why to post enough test data that includes such an "Edge Case" and what the desired results should be using that data.
Some Friendly Advice:
When you post a problem, you should post example data in a "Readily Consumable Format", like Jonathan did in his code and I'm doing below. (See the article at the first link in my signature line below for the reasons why you should really do such a thing).
The Test Data:
The following code creates and populates a test table using your latest data posting. It also includes 2 "Edge Cases", which are documented in the code.
--===== Create and populate the test table using the OP's data
-- and following Jonathan's lead for a test table name.
-- This is NOT a part of the solution.
-- We're just setting up a test environment here.
DROP TABLE IF EXISTS #T;
GO
SELECT v1.Col1
INTO #T
FROM (VALUES
('UIMth: 07/01/23 UISeq: 3218 Line: 1 Reviewer: MAH')
,('UIMth: 07/01/23 UISeq: 3218 Header Reviewer: MAH')
,('UIMth: 07/01/23 UISeq: 493 Line: 1 Reviewer: MAH')
,('UIMth: 07/01/23 UISeq: 493 Header Reviewer: MAH')
,('UIMth: 07/01/23 UISeq: 62 Line: 1 Reviewer: JTJ')
,('UIMth: 07/01/23 UISeq: 62 Header Reviewer: JTJ')
,('UIMth: 07/01/23 UISeq: 1 Line: 1 Reviewer: JTJ')
,('UIMth: 07/01/23 UISeq: 1 Header Reviewer: JTJ')
,('UIMth: 07/01/23 UISeq: 1 Reviewer: JTJ') --Added line has no "LineType" present
,('UIMth: 07/01/23 UISeq: 1 Really big line type Reviewer: JTJ') --Added line with odd LineType
)v1(Col1)
;
--===== See what the data in the test table looks like.
SELECT * FROM #T
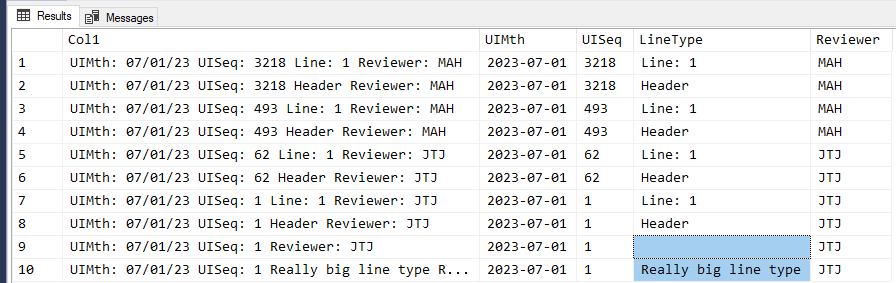
;A Possible Simple Solution:
Provided that the data is actually as consistent as it appears, with or without the possibly missing "LineType", here's a simple bit of made simpler by using the optional 3 operand of CHARINDEX() (which Jeffrey Williams also used in his code example), which is the character position number of where to start looking in a string. It "auto-mathically" handles the possible missing "LineType" as well as different possible text for the line type, as well.
--===== Solve the problem using simple starting position math and the optional 3rd operand of CHARINDEX().
-- This code DOES make the assumption that the input is consistant in nature.
SELECT Col1 -- The original data, just for verification
,UIMth = CONVERT(DATE,SUBSTRING(Col1,8,8),1) -- 1 = MM/DD/YY Format
,UISeq = SUBSTRING(Col1,24,v1.LineTypePos-24)
,LineType = RTRIM(SUBSTRING(Col1,v1.LineTypePos+1,v1.ReviewerPos-v1.LineTypePos-1)) --Empty String if not present
,Reviewer = SUBSTRING(Col1,v1.ReviewerPos+10,100)
FROM #T
CROSS APPLY (VALUES (--===== These positions define where the "LineType" is located
CHARINDEX(' ',Col1,24) -- Position: First space after UISeq value
,CHARINDEX('Reviewer:',Col1) -- Position: First "R" of Review
))v1(LineTypePos,ReviewerPos)
;Here are the results from that code/test data. The "Edge Cases" are highlighted in Blue.
Again, certain assumptions have been made like the left to right order of the "fields" in the string, the guaranteed presence of all but the LineType "field", consistency of the UIMth: date format of MM/DD/YY, and only single spacing except for what may be contained in the "LineType" column. The code will also handle the eventuality of having more than 4 digits for the UISeq: number.
And, "Welcome Back" to SSC... this is only your 4th question and 18th post in 15 years. I hope that means that you and yours are doing well. 😀
p.s. If the data isn't so consistent, post back with a "Readily Consumable" set of test data and we'll give something else a try with the goal of avoiding RBAR always at the top of my mind. We might be able to do a little trick with a JSON conversion.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:
Preamble:
And, "Welcome Back" to SSC... this is only your 4th question and 18th post in 15 years. I hope that means that you and yours are doing well. 😀
Thanks Jeff, Yes i have been on this site for a long time and have used a lot of code and examples from the site over the years. Over the years I had worked at a place and didn't write much code at all and now I am at a place that I am having to extract a bunch of data from vendor software and realizing how much I have forgot about writing scripts. But thank you for all your help and so many amazing posts and the site.
:):)
Viewing 12 posts - 1 through 12 (of 12 total)
You must be logged in to reply to this topic. Login to reply