


Ladies and Gentlemen, welcome to the main event of the evening. The SQL Undercover Smackdown Heavy Weight Championship of the World!
In the red corner, we hate him, we loath him, I’ve even heard people say he should be deprecated, it’s the Cursor!!!
Facing him in the blue corner, loved on the forums, praised by developers the world over, everyone’s friend, the Loop!!!
Let’s get ready to RUMBLE!!!!
Welcome along to our new series of SQL Smackdowns where we pitch two methods of achieving something against each other to find out which is the most efficient.
Now before I get going I’m going to be the first to put my hand up and admit that any RBAR operation is going to be nasty and we should really be avoiding doing them in favour of a set based approach where possible. But there are plenty of use cases where a set based approach just isn’t possible, we might be doing an admin task where we need to cycle through a list of databases or a particular set of data and perform a task. In those cases we need a way of looping through the data to perform an action.
We all know that cursors are bad and many people will avoid using them at all costs. The forums often advise against their use and I’ve seen plenty of code where they’re replaced with something else. The thing that they’re often replaced with is a WHILE loop.
Every day I come across code where a developer or DBA has used a WHILE loop similar to those in my examples in place of a CURSOR, but are loops really any better than cursors? We decided to find out.
To test this out we created the following table and populated it with 1 million rows.
CREATE TABLE CursorsLoops2 (ID INT, GUID UNIQUEIDENTIFIER)
ROUND 1
In this first test we’ll simply spin through every row in that table and print it out. So let’s start with the cursor.
DECLARE @guid UNIQUEIDENTIFIER DECLARE @id INT DECLARE Test CURSOR FOR SELECT ID, GUID FROM CursorsLoops OPEN Test FETCH NEXT FROM Test INTO @id, @guid WHILE @@FETCH_STATUS = 0 BEGIN PRINT CAST(@id AS VARCHAR(50)) + ' ' + CAST(@guid AS VARCHAR(50)) FETCH NEXT FROM Test INTO @id, @guid END CLOSE test DEALLOCATE test
The query completed in 47 seconds
So let’s see how a WHILE loop get on doing the same thing…
DECLARE @guid UNIQUEIDENTIFIER DECLARE @id INT = 0 SELECT TOP 1 @id = id, @guid = guid FROM CursorsLoops WHERE id > @id ORDER BY id WHILE @id IS NOT NULL BEGIN PRINT CAST(@id AS VARCHAR(50)) + ' ' + CAST(@guid AS VARCHAR(50)) SELECT TOP 1 @id = id, @guid = guid FROM CursorsLoops WHERE id > @id ORDER BY id END
Well, I gave up after the query had run for two minutes and in that time it had managed to get through only 625 rows out of the million.
BOOM! Cursor body slams Loops into the canvas, we felt that from up here.
WOW, that’s a massive win for the cursor but what’s really going on and why was the loop so much slower? Let’s take a look at the execution plan for both.
Cursor Execution Plan
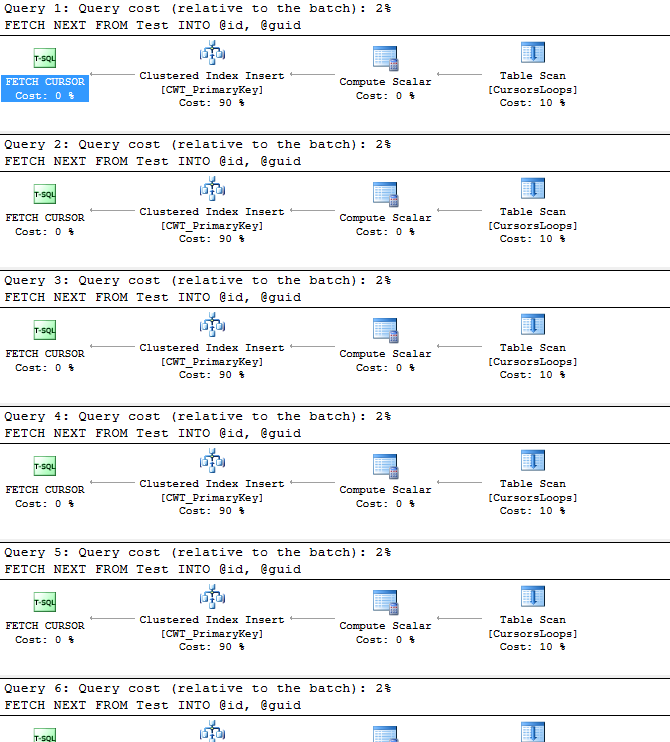
So for every iteration of the cursor we’re having to scan the table, that’s not looking too nice. So what’s the loop doing to make it that much slower?
Loop Execution Plan

Well the difference looks to be that sort. Ok, the loop is having to sort the data before it can do anything. Let us level things out a bit and sort the cursor to see what happens then.
Round 2
We’ll change the code of the cursor to order the data first, will that give the loop the edge? At the least it’ll put them on a level footing.
DECLARE @guid UNIQUEIDENTIFIER DECLARE @id INT DECLARE Test CURSOR FOR SELECT ID, GUID FROM CursorsLoops ORDER BY ID OPEN Test FETCH NEXT FROM Test INTO @id, @guid WHILE @@FETCH_STATUS = 0 BEGIN PRINT CAST(@id AS VARCHAR(50)) + ' ' + CAST(@guid AS VARCHAR(50)) FETCH NEXT FROM Test INTO @id, @guid END CLOSE test DEALLOCATE test
This time the cursor took 43 seconds to get through the million rows, that’s marginally quicker than when we were using an unordered cursor. WFT? Let’s have a look at the execution plan now.
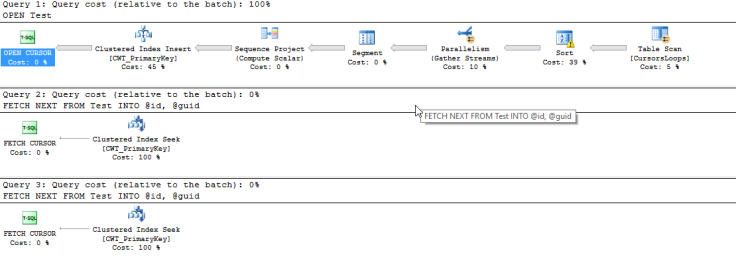
This time our cursor is doing something totally different, instead of scanning the dataset on every iteration, it’s running into some data structure and then just performing a seek on that structure each time it performs a fetch.
Check out Aaron Bertrand’s excellent investigation on the performance of the various cursor options.
When we don’t actually specify any cursor options SQL Server will make a decision on what options to use, as we’re seeing here. Just out of interest, what are the read counts looking like for the scripts that we’ve looked at so far.
Loops – 3,776 reads per iteration (over a million iterations that’s 3,776,000,000 reads)
Unordered Cursor – 3 reads per iteration
Ordered Cursor – 3 reads per iteration
Aaron Bertrand tells us that declaring a cursor with LOCAL FAST_FORWARD gives us the best possible performance, let’s try rerunning the unordered cursor with those options specified and see how it performs.
DECLARE @guid UNIQUEIDENTIFIER DECLARE @id INT DECLARE Test CURSOR LOCAL FAST_FORWARD FOR SELECT ID, GUID FROM CursorsLoops ORDER BY ID OPEN Test FETCH NEXT FROM Test INTO @id, @guid WHILE @@FETCH_STATUS = 0 BEGIN PRINT CAST(@id AS VARCHAR(50)) + ' ' + CAST(@guid AS VARCHAR(50)) FETCH NEXT FROM Test INTO @id, @guid END CLOSE test DEALLOCATE test
25 seconds with only 1 read per iteration.
With that huge right hook, Loops goes down. He looks to be out but somehow manages to climb to his feet as bell goes. He staggers to his corner, bloodied.
Round 3
So far we’ve been working on looping through a heap, I wonder if we created a clustered index on ID we’d see a different result.
With the index added, the LOCAL FAST_FORWARD cursor is done in 21 seconds with one read per iteration.
Lets see if the loop can snatch back some pride here.
With the clustered index, the loop was finished in 59 seconds with 3 reads per iteration. Now that’s a huge improvement on what we were seeing for it but it’s still falling way behind the cursor.
Loops is up against the ropes here, one, two swift body shots and he’s on the floor and out for the count.
The Cursor is our SQL Undercover Smackdown Champion!
Conclusion
In the example that I have been looking at, although indexing will increase the performance of a WHILE loop there was no point when it out performed the CURSOR and once we started to use LOCAL FAST_FORWARD cursors, the loop lagged a long way behind.
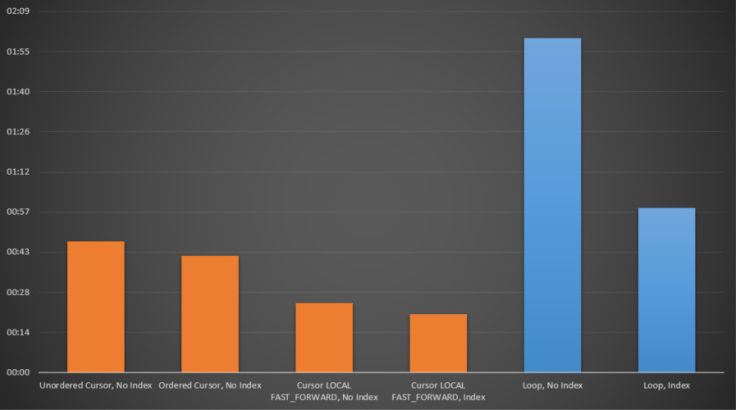
This is probably going to be quite controversial, it goes against a lot of advice that’s out there and please bear in mind that this is only one specific example, but looking at my findings it might be worth not being quite so quick to shoot cursors down in the future.
Of course you do need to think about your particular use case and if a cursor is the best way to go or if the same could be accomplished using a more efficient set based approach.
