

There are a tremendous amount of Microsoft products that are cloud-based for building big data solutions. It’s great that there are so many products to choose from, but it does lead to confusion on what are the best products to use for particular use cases and how do all the products fit together. My job as a Microsoft Cloud Solution Architect is to help companies know about all the products and to help them in choosing the best products to use in building their solution. Based on a recent architect design session with a customer I wanted to list the products and use cases that we discussed for their desire to build a big data solution in the cloud (focusing on compute and data storage products and not ingestion/ETL, real-time streaming, advanced analytics, or reporting; also, only PaaS solutions are included – no IaaS):
- Azure Data Lake Store (ADLS): Is a high throughput distributed file system built for cloud scale storage. It is capable of ingesting any data type from videos and images to PDFs and CSVs. This is the “landing zone” for all data. It is HDFS compliant, meaning all products that work against HDFS will also work against ADLS. Think of ADLS as the place all other products will use as the source of their data. All data will be sent here including on-prem data, cloud-based data, and data from IoT devices. This landing zone is typically called the Data Lake and there are many great reasons for using a Data Lake (see Data lake details and Why use a data lake? and the presentation Big data architectures and the data lake)
- Azure HDInsight (HDI): Under the covers, HDInsight is simply Hortonworks HDP 2.6 that contains 22 open source products such as Hadoop (Common, YARN, MapReduce), Spark, HBase, Storm, and Kafka. You can use any of those or install any other open source products that can all use the data in ADLS (HDInsight just connects to ADLS and uses that as its storage source)
- Azure Data Lake Analytics (ADLA): This is a distributed analytics service built on Apache YARN that lets you submit a job to the service where the service will automatically run it in parallel in the cloud and scale to process data of any size. Included with ADLA is U-SQL, which has a scalable distributed query capability enabling you to efficiently analyze data whether it be structured (CSV) or not (images) in the Azure Data Lake Store and across Azure Blob Storage, SQL Servers in Azure, Azure SQL Database and Azure SQL Data Warehouse. Note that U-SQL supports batch queries and does not support interactive queries, and does not handle persistence or indexing. ADLA is great for things such as prepping large amounts of data for insertion into a data warehouse or replacing long-running monthly batch processing with shorter running distributed processes
- Azure Analysis Services (AAS): This is a PaaS for SQL Server Analysis Services (SSAS). It allows you to create an Azure Analysis Services Tabular Model (i.e. cube) which allows for much faster query and reporting processing compared to going directly against a database or data warehouse. A key AAS feature is vertical scale-out for high availability and high concurrency. It also creates a semantic model over the raw data to make it much easier for business users to explore the data. It pulls data from the ADLS and aggregates it and stores it in AAS. The additional work required to add a cube to your solution involves the time to process the cube and slower performance for ad-hoc queries (not pre-determined), but there are additional benefits of a cube – see Why use a SSAS cube?
- Azure SQL Data Warehouse (SQL DW): This is a SQL-based, fully-managed, petabyte-scale cloud data warehouse. It’s highly elastic, and it enables you to set up in minutes and scale capacity in seconds. You can scale compute and storage independently, which allows you to burst compute for complex analytical workloads. It is an MPP technology that shines when used for ad-hoc queries in relational format. It requires data to be copied from ADLS into SQL DW but this can be done quickly using PolyBase. Compute and storage are separated so you can pause SQL DW to save costs (see
SQL Data Warehouse reference architectures) - Azure Cosmos DB: This is a globally distributed, multi-model (key-value, graph, and document) database service. It fits into the NoSQL camp by having a non-relational model (supporting schema-on-read and JSON documents) and working really well for large-scale OLTP solutions (it also can be used for a data warehouse when used in combination with Apache Spark – a later blog). See Distributed Writes and the presentation Relational databases vs Non-relational databases. It requires data to be imported into it from ADLS using Azure Data Factory
- Azure Search: This is a search-as-a-service cloud solution that gives developers APIs and tools for adding a rich full-text search experience over your data. You can store indexes in Azure Search with pointers to objects sitting in ADLS. Azure Search is rarely used in data warehouse solutions but if queries are needed such as getting the number of records that contain “win”, then it may be appropriate. Azure Search supports a pull model that crawls a supported data source such as Azure Blob Storage or Cosmos DB and automatically uploads the data into your index. It also supports the push model for other data sources such as ADLS to programmatically send the data to Azure Search to make it available for searching. Note that Azure Search is built on top of ElasticSearch and uses the Lucene query syntax
- Azure Data Catalog: This is an enterprise-wide metadata catalog that makes data asset discovery straightforward. It’s a fully-managed service that lets you register, enrich, discover, understand, and consume data sources such as ADLS. It is a single, central place for all of an organization’s users to contribute their knowledge and build a community and culture of data. Without using this product you will be in danger having a lot of data duplication and wasted effort
- Azure Databricks: This is a tool for curating and processing massive amounts of data and developing, training and deploying models on that data, and managing the whole workflow process throughout the project. It is for those who are comfortable with Apache Spark as it is 100% based on Spark and is extensible with support for Scala, Java, R, and Python alongside Spark SQL, GraphX, Streaming and Machine Learning Library (Mllib). It has built-in integration with Azure Blog Storage, ADLS, SQL DW, Cosmos DB, Azure Event Hub, and Power BI. Think of it as an alternative to HDI and ADLA. It differs from HDI in that HDI is a PaaS-like experience that allows working with more OSS tools at a less expensive cost. Databricks advantage is it is a Spark-as-a-Service-like experience that is easier to use, has native Azure AD integration (HDI security is via Apache Ranger and is Kerberos based), has auto-scaling and auto-termination, has a workflow scheduler, allows for real-time workspace collaboration, and has performance improvements over traditional Apache Spark. Also note with built-in integration to SQL DW it can write directly to SQL DW, as opposed to HDInsight which cannot and therefore more steps are required: when HDInsight processes data it writes it back to Blob Storage and then requires ADF to move the data from Blob Storage to SQL DW
In addition to ADLS, Azure Blob storage can be used instead of ADLS or in combination with it. When comparing ADLS with Blob storage, Blob storage has the advantage of lower cost since there are now three Azure Blob storage tiers: Hot, Cool, and Archive, that are all less expensive than ADLS. The advantage of ADLS is that there are no limits on account size and file size (Blob storage has a 5 PB account limit and a 4.75 TB file limit). ADLS is also faster as files are auto-sharded/chunked where in Blob storage they remain intact. ADLS supports Active Directory while Blob storage supports SAS keys. ADLS also supports WebHDFS while Blob storage does not (it supports WASB which is a thin layer over Blob storage that exposes it as a HDFS file system). Finally, while Blob storage is in all Azure regions, ADLS is only in two US regions (East, Central) and North Europe (other regions coming soon). See Comparing Azure Data Lake Store and Azure Blob Storage.
Now that you have a high-level understanding of all the products, the next step is to determine the best combination to use to build a solution. If you want to use Hadoop and don’t need a relational data warehouse the product choices may look like this:

Most companies will use a combination of HDI and ADLA. The main advantage with ADLA over HDI is there is nothing you have to manage (i.e. performance tuning), there is only one language to learn (U-SQL) with easier development and debugging tools, you only incur costs when running the jobs where HDI clusters are always running and incurring costs regardless if you are processing data or not, and you can scale individual queries independently of each other instead of having queries fight for resources in the same HDIinsight cluster (so predictable vs unpredictable performance). In addition, ADLA is always available so there is no startup time to create the cluster like with HDI. HDI has an advantage in that it has more products available with it (i.e. Kafka) and you can customize it (i.e. install additional software) where in ADLS you cannot. When submitting a U-SQL job under ADLA you specify the resources to use via a Analytics Unit (AU). Currently, an AU is the equivalent of 2 CPU cores and 6 GB of RAM and you can go as high as 450 AU’s. For HDI you can give more resources to your query by increasing the number of worker nodes in a cluster (limited by the region max core count per subscription but you can contact billing support to increase your limit).
Most of the time a relational data warehouse as part of your solution, with the biggest reasons being familiarity with relational databases by the existing staff and the need to present an easier to understand presentation layer to the end-user so they can create their own reports (self-service BI). A solution that adds a relational database may look like this:
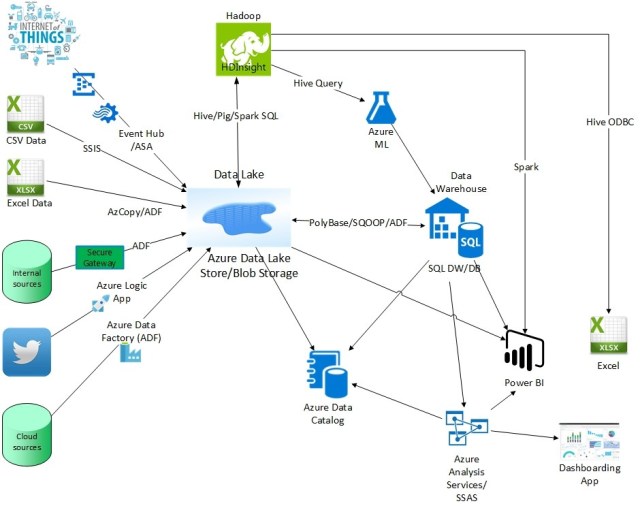
The Data Lake technology can be ADLS or blob storage, or even Cosmos DB. The main reason against using Cosmos DB as your Data Lake is cost and having to convert all files to JSON. A good reason for using Cosmos DB as a Data Lake is that it enables you to have a single underlying datastore that serves both operational queries (low latency, high concurrency, low compute queries – direct from Cosmos DB) as well as analytical queries (high latency, low concurrency, high compute queries – via Spark on Cosmos DB). By consolidating to a single data store you do not need to worry about data consistency issues between maintaining multiple copies across multiple data stores. Additionally, Cosmos DB has disaster recovery built-in by easily allowing you to replicate data across Azure regions with automatic failover (see How to distribute data globally with Azure Cosmos DB), while ADLS requires replication and failover to be done manually (see Disaster recovery guidance for data in Data Lake Store). Blob storage has disaster recovery built-in via Geo-redundant storage (GRS) but requires manual failover by Microsoft (see Redundancy Options in Azure Blob Storage).
An option to save costs is to put “hot” data in Cosmos DB, and warm/cold data in ADLS or Blob storage while using the same reporting tool, Power BI, to access the data from either of those sources as well as many others (see Data sources in Power BI Desktop and Power BI and Excel options for Hadoop).
If Cosmos DB is your data lake or used as your data warehouse (instead of SQL DW/DB in the picture above), you can perform ad-hoc queries using familiar SQL-like grammar over JSON documents (including aggregate functions like SUM) without requiring explicit schemas or creation of secondary indexes. This is done via the REST API, JavaScript, .NET, Node.js, or Python. Querying can also be done via Apache Spark on Azure HDInsight, which provides additional benefits such as faster performance and SQL statements such as GROUP BY (see Accelerate real-time big-data analytics with the Spark to Azure Cosmos DB connector). Check out the Query Playground to run sample queries on Cosmos DB using sample data. Note the query results are in JSON instead of rows and columns.
You will need to determine if your solution will have dashboard and/or ad-hoc queries. Your choice of products in your solution will depend on the need to support one or both of those queries. For ad-hoc queries, you have to determine what the acceptable performance is for those queries as that will determine if you need a SMP or MPP solution (see . For dashboard queries (i.e. from PowerBI) it’s usually best to have those queries go against AAS to get top-notch performance and because SQL DW has a 32-concurrent query limit (and one dashboard can have a dozen or so queries). Another option to get around the 32-concurrent query limit is to copy data from SQL DW to data marts in Azure SQL Database. Complex queries, sometimes referred to as “last mile” queries, may be too slow for a SMP solution (i.e. SQL Server, Azure SQL Database) and require a MPP solution (i.e. SQL DW).
The diagram above shows SQL DW or Azure SQL Database (SQL DB) as the data warehouse. To decide which is the best option, see Azure SQL Database vs SQL Data Warehouse. With a clustered column store index SQL DB competes very well in the big data space, and with the addition of R/Python stored procedures, it becomes one of the fastest performing machine learning solutions available. But be aware that the max database size for SQL DB is 4 TB, but there will soon be an option called SQL DB Managed Instance that supports a max database size much higher. See the presentations Should I move my database to the cloud? and
You will also need to determine if you solution will have batch and/or interactive queries. All the products support batch queries, but ADLA does not support interactive queries (so you could not use the combination of Power BI and ADLA). If you want to stay within the Hadoop world you can use the HDInsight cluster types of Spark on HDInsight or HDInsight Interactive Query (Hive LLAP) for interactive queries against ADLS or Blob Storage (see General availability of HDInsight Interactive Query – blazing fast queries on hyper-scale data) and can use AtScale instead of AAS to build cubes/OLAP within Hadoop. AtScale will work against data in ADLS and Blob Storage via HDInsight.
Whether to have users report off of ADLS or via a relational database and/or a cube is a balance between giving users data quickly and having them do the work to join, clean and master data (getting IT out-of-the-way) versus having IT make multiple copies of the data and cleaning, joining and mastering it to make it easier for users to report off of the data. The risk in the first case is having users repeating the process to clean/join/master data and cleaning/joining/mastering it wrong and getting different answers to the same question (falling into the old mistake that the data lake does not need data governance and will magically make all the data come out properly – not understanding that HDFS is just a glorified file folder). Another risk in the first case is performance because the data is not laid out efficiently. Most solutions incorporate both to allow “power users” to access the data quickly via ADLS while allowing all the other users to access the data in a relational database or cube.
Digging deeper, if you want to run reports straight off of data in ADLS, be aware it is file-based security and so you may want to create a cube for row-level security and also for faster performance since ADLS is a file system and does not have indexes (although you can use a products such Jethro Data to create indexes within ADLS/HDFS). Also, running reports off of ADLS compared to a database has disadvantages such as limited support of concurrent users; lack of indexing, metadata layer, query optimizer, and memory management; no ACID support or data integrity; and security limitations.
If using Power BI against ADLS, note that Power BI imports the data from ADLS. It is not a live connection to ADLS so you could easily run into the 1GB limit of a data set in Power BI (although potentially not until after ingesting 10GB of data from ADLS as Power BI can achieve compression of up to 10 times). And be aware the initial import can be slow and the data would be “stale” until refreshed again.
The decisions on which products to use is a balance between having multiple copies of the data and the additional costs that incurs and the maintaining and learning of multiple products versus less flexibility in reporting of data and slower performance. Also, while incorporating more products into a solution means it takes longer to build, the huge benefit of that is you “future proof” your solution to be able to handle any data in the future no matter what the size, type, or frequency.
The bottom line is there are so many products with so many combinations of putting them together that a blog like this can only help so much – you may wind up needing a solution architect like me to help you make sense of it all 
More info:
The Microsoft Business Analytics and AI Platform – What to Use When
Distributed Computing Principles and SQL-on-Hadoop Systems
Using Azure Analysis Services on Top of Azure Data Lake Store
Understanding WASB and Hadoop Storage in Azure
Presentation Data on Azure: The big picture
Presentation Understanding big data on Azure – structured, unstructured and streaming
Presentation Architect your big data solutions with SQL Data Warehouse and Azure Analysis Services
Presentation Building Petabyte scale Interactive Data warehouse in Azure HDInsight
Presentation Building modern data pipelines with Spark on Azure HDInsight
Presentation Azure Blob Storage: Scalable, efficient storage for PBs of unstructured data
Presentation Modernizing ETL with Azure Data Lake: Hyperscale, multi-format, multi-platform, and intelligent
Presentation Azure Cosmos DB: The globally distributed, multi-model database
Startup Mistakes: Choice of Datastore

![]()
