Peaks and troughs from fluctuating prices
-
I have a simple list of prices ordered by time, like
Price
10
9
8
8
8
11
6
6
3
2
and want only the unique peaks and troughs ordered by time, like
10
8
11
2
There should be an elegant SQL solution for this but I only have a cumbersome method.
Please can anyone help?
-
Without a second column containing a date (or some ordinal data type) there's no way to ensure the row ordering is consistent. Thanks ChatGPT for fixing the data. You could try LEAD and LAG
drop table if exists #t;
go
create table #t(n int, dt date);
with numberedrows as (
select n, row_number() over (order by (select null)) as rownum
from (values (10),(9),(8),(8),(8),(11),(6),(3),(2)) v(n)
)
insert into #t(n, dt)
select n, dateadd(day, rownum - 1, '2023-04-20')
from numberedrows;
with lead_lag_cte as (
select *,
lead(n) over (order by dt) lead_n,
lag(n) over (order by dt) lag_n
from #t)
select *
from lead_lag_cte
where lead_n is null
or lag_n is null
or lead_n>n
or lag_n<n;Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
- Steve Collins wrote:
Thanks ChatGPT for fixing the data.
interesting. What prompt did you use for that, Steve? I'm always curious.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
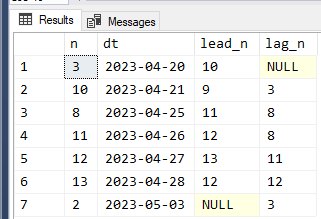
p.s. I'm thinking that your good shot at it needs (as you imply) a little tweaking. Try using the following data and see what I mean...
from (values (3),(10),(9),(8),(8),(8),(11),(12),(13),(12),(11),(6),(3),(2)) v(n)
Results:

I think the use of Lead/Lag is probably on the right track. This just isn't an easy problem.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
I think the way to do this is to eliminate dupes while maintaining the order. Then the Lead/Lag comparison of the difference between the previous point goes from positive and the next point goes negative will give you the peaks and reverse that for the valleys. Like I said, it think you were on the right track. I still have to think about the first and last point a bit but I'm out of time right now (whicb is why I didn't write any code, yet.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
The prompt was based on minimal code
this sql code omits a 2nd column with which we could order the rows. Could you add a date column 'dt' which increments by 1 day for each row and begin on 4/20/2023?
`
drop table if exists #t;
go
create table #t(n int);
insert #t(n) values (10),(9),(8),(8),(8),(11),(6),(6),(3),(2);`Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
-
CREATE TABLE MyTable (
ID INT IDENTITY(1,1) PRIMARY KEY,
Value INT,
DateTimeColumn DATETIME
);
INSERT INTO MyTable (Value, DateTimeColumn)
VALUES
(10, '2023-04-01'),
(9, '2023-04-02'),
(8, '2023-04-03'),
(8, '2023-04-04'),
(8, '2023-04-05'),
(11, '2023-04-06'),
(6, '2023-04-07'),
(6, '2023-04-08'),
(3, '2023-04-09'),
(2, '2023-04-10')
;
SELECT * FROM MyTable ORDER BY DateTimeColumn ASC;Here is a partial solution:
;WITH CTE as
(
SELECT LEAD(Value) OVER (ORDER BY DateTimeColumn) LeadValue,
LAG(Value) OVER (ORDER BY DateTimeColumn) LagValue,
*
FROM MyTable
)
SELECT * ,
CASE
WHEN (x.LeadValue > x.Value AND (x.LagValue > x.Value OR x.LagValue IS NULL))
OR (x.LeadValue IS NULL AND x.LagValue > x.Value) THEN 'Trough'
WHEN (x.LeadValue < x.Value AND (x.LagValue < x.Value OR x.LagValue IS NULL OR x.LeadValue IS NULL))
OR (x.LeadValue IS NULL AND x.LagValue < x.Value) THEN 'Peak'
WHEN (x.LeadValue = x.Value AND x.LagValue = x.Value) THEN 'Level'
ELSE ''
END
FROM CTE x
; -
@richard-2... this is one of the problems with not providing data in a readily consumable test table... everyone make up their own mind as to what the column names and table name should be and it's difficult to test all the different solutions. See the many different methods that people have produced such "Readily Consumable Data" and try to do so on future posts.
Steve's solution was a good start but wasn't complete.
Jonathan's solution is pretty neat but it misses some "events" using the following data.
I didn't include "level" in mine put it does correctly find only the Peaks and Valleys, as requested. The code is fully documented and logically segmented to make it easy to modify for such things.
--=====================================================================================================================
-- Create and populate the test table
--=====================================================================================================================
DROP TABLE IF EXISTS #PriceHistory;
GO
--===== Create the table with a PD on the date
CREATE TABLE #PriceHistory
(
SomeDT DATE PRIMARY KEY CLUSTERED
,Price INT NOT NULL
)
;
--===== Populate the test table.
INSERT INTO #PriceHistory WITH (TABLOCK)
(SomeDT,Price)
SELECT SomeDT = DATEADD(dd,ROW_NUMBER() OVER (ORDER BY (SELECT NULL))-1,'2023-04-20')
,Price = v.Price
FROM (VALUES(3),(10),(11),(11),(9),(8),(8),(8),(11),(12),(13),(12),(11),(6),(3),(2))v(Price)
ORDER BY SomeDT
;
--=====================================================================================================================
-- Find the Peaks and Valleys
-- The key here is to dedupicate adjacent Prices (implied by date) before evaluating events.
-- Testing notes:
-- 1. If two or more adjacent rows have the same event, the code is incorrect.
-- Except for the first and last rows...
-- 2. Peaks will have a price > both the previous and next like any good peak should and :D
-- 3. Valleys will have a price < both the previous and next.
--=====================================================================================================================
WITH
ctePrev AS
(--==== Get the previous Prices for each row using -1 for the first row.
SELECT SomeDT
,Prev = LAG (Price,1,-1) OVER (ORDER BY SomeDT)
,Price
FROM #PriceHistory
)
,cteUniquify AS
(--==== This removes adjacent (implied by date) duplicate prices.
SELECT *
FROM ctePrev
WHERE Prev <> Price
)
,cteNext AS
(--==== Now we can assign LEADs to the deduplicated prices.
SELECT *
,Next = LEAD(Price,1,-1) OVER (ORDER BY SomeDT)
FROM cteUniquify
)
,ctePeaksAndValleys AS
(--==== Just like the name of the cte says, finds the Peaks and Valleys.
-- You could stop here to see the full monty.
SELECT SomeDT,Prev,Price,Next --Delete the columns you don't want to show
,Event = CASE
WHEN Prev>Price AND Price<Next
OR Prev=-1 AND Price<Next
OR Prev>Price AND Next=-1
THEN 'Valley'
WHEN Prev<Price AND Price>Next
OR Prev=-1 AND Price>Next
OR Prev<Price AND Next=-1
THEN 'Peak'
ELSE ''
END
FROM cteNext
)--==== Final filter for display.
SELECT *
FROM ctePeaksAndValleys
WHERE Event > ''
ORDER BY SomeDT
;
--===== Display everything in the table for testing by eye-ball.
SELECT * FROM #PriceHistory ORDER BY SomeDT
;--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Steve Collins wrote:
The prompt was based on minimal code
this sql code omits a 2nd column with which we could order the rows. Could you add a date column 'dt' which increments by 1 day for each row and begin on 4/20/2023?
drop table if exists #t; go create table #t(n int);
insert #t(n) values (10),(9),(8),(8),(8),(11),(6),(6),(3),(2);Thanks, Steve.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
This is interesting. Nicely done Jeff. The AI (ChatGPT-4) was unable to make any improvements to the query marked as the solution. It never comes up with nothing so it proposed some useless formatting which was not syntactically valid and would've caused errors. Ha, I do have an improvement (afaik) tho
Regarding Jeff's marked solution the AI said: "The original query is well-written and efficient" and "These improvements mainly focus on formatting and readability, such as adding commas at the end of each line in the table definition and using consistent indentation. The original query was already efficient and well-structured."
Then I attempted to prompt AI with the original question without providing any code and it was unable to come up with a working query. I provided Jeff's temp table with the additional rows. AI made 6 incorrect attempts where I kept posting the incorrect results back and giving it another shot at it. Finally, I prompted "Not working. No more attempts please. I give up as AI is no match for a master craftsman at relational programming. Thank you for these attempts" AI's response: "I apologize for not being able to provide the correct solution. I understand your frustration, and I appreciate your patience throughout this process. If you have any other questions or need assistance in the future, please don't hesitate to ask. Thank you for giving me the opportunity to help."
To my eye the 3rd CTE is not strictly necessary. The WHERE condition could be applied in the same CTE as the LEAD(Price, 1, -1) function. This query returns the same output
WITH
ctePrev AS
(--==== Get the previous Prices for each row using -1 for the first row.
SELECT SomeDT
,Prev = LAG (Price,1,-1) OVER (ORDER BY SomeDT)
,Price
FROM #PriceHistory
)
,cteUniquify AS
(--==== Now we can assign LEADs to the deduplicated prices.
SELECT *
,Next = LEAD(Price,1,-1) OVER (ORDER BY SomeDT)
FROM ctePrev
WHERE Prev <> Price
)
,ctePeaksAndValleys AS
(--==== Just like the name of the cte says, finds the Peaks and Valleys.
-- You could stop here to see the full monty.
SELECT SomeDT,Prev,Price,Next --Delete the columns you don't want to show
,Event = CASE
WHEN Prev>Price AND Price<Next
OR Prev=-1 AND Price<Next
OR Prev>Price AND Next=-1
THEN 'Valley'
WHEN Prev<Price AND Price>Next
OR Prev=-1 AND Price>Next
OR Prev<Price AND Next=-1
THEN 'Peak'
ELSE ''
END
FROM cteUniquify
)--==== Final filter for display.
SELECT *
FROM ctePeaksAndValleys
WHERE Event > ''
ORDER BY SomeDT
;Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
-
I was thinking along the same lines as Jeff, but did things in a slightly different order. By uniquifying first, I'm able to use the current price for the previous/next price instead of introducing -1 as a special value. This allows me to simplify the conditions for the peaks and valleys.
WITH cteUniquify AS
(
SELECT *
, CASE WHEN ph.Price = LAG(ph.Price) OVER(ORDER BY SomeDt) THEN 0 ELSE 1 END AS PriceChange
FROM #PriceHistory AS ph
)
, cteWindow AS
(
SELECT *
, LAG(u.Price, 1, u.Price) OVER(ORDER BY SomeDt) AS PrevPrice
, LEAD(u.Price, 1, u.Price) OVER(ORDER BY SomeDt) AS NextPrice
FROM cteUniquify AS u
WHERE u.PriceChange = 1
)
SELECT w.SomeDT, w.Price
FROM cteWindow AS w
WHERE w.PrevPrice >= w.Price AND w.Price <= w.NextPrice
OR w.PrevPrice <= w.Price AND w.Price >= w.NextPrice;Drew
J. Drew Allen
Business Intelligence Analyst
Philadelphia, PA -
It shouldn't be necessary to calculate the LAG twice. Like Drew's code this factors out another CTE
WITH
ctePrev AS
(--==== Get the previous Prices for each row using -1 for the first row.
SELECT SomeDT
,Prev = LAG (Price,1,-1) OVER (ORDER BY SomeDT)
,Price
FROM #PriceHistory)
,cteUniquify AS
(--==== Now we can assign LEADs to the deduplicated prices.
SELECT *
,Next = LEAD(Price,1,-1) OVER (ORDER BY SomeDT)
FROM ctePrev
WHERE Prev <> Price)
SELECT SomeDT,Prev,Price,Next --Delete the columns you don't want to show
,ev.p_v
FROM cteUniquify
cross apply (values (CASE
WHEN Prev>Price AND Price<Next
OR Prev=-1 AND Price<Next
OR Prev>Price AND Next=-1
THEN 'Valley'
WHEN Prev<Price AND Price>Next
OR Prev=-1 AND Price>Next
OR Prev<Price AND Next=-1
THEN 'Peak'
ELSE ''
END)) ev(p_v)
Where ev.p_v > ''
ORDER BY SomeDT
;Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
-
Here is a different approach.
WITH cteUniquify AS
(
SELECT *, CASE WHEN ph.Price = LAG(ph.Price) OVER(ORDER BY SomeDt) THEN 0 ELSE 1 END AS PriceChange
FROM #PriceHistory AS ph
)
, cteWindow AS
(
SELECT *
, CASE WHEN u.Price = MIN(u.Price) OVER(ORDER BY u.SomeDt ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING ) THEN 1
WHEN u.Price = MAX(u.Price) OVER(ORDER BY u.SomeDt ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING ) THEN 1
ELSE 0
END AS IsPeakOrValley
FROM cteUniquify AS u
WHERE u.PriceChange = 1
)
SELECT *
FROM cteWindow AS w
WHERE w.IsPeakOrValley = 1Drew
J. Drew Allen
Business Intelligence Analyst
Philadelphia, PA - drew.allen wrote:
Here is a different approach.
Niiiicccceee! I'm going to do some performance tests there because, although it's not a super common request, it's a request that has happened often enough to merit such a thing. Thanks, Drew.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Steve Collins wrote:
It shouldn't be necessary to calculate the LAG twice. Like Drew's code this factors out another CTE
The reason that I calculated the
LAG()twice is that I wanted different default values. In one case I wanted them to be equal to the current value so that I could simplify the peak/valley calculation, but if I used the same default in the uniquify portion, those records would have been filtered out.Drew
J. Drew Allen
Business Intelligence Analyst
Philadelphia, PA
Viewing 15 posts - 1 through 15 (of 15 total)
You must be logged in to reply to this topic. Login to reply