

tl;dr; The uniquifier is used to make a non-unique key in a clustered index unique.
Uniquifier is a rather funny name, and yet it’s very descriptive. If there is a key that must be made unique then SQL server will add a uniquifier to, well, make it unique.
Now, why would you want to do that?
Well, to start with, you need to think about how non-clustered indexes (NCIs) and clustered indexes (CIs) work. If a query uses an NCI to filter (or sort, or whatever) information but not all of the information needed is in the NCI then SQL has to go back to the CI to get that additional information. In order to do that it has to have a pointer back to the original row (contained in the clustered index) and just that row. That’s pretty easy if the clustered index is also a unique index, but it doesn’t have to be. You can create a non-unique clustered index. In the case of a non-unique clustered index SQL adds the uniquifier to make sure that the value is in fact unique.
Examples make life easier, so let’s say you have a table with a non-unique clustered index of CreateDate. You then insert 10 rows in a single batch.
CREATE TABLE NonUniqueCI ( CreateDate datetime NOT NULL CONSTRAINT df_CreateDate DEFAULT getdate() , Col1 int , index ci_NonUniqueCI clustered (CreateDate) ); INSERT INTO NonUniqueCI (Col1) SELECT TOP (10) 1 FROM sys.columns a; SELECT * FROM NonUniqueCI;
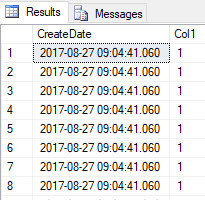
So we have a CI on CreateDate but every row is identical. How does SQL keep track of which row is which? To check we have to use the undocumented DBCC commands PAGE and IND so do NOT do this in production. It’s probably safe but undocumented means NO PRODUCTION!!
--Get the Page Number of the Clustered Index DBCC IND (Test, NonUniqueCI, -1) -- Create a table to store the results of the DBCC Page CREATE TABLE #DBCCResults ( [ParentObject] varchar(100), [Object] varchar(1000), [Field] varchar(100), [VALUE] varchar(max) ); -- Collect information about the page INSERT INTO #DBCCResults EXEC sp_executesql N'DBCC PAGE(Test, 1, 520, 3) WITH TABLERESULTS;'; -- View just the column information from the -- DBCC Page results SELECT * FROM #DBCCResults WHERE [Object] LIKE '%Column%' ORDER BY [Object];
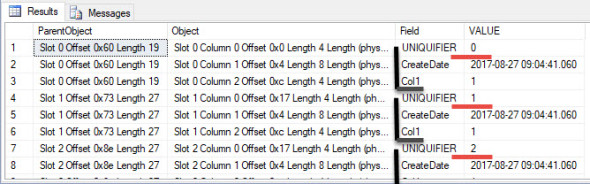
As you can see each row has a uniquifier that makes the row unique. With a combination of the clustered index key (in this case CreateDate) and the uniquifier we can uniquely identify each row.
Now, what happens if the values are in fact unique?
-- Insert 2 new rows INSERT INTO NonUniqueCI (Col1) VALUES (1); INSERT INTO NonUniqueCI (Col1) VALUES (1); -- Collect information about the page TRUNCATE TABLE #DBCCResults INSERT INTO #DBCCResults EXEC sp_executesql N'DBCC PAGE(Test, 1, 520, 3) WITH TABLERESULTS;'; -- View just the column information from the -- DBCC Page results SELECT * FROM #DBCCResults WHERE [Object] LIKE '%Column%' ORDER BY [Object];
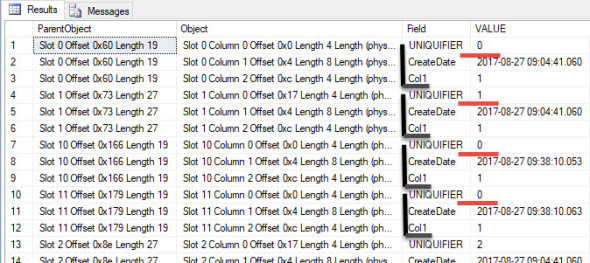
Notice how the uniquifier for the two new rows is a 0. That’s fine though since we don’t need that value to identify the row.
So now let’s start over and insert two sets of identical rows.
DROP TABLE NonUniqueCI; CREATE TABLE NonUniqueCI ( CreateDate datetime NOT NULL CONSTRAINT df_CreateDate DEFAULT getdate() , Col1 int , index ci_NonUniqueCI clustered (CreateDate) ); -- Load the table with two unique values INSERT INTO NonUniqueCI (Col1) VALUES (1); WAITFOR DELAY '00:00:00.003' -- guarantee unique value of getdate() INSERT INTO NonUniqueCI (Col1) VALUES (1); -- Insert duplicates of the first two rows. INSERT INTO NonUniqueCI SELECT * FROM NonUniqueCI --Get the new Page Number of the Clustered Index DBCC IND (Test, NonUniqueCI, -1) -- Collect information about the page TRUNCATE TABLE #DBCCResults INSERT INTO #DBCCResults EXEC sp_executesql N'DBCC PAGE(Test, 1, 568, 3) WITH TABLERESULTS;'; -- View just the column information from the -- DBCC Page results SELECT * FROM #DBCCResults WHERE [Object] LIKE '%Column%' ORDER BY [Object];
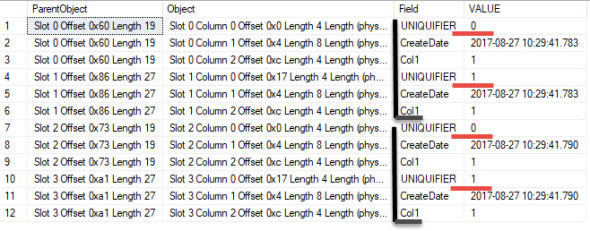
Notice that we have uniquifiers 0 and 1 for each pair of non-unique values. If I added a third there would be a 2 for that set of values. Etc.
Last piece of information (thank goodness?). The uniquifier is a variable length integer. Variable length integer? I’ve never heard of that before? Well, as I understand it it’s either 4 bytes (if in use) or 0 bytes (sort of) if not. So what do I mean by sort of? Even if it’s not in use there has to be a place to store it. Therefore there has to be a space for it in the variable-length column offset array. However, since that is a rather complicated subject (for me at least) I’m going to skip it for now.
Now, the uniquifier being an integer has an interesting effect. I saw a demo once (and no I’m not going to duplicate it) where someone inserted 2,147,483,647 (max int) identical values into a non-unique clustered index. After that, they could no longer insert that value any more. I don’t exactly consider this a big issue since if you have that many duplicate values it shouldn’t be your CI anyway. Still, it’s interesting from an academic point of view. Actually, 95% of everything about the uniquifier is academic really. The only important thing you need to know is that if you have a non-unique clustered index it’s going to be 4 bytes wider than you expected.
Note: I’d always read that a uniquifier was only added to a row if, and only if, it was needed to make the row unique. I didn’t see any evidence of this in the DBCC Page output. From what I can see it looks like there is always a uniquifier. I’ll be interested to see if anyone knows why that is?
Filed under: DBCC, Index, Microsoft SQL Server, SQLServerPedia Syndication, T-SQL Tagged: index, microsoft sql server, T-SQL 






![]()
