SQL Query to display having only values
-
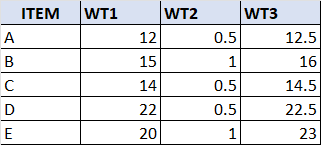
I am having below -mentioned table1 and

I would like to display it as shown in the below table
Can someone help me with the query
Thanks in advance
-
What are these WT1, WT2...... in the output? Why 15 has to be shown under WT1 for B and not in WT2?
You can use CASE WHEN THEN ELSE END and construct your groups
=======================================================================
-
I wanted to display the value which are greater than 0 in just 3 columns as shown in the table2 I wrote the below query but quite doesnt work
SELECT
ITEM
, COALESCE(PWT, SWT) AS WT1
, COALESCE(PNT, SNT) AS WT2
, COALESCE(PTT, STT) + COALESCE(TWT, 0) + COALESCE(TNT, 0) AS WT3
FROM table1
- Emperor100 wrote:
What are these WT1, WT2...... in the output? Why 15 has to be shown under WT1 for B and not in WT2?
You can use CASE WHEN THEN ELSE END and construct your groups
He's looking for something that will return only the non-zero values in the row from left to right. WT1, 2, and 3 are just substitute names for the non-zero data found from left to right.
If the OP would post some readily consumable data using a method like the one I demonstrate in the article at the first link in my signature line below, I'd be tempted to use the ol' unpivot non-zero values and repivot them using a CROSTAB trick instead of just saying that or writing some untested pseudo code and then playing 20 questions in 40 followup posts. 😀
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
The graphics you posted are great especially for showing the final result you wanted (which is the key to solving this problem without many words) but they're horrible for people that want to help you by posting actually working code.
With that being said, help those that would help you by posting "Readily Consumable Data", like the following, which is one of many methods that you can use.
--===== If it exists, drop the Temp Table to make reruns
-- in SSMS easier
DROP TABLE IF EXISTS #MyHead;
GO
--===== Create and populate the test table on-the-fly.
SELECT *
INTO #MyHead
FROM (VALUES
('A',12,.5,12.5,0,0,0,0,0,0)
,('B',0,0,0,0,0,0,15,1,16)
,('C',0,0,0,14,.5,14.5,0,0,0)
,('D',22,.5,22.5,0,0,0,0,0,0)
,('E',0,0,0,20,1,23,0,0,0)
)v(Item,PWT,PNT,PTT,SWT,SNT,STT,TWT,TNT,TTS)
;
--===== Add what seems to be the logical choice for a PK.
ALTER TABLE #MyHead ADD PRIMARY KEY CLUSTERED (Item)
;
GOHere's one solution where a CROSS APPLY is being used instead of an UNPIVOT. It turns your rows into an EAV (Entity, Attribute, Value) structure and numbers and returns only those rows that have a non-zero value. You can run the code that lives in the CTE to see what I mean by all of that.
Then, I simply use a CROSSTAB (which is usually faster than a PIVOT) to pivot those rows back in place according to the left-to-right ordinal values that the unpivot in the CTE assigned.
WITH cteUnpivot AS
(--==== The CROSS APPLY "unpivots" the data and assigns a "Sort Order" ordinal to each element
-- for each row identified by the ITEM column (PK).
-- The WHERE clause selects only those values with a non-zero value.
-- ROW_NUMBER() assigns a sequential ordinal in order by the SortOrder assign by the "unpivot".
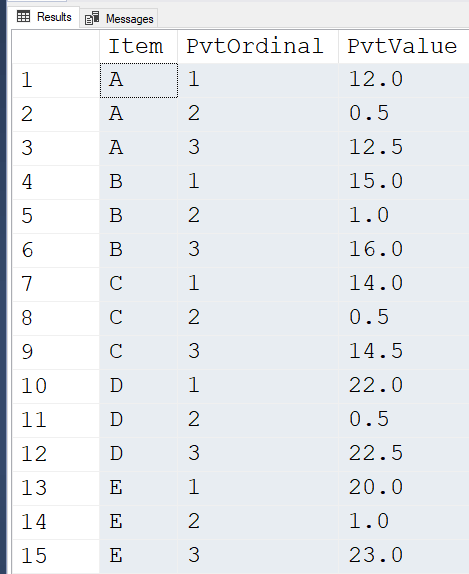
SELECT src.Item
,PvtOrdinal = ROW_NUMBER() OVER (PARTITION BY src.Item ORDER BY unpvt.SortOrder)
,PvtValue = unpvt.Value
FROM #MyHead src
CROSS APPLY (VALUES
(1,PWT)
,(2,PNT)
,(3,PTT)
,(4,SWT)
,(5,SNT)
,(6,STT)
,(7,TWT)
,(8,TNT)
,(9,TTS)
)unpvt(SortOrder,Value)
WHERE unpvt.Value <> 0
)--==== Do a CROSSTAB to pivot the data into place.
-- The PvtOrdinal remembers the order from left to right
-- that the values need to appear in.
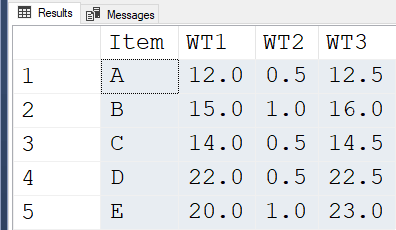
SELECT unpvt.Item
,WT1 = MAX(IIF(unpvt.PvtOrdinal = 1, PvtValue, 0))
,WT2 = MAX(IIF(unpvt.PvtOrdinal = 2, PvtValue, 0))
,WT3 = MAX(IIF(unpvt.PvtOrdinal = 3, PvtValue, 0))
FROM cteUnpivot unpvt
GROUP BY unpvt.Item
ORDER BY unpvt.Item
;Here's what the EAV looks like from the CTE... it won't appear in the output... just showing you what it does...
Here's the final output from all that...
Again, please... you have the data in a table or spreadsheet and it's pretty easy to generate the "Readily Consumble Data" from that to help out those that would help you. You'll always get better, coded, answers instead of mere suggestions like "Do an ordinal unpivot, enumerate the unpivoted data, and use a CROSSTAB to re-pvot the data back into place.
Here's a link on how CROSSTABs do the work. It's an old "Black Arts" technique that predates the PIVOT operator by more than a decade.
https://www.sqlservercentral.com/articles/cross-tabs-and-pivots-part-1-converting-rows-to-columns-1
Also, learn how to use the "code" window that's available at the menu at the top of the post-entry window. I highlighted the icon in a Red box below. It'll make your posts much more readable.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Given the column naming convention, I think there might be a simpler solution than using an EAV. This assumes that there are three sets of weights: PWT, PNT, and PTT is one set, SWT, SNT, and STT is another, and TWT, TNT, and TTS is the third. It further assumes that only one of these sets will have non-zero values.
SELECT mh.Item
, v.WT1
, v.WT2
, v.WT3
FROM #MyHead AS mh
CROSS APPLY
(
SELECT *
FROM (VALUES(mh.PWT, mh.PNT, mh.PTT)
,(mh.SWT, mh.SNT, mh.STT)
,(mh.TWT, mh.TNT, mh.TTS)
) v(WT1, WT2, WT3)
EXCEPT
SELECT 0,0,0
) vDrew
J. Drew Allen
Business Intelligence Analyst
Philadelphia, PA -
Assuming the pattern in the sample data is actually representative of your production data, the following would be simpler and more efficient as it eliminates the need to unpivot, sort and aggregate.
SELECT
mh.Item,
WT1 = COALESCE(NULLIF(mh.PWT, 0), NULLIF(mh.SWT, 0), NULLIF(mh.TWT, 0)),
WT2 = COALESCE(NULLIF(mh.PNT, 0), NULLIF(mh.SNT, 0), NULLIF(mh.TNT, 0)),
WT3 = COALESCE(NULLIF(mh.PTT, 0), NULLIF(mh.STT, 0), NULLIF(mh.TTS, 0))
FROM
#MyHead mh;This, of course, makes the assumption that the last 9 columns on original table are logically divided into 3 blocks of 3 columns each and that each row only uses one block.
- drew.allen wrote:
Given the column naming convention, I think there might be a simpler solution than using an EAV. This assumes that there are three sets of weights: PWT, PNT, and PTT is one set, SWT, SNT, and STT is another, and TWT, TNT, and TTS is the third. It further assumes that only one of these sets will have non-zero values.
SELECT mh.Item
, v.WT1
, v.WT2
, v.WT3
FROM #MyHead AS mh
CROSS APPLY
(
SELECT *
FROM (VALUES(mh.PWT, mh.PNT, mh.PTT)
,(mh.SWT, mh.SNT, mh.STT)
,(mh.TWT, mh.TNT, mh.TTS)
) v(WT1, WT2, WT3)
EXCEPT
SELECT 0,0,0
) vDrew
I saw that pattern of 3 and thought "nah.. that could be just a fluke". I missed the repeating pattern where only the first letter of the column names was changing is sets of 3. Thanks for pointing that out, Drew.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jason A. Long wrote:
Assuming the pattern in the sample data is actually representative of your production data, the following would be simpler and more efficient as it eliminates the need to unpivot, sort and aggregate.
SELECT
mh.Item,
WT1 = COALESCE(NULLIF(mh.PWT, 0), NULLIF(mh.SWT, 0), NULLIF(mh.TWT, 0)),
WT2 = COALESCE(NULLIF(mh.PNT, 0), NULLIF(mh.SNT, 0), NULLIF(mh.TNT, 0)),
WT3 = COALESCE(NULLIF(mh.PTT, 0), NULLIF(mh.STT, 0), NULLIF(mh.TTS, 0))
FROM
#MyHead mh;This, of course, makes the assumption that the last 9 columns on original table are logically divided into 3 blocks of 3 columns each and that each row only uses one block.
If the 3 pattern actually holds true (and I think it will even though I slept through that episode 😀 ), that's more like what the OP originally was trying and couldn't get running. It's also likely to be the fastest. Nicely done!
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
More proof of what I was talking about for the "Readily Consumable Data" thing. Two other folks saw a pattern that I'd missed and could easily test their solutions using the test data that I provided and they did so very quickly.
On code forums, "Readily Consumable Data" is king and it would take you no time to put it together because you already have data in a table to create it from programmaticaly.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Thanks a Ton You made my day This worked Perfectly


Viewing 11 posts - 1 through 11 (of 11 total)
You must be logged in to reply to this topic. Login to reply