Split field to top 4
-
I need to split the column 'DiagnosisCodes' into 4 new columns 'Diagnosis1', 'Diagnosis2', 'Diagnosis3' and 'Diagnosis4' for the unique ChartProcedureId's. If they add more DiagnosisCodes, I only need the top 4. Any assistance is appreciated.

-
If you would like a coded solution, please present your sample data in the form of CREATE TABLE/INSERT statements.
-
CREATE TABLE #Diags ([ChartProcedureId] UNIQUEIDENTIFIER, [DiagnosisCodes] VARCHAR(200))
INSERT INTO #Diags ([ChartProcedureId], [DiagnosisCodes]) VALUES ('8EAFEEBB-33A1-4FED-8A2C-50C3B6F2A1CF', 'K05.10,K05.11,K05.213')
INSERT INTO #Diags ([ChartProcedureId], [DiagnosisCodes]) VALUES ('BBB53D21-9FD5-4607-8816-D31BB5A84D2C', 'K05.10,K05.11,K05.213,K05.223')
INSERT INTO #Diags ([ChartProcedureId], [DiagnosisCodes]) VALUES ('D6EA12FE-4D23-42BB-89AC-DED166124E6F', 'K01.1,K02.7')
SELECT * FROM #Diags
-
and you may as well tell us HOW you determine which ones are the top 4. e.g. how do you order them on your query so they are on your desired output order.
and based on supplied data we should assume the delimiter is always a "," (comma)?
-
Correct, the delimiter is the comma.
-
This works except for the "Top 4" rule, but you can do that using CROSS APPLY.
use tempdb;
go
CREATE TABLE #Diags ([ChartProcedureId] UNIQUEIDENTIFIER, [DiagnosisCodes] VARCHAR(200))
INSERT INTO #Diags ([ChartProcedureId], [DiagnosisCodes]) VALUES ('8EAFEEBB-33A1-4FED-8A2C-50C3B6F2A1CF', 'K05.10,K05.11,K05.213')
INSERT INTO #Diags ([ChartProcedureId], [DiagnosisCodes]) VALUES ('BBB53D21-9FD5-4607-8816-D31BB5A84D2C', 'K05.10,K05.11,K05.213,K05.223')
INSERT INTO #Diags ([ChartProcedureId], [DiagnosisCodes]) VALUES ('D6EA12FE-4D23-42BB-89AC-DED166124E6F', 'K01.1,K02.7')
SELECT ChartProcedureID,
firstOne = MAX(CASE WHEN ItemNumber = 1 THEN Item ELSE NULL END),
secondOne = MAX(CASE WHEN ItemNumber = 2 THEN Item ELSE NULL END),
thirdOne = MAX(CASE WHEN ItemNumber = 3 THEN Item ELSE NULL END),
fourthOne = MAX(CASE WHEN ItemNumber = 4 THEN Item ELSE NULL END)
FROM
(SELECT d.ChartProcedureID, dc.Item, dc.ItemNumber
FROM #Diags d
CROSS APPLY scratch.dbo.DelimitedSplit8K(d.DiagnosisCodes,',') dc) splitData
GROUP BY ChartProcedureId; -
Can we see how "scratch.dbo.DelimitedSplit8K" does the spliting of the string?
Here is a function of my own that does the spliting:
create FUNCTION [dbo].[fn_tbl_StringParseByDelimiter](@InputString varchar(max), @Delimiter Varchar(30) )
/*
select * from [dbo].[fn_tbl_StringParseByDelimiter]('1111 222 33333', ' ')
select * from [dbo].[fn_tbl_StringParseByDelimiter]('1111 |222| 33333', '|')
select * from [dbo].[fn_tbl_StringParseByDelimiter]('1111 222 33333', '222')
select * from [dbo].[fn_tbl_StringParseByDelimiter]('1111 22,2 33333', ',')
*/
RETURNS @tblReturn table
(
Word varchar(50)
)
AS
begin
declare
@strWork varchar(1000)
, @strWord varchar(50)
, @intDelimiterPos int
set @strWork = @InputString
while len(@strWork) > 0
begin
set @intDelimiterPos = CHARINDEX ( @Delimiter, @strWork )
if @intDelimiterPos = 0
begin
set @strWord = @strWork
set @strWork = ''
end
else if @intDelimiterPos = 1
begin
set @strWord = ''
set @strWork = substring(@strWork, 2 , (len(@strWork) - 1) )
end
else
begin
set @strWord = substring(@strWork,1, (@intDelimiterPos - 1) )
set @strWork = substring(@strWork, (@intDelimiterPos + len(@Delimiter)) ,len(@strWork) )
end
if @strWord <> ''
insert into @tblReturn (Word)
values (@strWord)
end
return
end - aitorzur@hotmail.com wrote:
Can we see how "scratch.dbo.DelimitedSplit8K" does the spliting of the string?
Yes. Here's an article that explains how it works and why it's so fast. Don't use the code for that article, though. A good friend of mine () made yet another improvement to it when SQL Server 2012 came out. I've included his article, which contains an attachment for the improvement. It basically doubled the performance of an already very high performance function.
--===== The Pre-2012 version.
--===== The Post-2012 version (the explanation is is part 1 of that article and the code is an attachment to the article)
https://www.sqlservercentral.com/articles/reaping-the-benefits-of-the-window-functions-in-t-sql-2
With only extremely rare exceptions, I'm going to strongly recommend that WHILE loops should only for "flow control" of processes and not be used for data manipulation because it constitutes "RBAR".
I'm also going to recommend that Scalar Functions and mTVFs (multi-statement Table Valued Functions) be avoiding in T-SQL at all cost. Here's an article on the general performance issues. Scalar Functions are so bad that if you use one in a computed column, EVERY query that uses the table will go "Single Threaded" even if the column isn't used in the queries. To wit, if your function contains the word BEGIN, there's a 99.9999% chance that you've just created a performance problem even if the function is completely free of any other RBAR.
--===== How to make Scalar Functions Run Faster (hint: change them to non-RBAR iTVFs)
https://www.sqlservercentral.com/articles/how-to-make-scalar-udfs-run-faster-sql-spackle
--===== Multiple examples/proofs about Scalar Function performance issues
https://www.brentozar.com/archive/2020/11/how-scalar-user-defined-functions-slow-down-queries/
https://www.brentozar.com/archive/2020/10/using-triggers-to-replace-scalar-udfs-on-computed-columns/
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
I think you can beat any splitting function by splitting in code with no need for aggregation.
As there are only a maximum of 4 values you can safely use this which should be faster than other methods:
select T.[ChartProcedureId], Diagnosis1, Diagnosis2, Diagnosis3, Diagnosis4
from #Diags T
cross apply (values (CHARINDEX(',',T.[DiagnosisCodes], 1))) AS c1(CommaPos)
cross apply (values (IIF(c1.CommaPos>0, LEFT(T.[DiagnosisCodes],c1.CommaPos-1), T.[DiagnosisCodes]),(IIF(c1.CommaPos>0, SUBSTRING(T.[DiagnosisCodes],c1.CommaPos+1,8000), NULL)))) t1(Diagnosis1,RHS)
cross apply (values (CHARINDEX(',',t1.RHS))) c2(CommaPos)
cross apply (values (IIF(c2.CommaPos>0, LEFT(t1.RHS,c2.CommaPos-1), t1.RHS),(IIF(c2.CommaPos>0, SUBSTRING(t1.RHS,c2.CommaPos+1,8000), NULL)))) t2(Diagnosis2,RHS)
cross apply (values (CHARINDEX(',',t2.RHS))) c3(CommaPos)
cross apply (values (IIF(c3.CommaPos>0, LEFT(t2.RHS,c3.CommaPos-1), t2.RHS),(IIF(c3.CommaPos>0, SUBSTRING(t2.RHS,c3.CommaPos+1,8000), NULL)))) t3(Diagnosis3,RHS)
cross apply (values (CHARINDEX(',',t3.RHS))) c4(CommaPos)
cross apply (values (IIF(c4.CommaPos>0, LEFT(t3.RHS,c4.CommaPos-1), t3.RHS),(IIF(c4.CommaPos>0, SUBSTRING(t3.RHS,c4.CommaPos+1,8000), NULL)))) t4(Diagnosis4,RHS) - Jonathan AC Roberts wrote:
I think you can beat any splitting function by splitting in code with no need for aggregation.
As there are only a maximum of 4 values you can safely use this which should be faster than other methods:
select T.[ChartProcedureId], Diagnosis1, Diagnosis2, Diagnosis3, Diagnosis4
from #Diags T
cross apply (values (CHARINDEX(',',T.[DiagnosisCodes], 1))) AS c1(CommaPos)
cross apply (values (IIF(c1.CommaPos>0, LEFT(T.[DiagnosisCodes],c1.CommaPos-1), NULL),(IIF(c1.CommaPos>0, SUBSTRING(T.[DiagnosisCodes],c1.CommaPos+1,8000), NULL)))) t1(Diagnosis1,RHS)
cross apply (values (CHARINDEX(',',t1.RHS))) c2(CommaPos)
cross apply (values (IIF(c2.CommaPos>0, LEFT(t1.RHS,c2.CommaPos-1), t1.RHS),(IIF(c2.CommaPos>0, SUBSTRING(t1.RHS,c2.CommaPos+1,8000), NULL)))) t2(Diagnosis2,RHS)
cross apply (values (CHARINDEX(',',t2.RHS))) c3(CommaPos)
cross apply (values (IIF(c3.CommaPos>0, LEFT(t2.RHS,c3.CommaPos-1), t2.RHS),(IIF(c3.CommaPos>0, SUBSTRING(t2.RHS,c3.CommaPos+1,8000), NULL)))) t3(Diagnosis3,RHS)
cross apply (values (CHARINDEX(',',t3.RHS))) c4(CommaPos)
cross apply (values (IIF(c4.CommaPos>0, LEFT(t3.RHS,c4.CommaPos-1), t3.RHS),(IIF(c4.CommaPos>0, SUBSTRING(t3.RHS,c4.CommaPos+1,8000), NULL)))) t4(Diagnosis4,RHS)It would be interesting to do a performance test on that especially for items that have fewer or greater than exactly 4 items.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:Jonathan AC Roberts wrote:
I think you can beat any splitting function by splitting in code with no need for aggregation.
As there are only a maximum of 4 values you can safely use this which should be faster than other methods:
select T.[ChartProcedureId], Diagnosis1, Diagnosis2, Diagnosis3, Diagnosis4
from #Diags T
cross apply (values (CHARINDEX(',',T.[DiagnosisCodes], 1))) AS c1(CommaPos)
cross apply (values (IIF(c1.CommaPos>0, LEFT(T.[DiagnosisCodes],c1.CommaPos-1), T.[DiagnosisCodes]),(IIF(c1.CommaPos>0, SUBSTRING(T.[DiagnosisCodes],c1.CommaPos+1,8000), NULL)))) t1(Diagnosis1,RHS)
cross apply (values (CHARINDEX(',',t1.RHS))) c2(CommaPos)
cross apply (values (IIF(c2.CommaPos>0, LEFT(t1.RHS,c2.CommaPos-1), t1.RHS),(IIF(c2.CommaPos>0, SUBSTRING(t1.RHS,c2.CommaPos+1,8000), NULL)))) t2(Diagnosis2,RHS)
cross apply (values (CHARINDEX(',',t2.RHS))) c3(CommaPos)
cross apply (values (IIF(c3.CommaPos>0, LEFT(t2.RHS,c3.CommaPos-1), t2.RHS),(IIF(c3.CommaPos>0, SUBSTRING(t2.RHS,c3.CommaPos+1,8000), NULL)))) t3(Diagnosis3,RHS)
cross apply (values (CHARINDEX(',',t3.RHS))) c4(CommaPos)
cross apply (values (IIF(c4.CommaPos>0, LEFT(t3.RHS,c4.CommaPos-1), t3.RHS),(IIF(c4.CommaPos>0, SUBSTRING(t3.RHS,c4.CommaPos+1,8000), NULL)))) t4(Diagnosis4,RHS)It would be interesting to do a performance test on that especially for items that have fewer or greater than exactly 4 items.
Here is some code to generate a million rows of test data:
drop table if exists #Diags
go
-- Create some test data (1 million rows with up to 20 items in the comma seperated list)
with cte as
(
select n , DiagnosisCode
from dbo.fnTally(1,1000000)
cross apply (values ((ABS(CHECKSUM(NewId())) % 20) + 1)) t(RandomInt)
cross apply (select LEFT(NEWID(), 6) from dbo.fnTally(1,RandomInt)) x(DiagnosisCode)
)
select NEWID() ChartProcedureId, STRING_AGG(DiagnosisCode,',') DiagnosisCodes
into #Diags
from cte
group by n
; - Jonathan AC Roberts wrote:Jeff Moden wrote:Jonathan AC Roberts wrote:
I think you can beat any splitting function by splitting in code with no need for aggregation.
As there are only a maximum of 4 values you can safely use this which should be faster than other methods:
select T.[ChartProcedureId], Diagnosis1, Diagnosis2, Diagnosis3, Diagnosis4
from #Diags T
cross apply (values (CHARINDEX(',',T.[DiagnosisCodes], 1))) AS c1(CommaPos)
cross apply (values (IIF(c1.CommaPos>0, LEFT(T.[DiagnosisCodes],c1.CommaPos-1), T.[DiagnosisCodes]),(IIF(c1.CommaPos>0, SUBSTRING(T.[DiagnosisCodes],c1.CommaPos+1,8000), NULL)))) t1(Diagnosis1,RHS)
cross apply (values (CHARINDEX(',',t1.RHS))) c2(CommaPos)
cross apply (values (IIF(c2.CommaPos>0, LEFT(t1.RHS,c2.CommaPos-1), t1.RHS),(IIF(c2.CommaPos>0, SUBSTRING(t1.RHS,c2.CommaPos+1,8000), NULL)))) t2(Diagnosis2,RHS)
cross apply (values (CHARINDEX(',',t2.RHS))) c3(CommaPos)
cross apply (values (IIF(c3.CommaPos>0, LEFT(t2.RHS,c3.CommaPos-1), t2.RHS),(IIF(c3.CommaPos>0, SUBSTRING(t2.RHS,c3.CommaPos+1,8000), NULL)))) t3(Diagnosis3,RHS)
cross apply (values (CHARINDEX(',',t3.RHS))) c4(CommaPos)
cross apply (values (IIF(c4.CommaPos>0, LEFT(t3.RHS,c4.CommaPos-1), t3.RHS),(IIF(c4.CommaPos>0, SUBSTRING(t3.RHS,c4.CommaPos+1,8000), NULL)))) t4(Diagnosis4,RHS)It would be interesting to do a performance test on that especially for items that have fewer or greater than exactly 4 items.
Here is some code to generate a million rows of test data:
drop table if exists #Diags
go
-- Create some test data (1 million rows with up to 20 items in the comma seperated list)
with cte as
(
select n , DiagnosisCode
from dbo.fnTally(1,1000000)
cross apply (values ((ABS(CHECKSUM(NewId())) % 20) + 1)) t(RandomInt)
cross apply (select LEFT(NEWID(), 6) from dbo.fnTally(1,RandomInt)) x(DiagnosisCode)
)
select NEWID() ChartProcedureId, STRING_AGG(DiagnosisCode,',') DiagnosisCodes
into #Diags
from cte
group by n
;Heh... so do the test, Jonathan. 😉 You made the suggestion. Prove that you're right because most people simply won't take the time. 😉
p.s. Nice rendition of the test data, BTW!
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:Jonathan AC Roberts wrote:Jeff Moden wrote:Jonathan AC Roberts wrote:
I think you can beat any splitting function by splitting in code with no need for aggregation.
As there are only a maximum of 4 values you can safely use this which should be faster than other methods:
select T.[ChartProcedureId], Diagnosis1, Diagnosis2, Diagnosis3, Diagnosis4
from #Diags T
cross apply (values (CHARINDEX(',',T.[DiagnosisCodes], 1))) AS c1(CommaPos)
cross apply (values (IIF(c1.CommaPos>0, LEFT(T.[DiagnosisCodes],c1.CommaPos-1), T.[DiagnosisCodes]),(IIF(c1.CommaPos>0, SUBSTRING(T.[DiagnosisCodes],c1.CommaPos+1,8000), NULL)))) t1(Diagnosis1,RHS)
cross apply (values (CHARINDEX(',',t1.RHS))) c2(CommaPos)
cross apply (values (IIF(c2.CommaPos>0, LEFT(t1.RHS,c2.CommaPos-1), t1.RHS),(IIF(c2.CommaPos>0, SUBSTRING(t1.RHS,c2.CommaPos+1,8000), NULL)))) t2(Diagnosis2,RHS)
cross apply (values (CHARINDEX(',',t2.RHS))) c3(CommaPos)
cross apply (values (IIF(c3.CommaPos>0, LEFT(t2.RHS,c3.CommaPos-1), t2.RHS),(IIF(c3.CommaPos>0, SUBSTRING(t2.RHS,c3.CommaPos+1,8000), NULL)))) t3(Diagnosis3,RHS)
cross apply (values (CHARINDEX(',',t3.RHS))) c4(CommaPos)
cross apply (values (IIF(c4.CommaPos>0, LEFT(t3.RHS,c4.CommaPos-1), t3.RHS),(IIF(c4.CommaPos>0, SUBSTRING(t3.RHS,c4.CommaPos+1,8000), NULL)))) t4(Diagnosis4,RHS)It would be interesting to do a performance test on that especially for items that have fewer or greater than exactly 4 items.
Here is some code to generate a million rows of test data:
drop table if exists #Diags
go
-- Create some test data (1 million rows with up to 20 items in the comma seperated list)
with cte as
(
select n , DiagnosisCode
from dbo.fnTally(1,1000000)
cross apply (values ((ABS(CHECKSUM(NewId())) % 20) + 1)) t(RandomInt)
cross apply (select LEFT(NEWID(), 6) from dbo.fnTally(1,RandomInt)) x(DiagnosisCode)
)
select NEWID() ChartProcedureId, STRING_AGG(DiagnosisCode,',') DiagnosisCodes
into #Diags
from cte
group by n
;Heh... so do the test, Jonathan. 😉 You made the suggestion. Prove that you're right because most people simply won't take the time. 😉
p.s. Nice rendition of the test data, BTW!
Here is a script that will test it, I also included a test for DelimitedSplit8K_LEAD.
set statistics io, time off
go
drop table if exists #Diags
go
-- Create some test data (1 million rows with up to 20 items in the comma seperated list)
with cte as
(
select n , DiagnosisCode
from dbo.fnTally(1,1000000)
cross apply (values ((ABS(CHECKSUM(NewId())) % 20) + 1)) t(RandomInt)
cross apply (select LEFT(NEWID(), 6) from dbo.fnTally(1,RandomInt)) x(DiagnosisCode)
)
select NEWID() ChartProcedureId, STRING_AGG(DiagnosisCode,',') DiagnosisCodes
into #Diags
from cte
group by n
;
--select * from #Diags
set statistics io, time on
go
drop table if exists #crossApplys
go
PRINT '****************************** #crossApplys'
select T.[ChartProcedureId], Diagnosis1, Diagnosis2, Diagnosis3, Diagnosis4
into #crossApplys
from #Diags T
cross apply (values (CHARINDEX(',',T.[DiagnosisCodes], 1))) AS c1(CommaPos)
cross apply (values (IIF(c1.CommaPos>0, LEFT(T.[DiagnosisCodes],c1.CommaPos-1), T.[DiagnosisCodes]),(IIF(c1.CommaPos>0, SUBSTRING(T.[DiagnosisCodes],c1.CommaPos+1,8000), NULL)))) t1(Diagnosis1,RHS)
cross apply (values (CHARINDEX(',',t1.RHS))) c2(CommaPos)
cross apply (values (IIF(c2.CommaPos>0, LEFT(t1.RHS,c2.CommaPos-1), t1.RHS),(IIF(c2.CommaPos>0, SUBSTRING(t1.RHS,c2.CommaPos+1,8000), NULL)))) t2(Diagnosis2,RHS)
cross apply (values (CHARINDEX(',',t2.RHS))) c3(CommaPos)
cross apply (values (IIF(c3.CommaPos>0, LEFT(t2.RHS,c3.CommaPos-1), t2.RHS),(IIF(c3.CommaPos>0, SUBSTRING(t2.RHS,c3.CommaPos+1,8000), NULL)))) t3(Diagnosis3,RHS)
cross apply (values (CHARINDEX(',',t3.RHS))) c4(CommaPos)
cross apply (values (IIF(c4.CommaPos>0, LEFT(t3.RHS,c4.CommaPos-1), t3.RHS),(IIF(c4.CommaPos>0, SUBSTRING(t3.RHS,c4.CommaPos+1,8000), NULL)))) t4(Diagnosis4,RHS)
go
drop table if exists #DelimitedSplit8K
go
PRINT '****************************** #DelimitedSplit8K'
SELECT ChartProcedureID,
firstOne = MAX(CASE WHEN ItemNumber = 1 THEN Item ELSE NULL END),
secondOne = MAX(CASE WHEN ItemNumber = 2 THEN Item ELSE NULL END),
thirdOne = MAX(CASE WHEN ItemNumber = 3 THEN Item ELSE NULL END),
fourthOne = MAX(CASE WHEN ItemNumber = 4 THEN Item ELSE NULL END)
into #DelimitedSplit8K
FROM
(SELECT d.ChartProcedureID, dc.Item, dc.ItemNumber
FROM #Diags d
CROSS APPLY dbo.DelimitedSplit8K(d.DiagnosisCodes,',') dc) splitData
GROUP BY ChartProcedureId;
go
drop table if exists #DelimitedSplit8K_LEAD
go
PRINT '****************************** #DelimitedSplit8K_LEAD'
SELECT ChartProcedureID,
firstOne = MAX(CASE WHEN ItemNumber = 1 THEN Item ELSE NULL END),
secondOne = MAX(CASE WHEN ItemNumber = 2 THEN Item ELSE NULL END),
thirdOne = MAX(CASE WHEN ItemNumber = 3 THEN Item ELSE NULL END),
fourthOne = MAX(CASE WHEN ItemNumber = 4 THEN Item ELSE NULL END)
into #DelimitedSplit8K_LEAD
FROM
(SELECT d.ChartProcedureID, dc.Item, dc.ItemNumber
FROM #Diags d
CROSS APPLY dbo.[DelimitedSplit8K_LEAD](d.DiagnosisCodes,',') dc) splitData
GROUP BY ChartProcedureId;Here are the results:
****************************** #crossApplys
Table '#Diags______________________________________________________________________________________________________________0000000000B8'. Scan count 5, logical reads 12621, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
SQL Server Execution Times:
CPU time = 56237 ms, elapsed time = 15769 ms.
(1000000 rows affected)****************************** #DelimitedSplit8K
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 6525, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table '#Diags______________________________________________________________________________________________________________0000000000B8'. Scan count 5, logical reads 12621, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
SQL Server Execution Times:
CPU time = 106422 ms, elapsed time = 76950 ms.
Warning: Null value is eliminated by an aggregate or other SET operation.
(1000000 rows affected)****************************** #DelimitedSplit8K_LEAD
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table '#Diags______________________________________________________________________________________________________________0000000000B8'. Scan count 5, logical reads 12621, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
SQL Server Execution Times:
CPU time = 108313 ms, elapsed time = 66068 ms.
Warning: Null value is eliminated by an aggregate or other SET operation.
(1000000 rows affected)So in summary
Cross Apply: CPU time = 56237 ms, elapsed time = 15769 ms.
DelimitedSplit8K: CPU time = 106422 ms, elapsed time = 76950 ms.
DelimitedSplit8K _LEAD: CPU time = 108313 ms, elapsed time = 66068 ms.
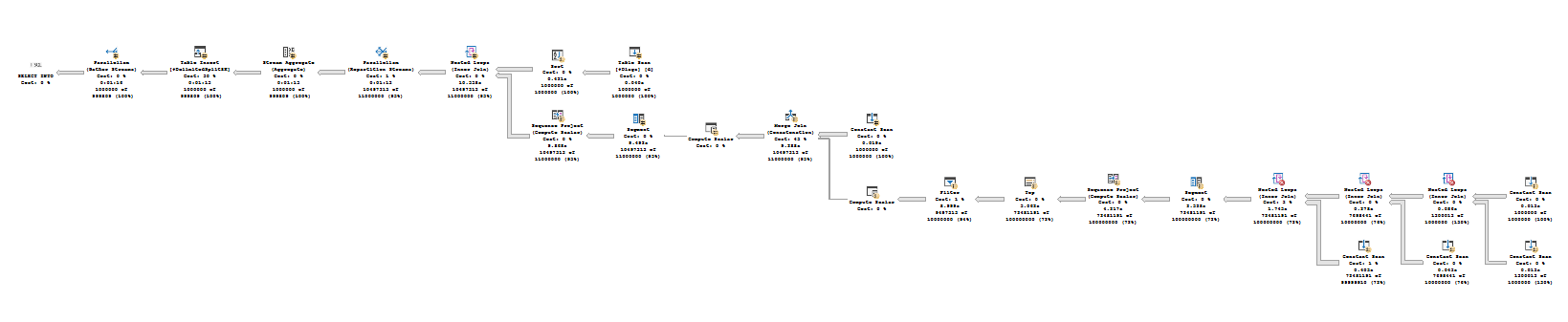
You can see the query plans are a lot more complicated for the splitter methods:
Cross Apply
DelimitedSplit8K
DelimitedSplit8K_LEAD
- Jeffs1977 wrote:
I need to split the column 'DiagnosisCodes' into 4 new columns 'Diagnosis1', 'Diagnosis2', 'Diagnosis3' and 'Diagnosis4' for the unique ChartProcedureId's. If they add more DiagnosisCodes, I only need the top 4. Any assistance is appreciated.
Let's talk about the REAL issue here, folks...
THIS IS AN EXTREMELY DANGEROUS REQUEST AND SHOULD NOT ACTUALLY BE FULFILLED!!! There is nothing in the data to "weigh" the severity of any of the diagnosis codes and so no way to put them in order of severity. That means that (as an example) out of 5 diagnosis, the first 4 might be related to a hang-nail while the 5th, which would not be included. might be for septicemia because of one of those hang-nails, which is a systemic infection of the blood that can quickly lead to death if not treated soon enough.
Until this can be resolved with the folks that are asking you for this, I'd simply refuse to deliver any code because it could actually lead to someone's death. I'd "take it to the top" if someone insisted on delivery of this really dangerous code. If even the "top" insisted on it's delivery, I'd make sure they heard about it on the morning news along with all the proof necessary to make it all stick.
p.s. If this is an example problem in an SQL or other Class, I'd put the hammer on them for NOT teaching a "little" thing called "Responsibility for Code".
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Freakin' awesome test post, Jonathan. Well done, good Sir!!! This also proves something else... code written to do a specific task is highly likely to blow generic methods out of the water!
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)



Viewing 15 posts - 1 through 15 (of 16 total)
You must be logged in to reply to this topic. Login to reply