Use of an NCI - that does not contain the Column required.
-
Hello.
I am a bit confused and not sure what terms to use to Google.
I have a transaction that overran this week and DPA gave me an Estimated Execution Plan that showed a Missing Index Hint - which I understand.
The Table has 3.5Million Rows and the SQL is doing an Equality Search in an IF Exists statement and it is dong an NCI Index scan because there is not Index on the required column - which I can get my head around.
What I don't get is that the NCI stated in the Estimated Execution Plan does not include the required column - it is not a Key Column, an Included Column or a 'hidden' column so I don't know how or what it is used (vs the CI). I am going to recreate this in Test with Actual Execution Plan to ensure that this is not an Estimated Plan anomaly. The NCI in the plan has 1 key column (not DraftNum) - and no Included columns - and Draftnum is not the Primary Key in the CI - so how can it use this Index to do anything.
The other thing that I have not seen in an execution plan (or noticed) is a Constant Scan - and reading up on that I don't see what that is doing or if it is relevant.
Obviously I could create an NCI based on the Missing Index Hint but do not understand what the plan is telling me as I have not come across this before.
I have pasted a copy of the plan - if it is preferred to post to something like PastethePlan (?) - please delete but I see that SQLPLAN is an allowed File type.
Thanks in Advance.
Steve O.
-
you need to use pastetheplan - loading the file fails
-
A Constant Scan is basically adding a column to the data being passed around. Look at the properties and it will define what it is adding. It may be something cryptic, in which case you'll have to look through the rest of the operaters to understand what that represents, or it could be really clear, an alias or something in the T-SQL.
You can use PasteThePlan. You can also zip the plan and post that zip file (which, a lot of people aren't crazy about, but it's one way to do it).
Something is of use in the NCI or the execution plan wouldn't reference it. It's scanning for a value or something that it can use in filtering elsewhere in the plan. I can't say much more without seeing the plan itself.
Also, no idea what you mean by an "anomaly in an estimated plans". All plans are estimated plans. An actual plan is just an estimated plan with the addition of runtime metrics. Extremely useful, don't get me wrong, but not radically different from an estimated plan. It's the same plan, plus runtime metrics. That's a huge point that people frequently lose the thread on. Can you see a difference between an estimated plan and an actual plan? Yes. But that is the result of recompiles normally, so, not some kind of bug in estimated plans.
The naming convention, estimated versus actual, leads to confusion. I have taken to referring to execution plans, and execution plans with runtime metrics. Makes things much more clear. However, people don't understand me, so I have to then say (estimated) and (actual) to clarify. Ugh!
Anyhow, for detail, make the plan available somehow.
"The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood"
- Theodore RooseveltAuthor of:
SQL Server Execution Plans
SQL Server Query Performance Tuning -
Thanks Grant.
It looks like it didn't like the .sqlplan file type after all even though it is an allowed file type so I have tried using PasteThePlan for the first time :
https://www.brentozar.com/pastetheplan/?id=rkMbXrFhi
Thanks for the info on Estimated vs Actual - I never appreciated the difference and wondered what to infer from the names.
From the plan you can see which NCI it used - not sure how to provide the Index column info to show that is does not include the required column?
Steve O.
-
what is the definition of the clustered index. My guess is that it includes "DraftNum " as one of its columns.
this based on the definition of a non clustered key.
The pointer from an index row in a nonclustered index to a data row is called a row locator. The structure of the row locator depends on whether the data pages are stored in a heap or a clustered table. For a heap, a row locator is a pointer to the row. For a clustered table, the row locator is the clustered index key.
-
[RSSQLDB].[dbo].[RSINVOICE].[DraftNum]=[@DraftNum]
DraftNum is in that index somewhere. It's a key, an include column, or as Frederico says, part of the clustered index key. Above is from the predicate of the index scan operator.
The constant scan in this case provides an empty row set. If no values match from the scan through the loop join, there's still a result set for the compute scalar to test. It's testing the value from the join, meaning, is there any data there. If so, the Expr1004 will have something in it so Expr1003 will return a positive.
"The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood"
- Theodore RooseveltAuthor of:
SQL Server Execution Plans
SQL Server Query Performance Tuning -
Thanks Both - I understand what you are saying and it had to be there somewhere but I am still a bit lost since the CI is not referenced in the plan. Is it that my recollection incorrect and it is the Clustering key columns that are always included in the NCI as hidden columns - which would make sense. For some reason I thought it was the PK but I can see now that would explain it?
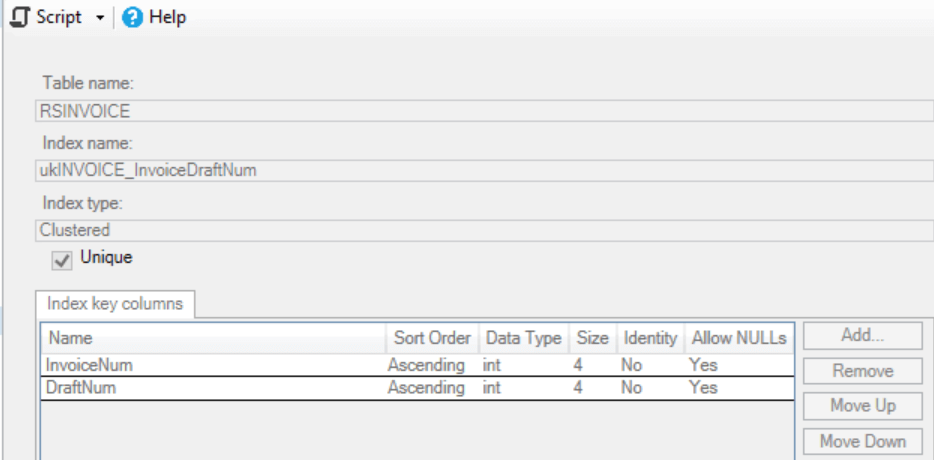
Here is a snip for the CI (the Table) and as you say it is in the Cluster Key - (although neither column are the PK)

-
There it is.
Every non-clustered index includes the key for the clustered index (or, an ID for a heap) so that from the non-clustered index, you can get to the appropriate row in the clustered index.
The optimizer knows this. So, it's looking at the non-clustered index, realizing it needs to scan it or scan the clustered index. On a bet, the non-clustered index has fewer pages, therefore, scans there are going to be faster.
That's why you're not seeing the clustered index anywhere in the plan. It's not needed because the clustered key values are available in the non-clustered index.
"The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood"
- Theodore RooseveltAuthor of:
SQL Server Execution Plans
SQL Server Query Performance Tuning -
Thanks again.
I think that from what I am reading the Default Clustering Key for the CI is the Primary Key, but this can be changed, which is probably where my confusion came from. I have been doing some digging, and see that there are methods that can be used to be able to 'see' the Clustering Key columns in the NCI.
Presumably the IF EXISTS will cause a scan on the NCI (3.5 million rows) and stop at the first hit - unless the Draft does not exist - in which case it will have to scan the whole 3.5 million rows every time? So adding an Index based on the Missing Index hint would enable a Seek straight to the record - or identify that it does not exist straight away?
I don't think that Paste the Plan has preserved the Missing Index Hint - but unsuprisingly it looks like this:
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>]
ON [dbo].[RSINVOICE] ([DraftNum])
I will go and create this in Test and see what difference it makes.
Regards
Steve O.
-
As Above - I ran in test for a Draft that did exist and one that didn't.
Where the Draft existed (1000000) the Number of Rows Read in the Actual Execution Plan indicated that it stopped when the Draft was found (the clustering key is ASC based on InvoiceNum / DraftNum so the number of rows read is similar to DraftNum).
Where the Draft did not exist (5000000) the Number of Rows Read is equal to the number of Rows in the Table/CI (3.5M)
When I added the missing Index I get an Index Seek using the New Index that either returns 1 or 0 Rows dependent in whether the DraftNum exists.
In terms of elapsed time the difference is negligible - at least running out of hours - but this code is executed several tens of thousands of times in the space of a few hours so 'maybe' worth pursuing as part of the bigger picture,
Thanks All.
Steve O,
Viewing 10 posts - 1 through 10 (of 10 total)
You must be logged in to reply to this topic. Login to reply