Dimension start and end dates
-
Hi, I'm looking for some advice on how you would handle a situation I have with a data warehouse.
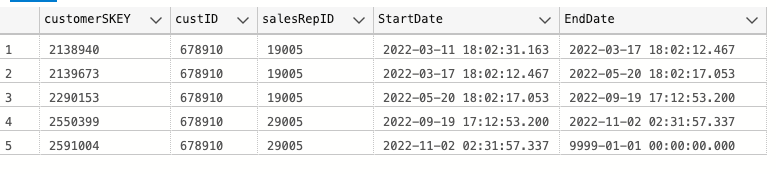
We have a customer dimension that looks like this for customer # 678910 (the actual dimension has many more attributes about a customer, for simplicity's sake I'm including only salesRepID):

The StartDate / EndDate columns are the date/time of when the data warehouse etl job was executed (meaning the date stamp when the merge statement inserted/expired the records).
When a customer's sales rep changes, the change should apply at the beginning of the day. For example, customerID's salesRepID changed from 19005 to 29005 on 9.19 (row 4 / customerSKEY 2550399 in the screenshot above). That change should affect all sales on that day.
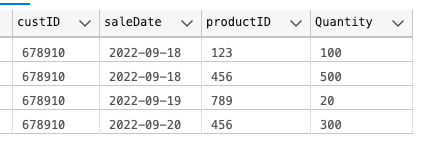
This is what a sales record looks like coming from our source system:
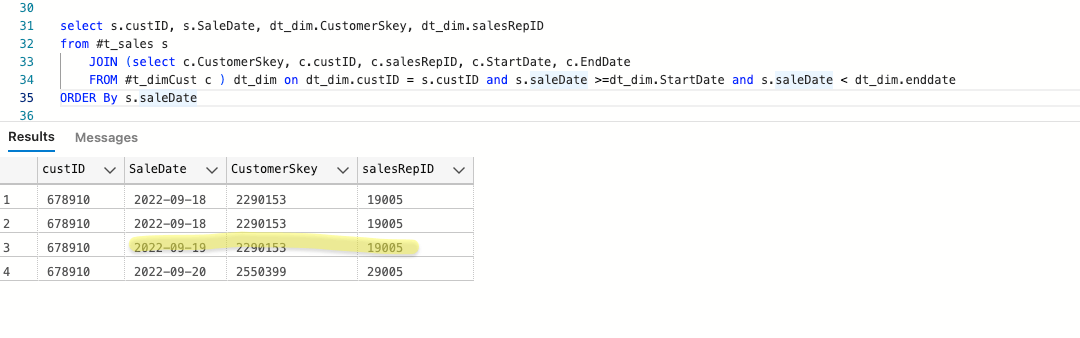
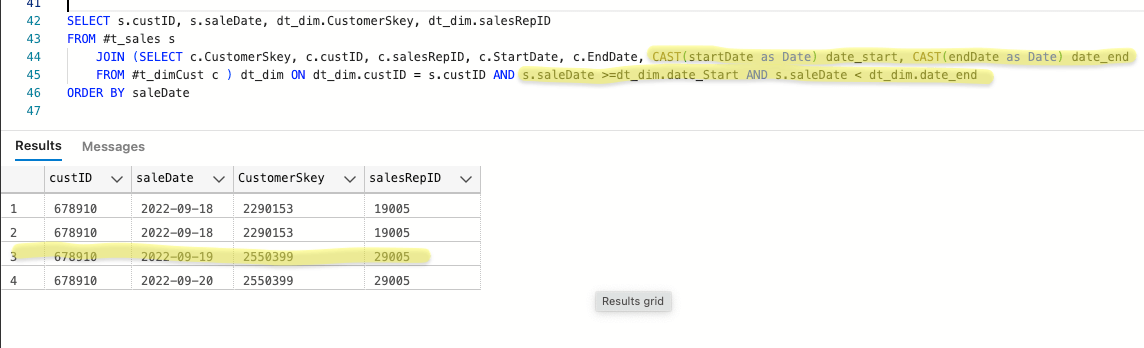
When we write to our sales fact table we want to write the Customer Surrogate Key of 2550399 for the sale on the 9.19. However, because the StartDate and EndDates in our dimension are date time data types and that record "started" at 17:12, comparison using StartDate / EndDate to SaleDate does not give us the results we want (to be "correct" the highlighted record below should have a customerSkey /salesRepID of 2550399 / 29005 respectively):
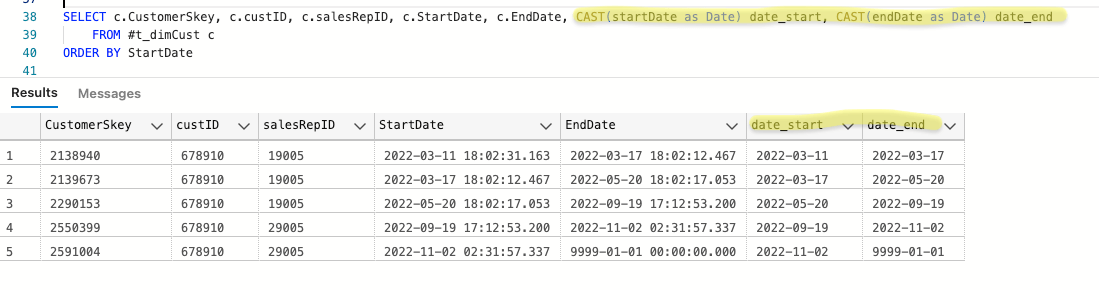
My "fix" is to cast the StartDate / EndDate columns to dates in separate columns named date_start, date_end:
and use date_start, date_end columns in the comparison, which results in what we want:
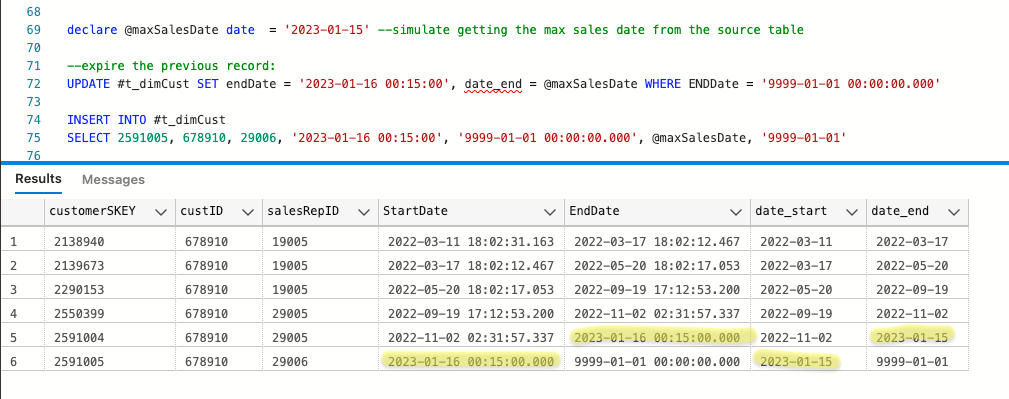
Further complicating this, is that our ETL job now runs after midnight, so if we get changes for a customer, the startDate / endDate columns will be populated with the next day's dates. For example, let's say the ETL job ran at 12:15am on 1.16 and detected a difference in the customer dimension (the salesRepID changed from 29005 to 29006). The max sales date in our source system is 1.15 and that change should apply to all sales on 1.15.
My thought to "fix" this is to add the two additional date columns to the customer dimension and when the dimension is populated set the date_start / date_end columns to the max sales date. So, the values in the StartDate / EndDates would stay the same (when the records were inserted/updated) and the values in the date_start / date_end columns would be the max sales date. (in the query below I've shown how I would insert new / expire the previous using the max sales date).
Part of my reason for having those additional columns is based on what we are going to have to do to correct the records currently in the customer dimension table. It could be messy. For example, because we've changed the timing of when our warehouse job executes multiple times --5pm, 6pm, 2:30am and have finally settled on 12:15am-- the current records that have a StartTime after 3am will have a date_start of that day and those with a StartDate before 3am will have a date_start of the previous day. I'm trying to correct historical records to be "right" and insert new records as "right" when we insert them.
So my question to this forum is --how would you handle this situation? Here is my sample data:
drop table if exists #t_dimCust
Create table #t_dimCust ( customerSKEY int, custID int, salesRepID int, StartDate datetime, EndDate datetime)
INSERT INTO #t_dimCust ( customerSKEY, custID, salesRepID, StartDate, EndDate)
VALUES (2591004,678910,29005,'2022-11-02 02:31:57.337', '9999-01-01 00:00:00.000'),
(2550399,678910,29005,'2022-09-19 17:12:53.200','2022-11-02 02:31:57.337'),
(2290153,678910, 19005, '2022-05-20 18:02:17.053','2022-09-19 17:12:53.200'),
(2139673,678910,19005,'2022-03-17 18:02:12.467','2022-05-20 18:02:17.053'),
(2138940,678910,19005,'2022-03-11 18:02:31.163','2022-03-17 18:02:12.467')
select * FROM #t_dimCust
ORDER BY startDate
select c.customerSKEY, c.custID, c.StartDate, c.EndDate
FROM dw.dimCUSTOMERS c
WHERE custID = 1904
order by startDate desc
drop table if exists #t_sales
SELECT 678910 as custID, '2022-09-18' as saleDate, 123 as productID, 100 as Quantity into #t_sales
UNION ALL
SELECT 678910 as custID, '2022-09-18' as saleDate, 456 as productID, 500 as Quantity
UNION ALL
SELECT 678910 as custID, '2022-09-19' as saleDate, 789 as productID, 20 as Quantity
UNION ALL
SELECT 678910 as custID, '2022-09-20' as saleDate, 456 as productID, 300 as Quantity
--select * from #t_sales s
select s.custID, s.SaleDate, dt_dim.CustomerSkey, dt_dim.salesRepID
from #t_sales s
JOIN (select c.CustomerSkey, c.custID, c.salesRepID, c.StartDate, c.EndDate
FROM #t_dimCust c ) dt_dim on dt_dim.custID = s.custID and s.saleDate >=dt_dim.StartDate and s.saleDate < dt_dim.enddate
ORDER By s.saleDate
SELECT c.CustomerSkey, c.custID, c.salesRepID, c.StartDate, c.EndDate, CAST(startDate as Date) date_start, CAST(endDate as Date) date_end
FROM #t_dimCust c
ORDER BY StartDate
SELECT s.custID, s.saleDate, dt_dim.CustomerSkey, dt_dim.salesRepID
FROM #t_sales s
JOIN (SELECT c.CustomerSkey, c.custID, c.salesRepID, c.StartDate, c.EndDate, CAST(startDate as Date) date_start, CAST(endDate as Date) date_end
FROM #t_dimCust c ) dt_dim ON dt_dim.custID = s.custID AND s.saleDate >=dt_dim.date_Start AND s.saleDate < dt_dim.date_end
ORDER BY saleDate
-----
--add the new columns
alter table #t_dimCust
ADD date_start date, date_end date
update #t_dimCust
SET date_start = CAST(startDate as Date)
update #t_dimCust
SET date_end = CAST(endDate as Date)
WHERE customerSkey NOT IN (2591004)
/* SELECT * from #t_dimCust
ORDER By startDate */-------
declare @maxSalesDate date = '2023-01-15' --simulate getting the max sales date from the source table
--expire the previous record:
UPDATE #t_dimCust SET endDate = '2023-01-16 00:15:00', date_end = @maxSalesDate WHERE ENDDate = '9999-01-01 00:00:00.000'
INSERT INTO #t_dimCust
SELECT 2591005, 678910, 29006, '2023-01-16 00:15:00', '9999-01-01 00:00:00.000', @maxSalesDate, '9999-01-01' -
It seems tricky to wade in on this because maybe it's ok the way you're doing it. Or idk maybe more than one thing is amiss. Why add columns in #t_dimCust to store 'CAST(startDate as Date) date_start, CAST(endDate as Date) date_end' when the information is linearly dependent and derivable by query? For indexing and read performance are legit reasons for a data warehouse imo. What difference does the 'date_end' make when updating the sales? If there are no sales on the 16th there's nothing to update so it's ok?
Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
- jmetape wrote:
When a customer's sales rep changes, the change should apply at the beginning of the day. For example, customerID's salesRepID changed from 19005 to 29005 on 9.19 (row 4 / customerSKEY 2550399 in the screenshot above). That change should affect all sales on that day.
That is the key to your answer, I think. I also think that there may be a flaw in the logic.
I think the addition of a single datetime column to hold the "date sales rep started" would solve the issue. But the flaw that may be there is what happens to historical records? If company 1 has sales rep 99 assigned from 1/1 to 1/31, and then is assigned sales rep 100 on 2/1, what happens to the records from 1/1 to 1.31?
I think the only thing that needs to be changed would be to add the sales rep id to the sales record.
Michael L John
If you assassinate a DBA, would you pull a trigger?
To properly post on a forum:
http://www.sqlservercentral.com/articles/61537/ -
Thanks for the response Michael. There are many more attributes in our customer table than just sales rep id. The customer surrogate key s/b the only key in the fact sales table for attributes about a customer. That key will tell us who the customer's sales rep is/was on the day of the sale.
In your example of the sales rep ID changing on 2/1... when the fact sales table is inserted into on 1/31, it will use the surrogate key from the customer dimension that has the 99 salesRepID. the next day, when the dimension is updated there will be a new record in the customer dimension with a new surrogate key because our merge statement will detect the difference. and that record will have the salesRep of 100 for that customer. When inserting to the fact table, we'll insert the new / most recent surrogate key. The historical records stay the same.
-
Thanks for the response Steve Collins.
I wasn't clear in my question. We write the start date of the customer dimension record as a date time, in the example the StartDate is 9.19.2022 17:12, so when we are doing the compare of saleDate >= startDate, it doesn't choose that record because saleDate is 9.19.2022 00:00.
Perhaps I should have asked this:
When inserting a new Type 2 dimension record, should one use a date time for StartDate / EndDate columns? or a date?If a date time, do you set it to the beginning of the day or keep the time in there? I realize this is situational, I'm looking to hear how others handle those start and end columns in dimensions. Given our requirements for this specific need, it needs to be a date, and according to Kimball's data warehouse toolkit either is OK:
- jmetape wrote:
Thanks for the response Michael. There are many more attributes in our customer table than just sales rep id. The customer surrogate key s/b the only key in the fact sales table for attributes about a customer. That key will tell us who the customer's sales rep is/was on the day of the sale.
In your example of the sales rep ID changing on 2/1... when the fact sales table is inserted into on 1/31, it will use the surrogate key from the customer dimension that has the 99 salesRepID. the next day, when the dimension is updated there will be a new record in the customer dimension with a new surrogate key because our merge statement will detect the difference. and that record will have the salesRep of 100 for that customer. When inserting to the fact table, we'll insert the new / most recent surrogate key. The historical records stay the same.
Yeah,. I figured I had it half right.
Michael L John
If you assassinate a DBA, would you pull a trigger?
To properly post on a forum:
http://www.sqlservercentral.com/articles/61537/ -
Hi, We figured out how we are going to handle this-- keep the StartDate / EndDate as a datetime and change the values to the beginning of the day meaning -- "2022-11-02 02:31:57.337" becomes "2022-11-02 00:00:00.000".

Viewing 7 posts - 1 through 7 (of 7 total)
You must be logged in to reply to this topic. Login to reply